Prototype: Data Source V2 #9
Closed
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…ash aggregate ## What changes were proposed in this pull request? In apache#18483 , we fixed the data copy bug when saving into `InternalRow`, and removed all workarounds for this bug in the aggregate code path. However, the object hash aggregate was missed, this PR fixes it. This patch is also a requirement for apache#17419 , which shows that DataFrame version is slower than RDD version because of this issue. ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes apache#18712 from cloud-fan/minor.
## What changes were proposed in this pull request? With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key. We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix. The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'. We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID. This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use. ## How was this patch tested? This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior. Initial retry of the driver, driver in pending state:  Driver re-launched: 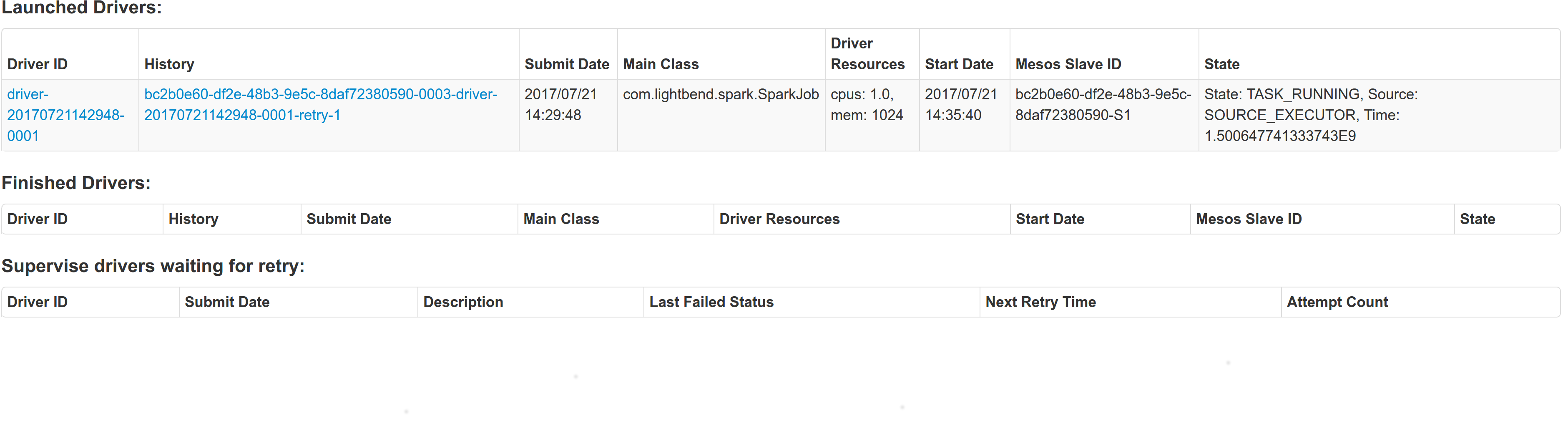 Another re-try:  The resulted entries in history server at the bottom: 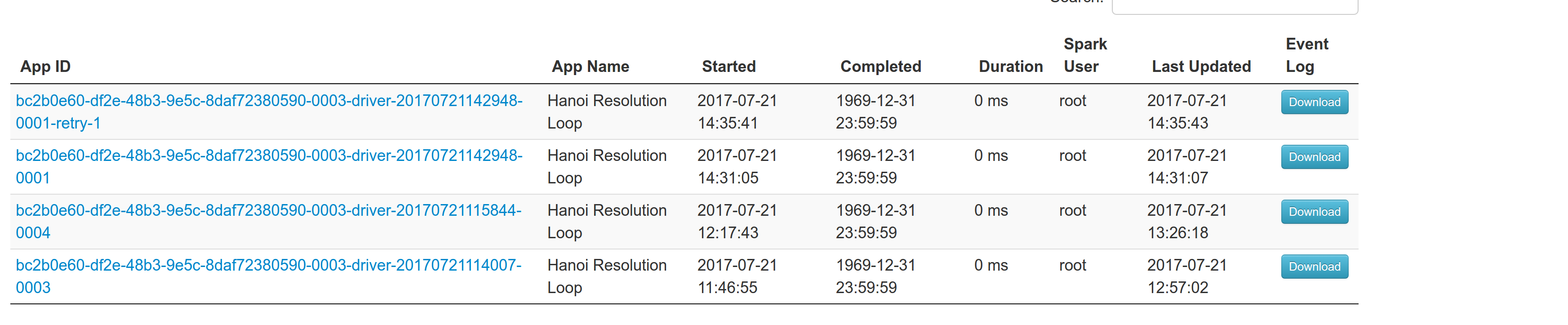 Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:  Author: Stavros Kontopoulos <[email protected]> Closes apache#18705 from skonto/fix_supervise_flag.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…must call super.afterEach() ## What changes were proposed in this pull request? This PR ensures to call `super.afterEach()` in overriding `afterEach()` method in `DatasetCacheSuite`. When we override `afterEach()` method in Testsuite, we have to call `super.afterEach()`. This is a follow-up of apache#18719 and SPARK-21512. ## How was this patch tested? Used the existing test suite Author: Kazuaki Ishizaki <[email protected]> Closes apache#18721 from kiszk/SPARK-21516.
… KinesisInputDStream builder instead of deprecated KinesisUtils ## What changes were proposed in this pull request? The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams. ## How was this patch tested? The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested. Author: Yash Sharma <[email protected]> Closes apache#18071 from yssharma/ysharma/kinesis_docs.
I find a bug about 'quick start',and created a new issues,Sean Owen let me to make a pull request, and I do ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Trueman <[email protected]> Author: lizhaoch <[email protected]> Closes apache#18722 from lizhaoch/master.
## What changes were proposed in this pull request? A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service. apache@93dd0c5 and apache@85c6ce6 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read. ## How was this patch tested? Added unit test. Author: jinxing <[email protected]> Closes apache#18388 from jinxing64/SPARK-21175.
When NodeManagers launching Executors, the `missing` value will exceed the real value when the launch is slow, this can lead to YARN allocates more resource. We add the `numExecutorsRunning` when calculate the `missing` to avoid this. Test by experiment. Author: DjvuLee <[email protected]> Closes apache#18651 from djvulee/YarnAllocate.
inprogress history file in some cases. Add failure handling for EOFException that can be thrown during decompression of an inprogress spark history file, treat same as case where can't parse the last line. ## What changes were proposed in this pull request? Failure handling for case of EOFException thrown within the ReplayListenerBus.replay method to handle the case analogous to json parse fail case. This path can arise in compressed inprogress history files since an incomplete compression block could be read (not flushed by writer on a block boundary). See the stack trace of this occurrence in the jira ticket (https://issues.apache.org/jira/browse/SPARK-21447) ## How was this patch tested? Added a unit test that specifically targets validating the failure handling path appropriately when maybeTruncated is true and false. Author: Eric Vandenberg <[email protected]> Closes apache#18673 from ericvandenbergfb/fix_inprogress_compr_history_file.
… .toMap ## What changes were proposed in this pull request? `Traversable.toMap` changed to 'collections.breakOut', that eliminates intermediate tuple collection creation, see [Stack Overflow article](https://stackoverflow.com/questions/1715681/scala-2-8-breakout). ## How was this patch tested? Unit tests run. No performance tests performed yet. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: iurii.ant <[email protected]> Closes apache#18693 from SereneAnt/performance_toMap-breakOut.
### What changes were proposed in this pull request? Like [Hive UDFType](https://hive.apache.org/javadocs/r2.0.1/api/org/apache/hadoop/hive/ql/udf/UDFType.html), we should allow users to add the extra flags for ScalaUDF and JavaUDF too. _stateful_/_impliesOrder_ are not applicable to our Scala UDF. Thus, we only add the following two flags. - deterministic: Certain optimizations should not be applied if UDF is not deterministic. Deterministic UDF returns same result each time it is invoked with a particular input. This determinism just needs to hold within the context of a query. When the deterministic flag is not correctly set, the results could be wrong. For ScalaUDF in Dataset APIs, users can call the following extra APIs for `UserDefinedFunction` to make the corresponding changes. - `nonDeterministic`: Updates UserDefinedFunction to non-deterministic. Also fixed the Java UDF name loss issue. Will submit a separate PR for `distinctLike` for UDAF ### How was this patch tested? Added test cases for both ScalaUDF Author: gatorsmile <[email protected]> Author: Wenchen Fan <[email protected]> Closes apache#17848 from gatorsmile/udfRegister.
…rnal service. There was some code based on the old SASL handler in the new auth client that was incorrectly using the SASL user as the user to authenticate against the external shuffle service. This caused the external service to not be able to find the correct secret to authenticate the connection, failing the connection. In the course of debugging, I found that some log messages from the YARN shuffle service were a little noisy, so I silenced some of them, and also added a couple of new ones that helped find this issue. On top of that, I found that a check in the code that records app secrets was wrong, causing more log spam and also using an O(n) operation instead of an O(1) call. Also added a new integration suite for the YARN shuffle service with auth on, and verified it failed before, and passes now. Author: Marcelo Vanzin <[email protected]> Closes apache#18706 from vanzin/SPARK-21494.
## What changes were proposed in this pull request?
In our production cluster,oom happens when NettyBlockRpcServer receive OpenBlocks message.The reason we observed is below:
When BlockManagerManagedBuffer call ChunkedByteBuffer#toNetty, it will use Unpooled.wrappedBuffer(ByteBuffer... buffers) which use default maxNumComponents=16 in low-level CompositeByteBuf.When our component's number is bigger than 16, it will execute consolidateIfNeeded
int numComponents = this.components.size();
if(numComponents > this.maxNumComponents) {
int capacity = ((CompositeByteBuf.Component)this.components.get(numComponents - 1)).endOffset;
ByteBuf consolidated = this.allocBuffer(capacity);
for(int c = 0; c < numComponents; ++c) {
CompositeByteBuf.Component c1 = (CompositeByteBuf.Component)this.components.get(c);
ByteBuf b = c1.buf;
consolidated.writeBytes(b);
c1.freeIfNecessary();
}
CompositeByteBuf.Component var7 = new CompositeByteBuf.Component(consolidated);
var7.endOffset = var7.length;
this.components.clear();
this.components.add(var7);
}
in CompositeByteBuf which will consume some memory during buffer copy.
We can use another api Unpooled. wrappedBuffer(int maxNumComponents, ByteBuffer... buffers) to avoid this comsuming.
## How was this patch tested?
Test in production cluster.
Author: zhoukang <[email protected]>
Closes apache#18723 from caneGuy/zhoukang/fix-chunkbuffer.
…s wrong temp files ## What changes were proposed in this pull request? jira: https://issues.apache.org/jira/browse/SPARK-21524 ValidatorParamsSuiteHelpers.testFileMove() is generating temp dir in the wrong place and does not delete them. ValidatorParamsSuiteHelpers.testFileMove() is invoked by TrainValidationSplitSuite and crossValidatorSuite. Currently it uses `tempDir` from `TempDirectory`, which unfortunately is never initialized since the `boforeAll()` of `ValidatorParamsSuiteHelpers` is never invoked. In my system, it leaves some temp directories in the assembly folder each time I run the TrainValidationSplitSuite and crossValidatorSuite. ## How was this patch tested? unit test fix Author: Yuhao Yang <[email protected]> Closes apache#18728 from hhbyyh/tempDirFix.
## What changes were proposed in this pull request? This change pulls the `LogisticAggregator` class out of LogisticRegression.scala and makes it extend `DifferentiableLossAggregator`. It also changes logistic regression to use the generic `RDDLossFunction` instead of having its own. Other minor changes: * L2Regularization accepts `Option[Int => Double]` for features standard deviation * L2Regularization uses `Vector` type instead of Array * Some tests added to LeastSquaresAggregator ## How was this patch tested? Unit test suites are added. Author: sethah <[email protected]> Closes apache#18305 from sethah/SPARK-20988.
…-in functions ## What changes were proposed in this pull request? This generates a documentation for Spark SQL built-in functions. One drawback is, this requires a proper build to generate built-in function list. Once it is built, it only takes few seconds by `sql/create-docs.sh`. Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation. There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up. This requires `pip install mkdocs` to generate HTMLs from markdown files. ## How was this patch tested? Manually tested: ``` cd docs jekyll build ``` , ``` cd docs jekyll serve ``` and ``` cd sql create-docs.sh ``` Author: hyukjinkwon <[email protected]> Closes apache#18702 from HyukjinKwon/SPARK-21485.
…ferred. ## What changes were proposed in this pull request? Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism. Author: jinxing <[email protected]> Closes apache#18735 from jinxing64/SPARK-21530.
## What changes were proposed in this pull request? This PR ensures that `Unsafe.sizeInBytes` must be a multiple of 8. It it is not satisfied. `Unsafe.hashCode` causes the assertion violation. ## How was this patch tested? Will add test cases Author: Kazuaki Ishizaki <[email protected]> Closes apache#18503 from kiszk/SPARK-21271.
…e and StructType support. ## What changes were proposed in this pull request? This is a refactoring of `ArrowConverters` and related classes. 1. Refactor `ColumnWriter` as `ArrowWriter`. 2. Add `ArrayType` and `StructType` support. 3. Refactor `ArrowConverters` to skip intermediate `ArrowRecordBatch` creation. ## How was this patch tested? Added some tests and existing tests. Author: Takuya UESHIN <[email protected]> Closes apache#18655 from ueshin/issues/SPARK-21440.
## What changes were proposed in this pull request? Add R-like summary table to GLM summary, which includes feature name (if exist), parameter estimate, standard error, t-stat and p-value. This allows scala users to easily gather these commonly used inference results. srowen yanboliang felixcheung ## How was this patch tested? New tests. One for testing feature Name, and one for testing the summary Table. Author: actuaryzhang <[email protected]> Author: Wayne Zhang <[email protected]> Author: Yanbo Liang <[email protected]> Closes apache#16630 from actuaryzhang/glmTable.
## What changes were proposed in this pull request? `UnsafeExternalSorter.recordComparator` can be either `KVComparator` or `RowComparator`, and both of them will keep the reference to the input rows they compared last time. After sorting, we return the sorted iterator to upstream operators. However, the upstream operators may take a while to consume up the sorted iterator, and `UnsafeExternalSorter` is registered to `TaskContext` at [here](https://github.com/apache/spark/blob/v2.2.0/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java#L159-L161), which means we will keep the `UnsafeExternalSorter` instance and keep the last compared input rows in memory until the sorted iterator is consumed up. Things get worse if we sort within partitions of a dataset and coalesce all partitions into one, as we will keep a lot of input rows in memory and the time to consume up all the sorted iterators is long. This PR takes over apache#18543 , the idea is that, we do not keep the record comparator instance in `UnsafeExternalSorter`, but a generator of record comparator. close apache#18543 ## How was this patch tested? N/A Author: Wenchen Fan <[email protected]> Closes apache#18679 from cloud-fan/memory-leak.
## What changes were proposed in this pull request?
This PR contains a tiny update that removes an attribute resolution inconsistency in the Dataset API. The following example is taken from the ticket description:
```
spark.range(1).withColumnRenamed("id", "x").sort(col("id")) // works
spark.range(1).withColumnRenamed("id", "x").sort($"id") // works
spark.range(1).withColumnRenamed("id", "x").sort('id) // works
spark.range(1).withColumnRenamed("id", "x").sort("id") // fails with:
org.apache.spark.sql.AnalysisException: Cannot resolve column name "id" among (x);
```
The above `AnalysisException` happens because the last case calls `Dataset.apply()` to convert strings into columns, which triggers attribute resolution. To make the API consistent between overloaded methods, this PR defers the resolution and constructs columns directly.
Author: aokolnychyi <[email protected]>
Closes apache#18740 from aokolnychyi/spark-21538.
## What changes were proposed in this pull request? add `setWeightCol` method for OneVsRest. `weightCol` is ignored if classifier doesn't inherit HasWeightCol trait. ## How was this patch tested? + [x] add an unit test. Author: Yan Facai (颜发才) <[email protected]> Closes apache#18554 from facaiy/BUG/oneVsRest_missing_weightCol.
## What changes were proposed in this pull request? Fixes current failures in dev/lint-java ## How was this patch tested? Existing linter, tests. Author: Sean Owen <[email protected]> Closes apache#18757 from srowen/LintJava.
…f master parameter in the spark-shell When I type spark-shell --help, I find that the default value description for the master parameter is missing. The user does not know what the default value is when the master parameter is not included, so we need to add the master parameter default description to the help information. [https://issues.apache.org/jira/browse/SPARK-21553](https://issues.apache.org/jira/browse/SPARK-21553) Author: davidxdh <[email protected]> Author: Donghui Xu <[email protected]> Closes apache#18755 from davidxdh/dev_0728.
…at does not create SparkContext If you run a spark job without creating the SparkSession or SparkContext, the spark job logs says it succeeded but yarn says it fails and retries 3 times. Also, since, Application Master unregisters with Resource Manager and exits successfully, it deletes the spark staging directory, so when yarn makes subsequent retries, it fails to find the staging directory and thus, the retries fail. Added a flag to check whether user has initialized SparkContext. If it is true, we let Application Master unregister with Resource Manager else, we do not let AM unregister with RM. ## How was this patch tested? Manually tested the fix. Before: <img width="1253" alt="screen shot-before" src="https://user-images.githubusercontent.com/22228190/28647214-69bf81e2-722b-11e7-9ed0-d416d2bf23be.png"> After: <img width="1319" alt="screen shot-after" src="https://user-images.githubusercontent.com/22228190/28647220-70f9eea2-722b-11e7-85c6-e56276b15614.png"> Please review http://spark.apache.org/contributing.html before opening a pull request. Author: pgandhi <[email protected]> Author: pgandhi999 <[email protected]> Closes apache#18741 from pgandhi999/SPARK-21541.
{kind=link}
{kind=link}
- Author: Johan Grande <[email protected]> Closes apache#18738 from nahoj/patch-1.
## What changes were proposed in this pull request?
This PR proposes `StructType.fieldNames` that returns a copy of a field name list rather than a (undocumented) `StructType.names`.
There are two points here:
- API consistency with Scala/Java
- Provide a safe way to get the field names. Manipulating these might cause unexpected behaviour as below:
```python
from pyspark.sql.types import *
struct = StructType([StructField("f1", StringType(), True)])
names = struct.names
del names[0]
spark.createDataFrame([{"f1": 1}], struct).show()
```
```
...
java.lang.IllegalStateException: Input row doesn't have expected number of values required by the schema. 1 fields are required while 0 values are provided.
at org.apache.spark.sql.execution.python.EvaluatePython$.fromJava(EvaluatePython.scala:138)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741)
...
```
## How was this patch tested?
Added tests in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <[email protected]>
Closes apache#18618 from HyukjinKwon/SPARK-20090.
…entation ## What changes were proposed in this pull request? JIRA ticket : [SPARK-21508](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-21508) correcting a mistake in example code provided in Spark Streaming Custom Receivers Documentation The example code provided in the documentation on 'Spark Streaming Custom Receivers' has an error. doc link : https://spark.apache.org/docs/latest/streaming-custom-receivers.html ``` // Assuming ssc is the StreamingContext val customReceiverStream = ssc.receiverStream(new CustomReceiver(host, port)) val words = lines.flatMap(_.split(" ")) ... ``` instead of `lines.flatMap(_.split(" "))` it should be `customReceiverStream.flatMap(_.split(" "))` ## How was this patch tested? this documentation change is tested manually by jekyll build , running below commands ``` jekyll build jekyll serve --watch ``` screen-shots provided below   Author: Remis Haroon <[email protected]> Closes apache#18770 from remisharoon/master.
{kind=link}
{kind=link}
## What changes were proposed in this pull request?
```DStreams
class FileInputDStream
[line 162] protected[streaming] override def clearMetadata(time: Time) {
batchTimeToSelectedFiles.synchronized {
val oldFiles = batchTimeToSelectedFiles.filter(_._1 < (time - rememberDuration))
batchTimeToSelectedFiles --= oldFiles.keys
```
The above code does not remove the old generatedRDDs. "super.clearMetadata(time)" was added to the beginning of clearMetadata to remove the old generatedRDDs.
## How was this patch tested?
At the end of clearMetadata, the testing code (print the number of generatedRDDs) was added to check the old RDDS were removed manually.
Author: shaofei007 <[email protected]>
Author: Fei Shao <[email protected]>
Closes apache#18718 from shaofei007/master.
… by its canonicalized child ## What changes were proposed in this pull request? When there are aliases (these aliases were added for nested fields) as parameters in `RuntimeReplaceable`, as they are not in the children expression, those aliases can't be cleaned up in analyzer rule `CleanupAliases`. An expression `nvl(foo.foo1, "value")` can be resolved to two semantically different expressions in a group by query because they contain different aliases. Because those aliases are not children of `RuntimeReplaceable` which is an `UnaryExpression`. So we can't trim the aliases out by simple transforming the expressions in `CleanupAliases`. If we want to replace the non-children aliases in `RuntimeReplaceable`, we need to add more codes to `RuntimeReplaceable` and modify all expressions of `RuntimeReplaceable`. It makes the interface ugly IMO. Consider those aliases will be replaced later at optimization and so they're no harm, this patch chooses to simply override `canonicalized` of `RuntimeReplaceable`. One concern is about `CleanupAliases`. Because it actually cannot clean up ALL aliases inside a plan. To make caller of this rule notice that, this patch adds a comment to `CleanupAliases`. ## How was this patch tested? Added test. Author: Liang-Chi Hsieh <[email protected]> Closes apache#18761 from viirya/SPARK-21555.
…ted result projection before using it ## What changes were proposed in this pull request? Recently, we have also encountered such NPE issues in our production environment as described in: https://issues.apache.org/jira/browse/SPARK-19471 This issue can be reproduced by the following examples: ` val df = spark.createDataFrame(Seq(("1", 1), ("1", 2), ("2", 3), ("2", 4))).toDF("x", "y") //HashAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false df.groupBy("x").agg(rand(),sum("y")).show() //ObjectHashAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false df.groupBy("x").agg(rand(),collect_list("y")).show() //SortAggregate, SQLConf.WHOLESTAGE_CODEGEN_ENABLED.key=false &&SQLConf.USE_OBJECT_HASH_AGG.key=false df.groupBy("x").agg(rand(),collect_list("y")).show()` ` This PR is based on PR-16820(apache#16820) with test cases for all aggregation paths. We want to push it forward. > When AggregationIterator generates result projection, it does not call the initialize method of the Projection class. This will cause a runtime NullPointerException when the projection involves nondeterministic expressions. ## How was this patch tested? unit test verified in production environment Author: donnyzone <[email protected]> Closes apache#18920 from DonnyZone/Branch-spark-19471.
…pshot files ## What changes were proposed in this pull request? Directly writing a snapshot file may generate a partial file. This PR changes it to write to a temp file then rename to the target file. ## How was this patch tested? Jenkins. Author: Shixiong Zhu <[email protected]> Closes apache#18928 from zsxwing/SPARK-21696.
… successfully removed ## What changes were proposed in this pull request? We put staging path to delete into the deleteOnExit cache of `FileSystem` in case of the path can't be successfully removed. But when we successfully remove the path, we don't remove it from the cache. We should do it to avoid continuing grow the cache size. ## How was this patch tested? Added a test. Author: Liang-Chi Hsieh <[email protected]> Closes apache#18934 from viirya/SPARK-21721.
…f date functions ## What changes were proposed in this pull request? This PR adds `since` annotation in documentation so that this can be rendered as below: <img width="290" alt="2017-08-14 6 54 26" src="https://user-images.githubusercontent.com/6477701/29267050-034c1f64-8122-11e7-862b-7dfc38e292bf.png"> ## How was this patch tested? Manually checked the documentation by `cd sql && ./create-docs.sh`. Also, Jenkins tests are required. Author: hyukjinkwon <[email protected]> Closes apache#18939 from HyukjinKwon/add-sinces-date-functions.
{kind=link}
## What changes were proposed in this pull request? This PR changes the codes to lazily init hive metastore client so that we can create SparkSession without talking to the hive metastore sever. It's pretty helpful when you set a hive metastore server but it's down. You can still start the Spark shell to debug. ## How was this patch tested? The new unit test. Author: Shixiong Zhu <[email protected]> Closes apache#18944 from zsxwing/hive-lazy-init.
…ted result projection before using it ## What changes were proposed in this pull request? This is a follow-up PR that moves the test case in PR-18920 (apache#18920) to DataFrameAggregateSuit. ## How was this patch tested? unit test Author: donnyzone <[email protected]> Closes apache#18946 from DonnyZone/branch-19471-followingPR.
…hema in table properties ## What changes were proposed in this pull request? This is a follow-up of apache#15900 , to fix one more bug: When table schema is empty and need to be inferred at runtime, we should not resolve parent plans before the schema has been inferred, or the parent plans will be resolved against an empty schema and may get wrong result for something like `select *` The fix logic is: introduce `UnresolvedCatalogRelation` as a placeholder. Then we replace it with `LogicalRelation` or `HiveTableRelation` during analysis, so that it's guaranteed that we won't resolve parent plans until the schema has been inferred. ## How was this patch tested? regression test Author: Wenchen Fan <[email protected]> Closes apache#18907 from cloud-fan/bug.
Currently the launcher handle does not monitor the child spark-submit process it launches; this means that if the child exits with an error, the handle's state will never change, and an application will not know that the application has failed. This change adds code to monitor the child process, and changes the handle state appropriately when the child process exits. Tested with added unit tests. Author: Marcelo Vanzin <[email protected]> Closes apache#18877 from vanzin/SPARK-17742.
This version fixes a few issues in the import order checker; it provides better error messages, and detects more improper ordering (thus the need to change a lot of files in this patch). The main fix is that it correctly complains about the order of packages vs. classes. As part of the above, I moved some "SparkSession" import in ML examples inside the "$example on$" blocks; that didn't seem consistent across different source files to start with, and avoids having to add more on/off blocks around specific imports. The new scalastyle also seems to have a better header detector, so a few license headers had to be updated to match the expected indentation. Author: Marcelo Vanzin <[email protected]> Closes apache#18943 from vanzin/SPARK-21731.
## What changes were proposed in this pull request? The method name `asNonNullabe` should be `asNonNullable`. ## How was this patch tested? N/A Author: Xingbo Jiang <[email protected]> Closes apache#18952 from jiangxb1987/typo.
Proposed changes:
* Clarify the type error that `Column.substr()` gives.
Test plan:
* Tested this manually.
* Test code:
```python
from pyspark.sql.functions import col, lit
spark.createDataFrame([['nick']], schema=['name']).select(col('name').substr(0, lit(1)))
```
* Before:
```
TypeError: Can not mix the type
```
* After:
```
TypeError: startPos and length must be the same type. Got <class 'int'> and
<class 'pyspark.sql.column.Column'>, respectively.
```
Author: Nicholas Chammas <[email protected]>
Closes apache#18926 from nchammas/SPARK-21712-substr-type-error.
## What changes were proposed in this pull request? This patch adds the DataFrames API to the multivariate summarizer (mean, variance, etc.). In addition to all the features of MultivariateOnlineSummarizer, it also allows the user to select a subset of the metrics. ## How was this patch tested? Testcases added. ## Performance Resolve several performance issues in apache#17419, further optimization pending on SQL team's work. One of the SQL layer performance issue related to these feature has been resolved in apache#18712, thanks liancheng and cloud-fan ### Performance data (test on my laptop, use 2 partitions. tries out = 20, warm up = 10) The unit of test results is records/milliseconds (higher is better) Vector size/records number | 1/10000000 | 10/1000000 | 100/1000000 | 1000/100000 | 10000/10000 ----|------|----|---|----|---- Dataframe | 15149 | 7441 | 2118 | 224 | 21 RDD from Dataframe | 4992 | 4440 | 2328 | 320 | 33 raw RDD | 53931 | 20683 | 3966 | 528 | 53 Author: WeichenXu <[email protected]> Closes apache#18798 from WeichenXu123/SPARK-19634-dataframe-summarizer.
## What changes were proposed in this pull request? Like Parquet, this PR aims to depend on the latest Apache ORC 1.4 for Apache Spark 2.3. There are key benefits for Apache ORC 1.4. - Stability: Apache ORC 1.4.0 has many fixes and we can depend on ORC community more. - Maintainability: Reduce the Hive dependency and can remove old legacy code later. Later, we can get the following two key benefits by adding new ORCFileFormat in SPARK-20728 (apache#17980), too. - Usability: User can use ORC data sources without hive module, i.e, -Phive. - Speed: Use both Spark ColumnarBatch and ORC RowBatch together. This will be faster than the current implementation in Spark. ## How was this patch tested? Pass the jenkins. Author: Dongjoon Hyun <[email protected]> Closes apache#18640 from dongjoon-hyun/SPARK-21422.
## What changes were proposed in this pull request? Check the option "numFeatures" only when reading LibSVM, not when writing. When writing, Spark was raising an exception. After the change it will ignore the option completely. liancheng HyukjinKwon (Maybe the usage should be forbidden when writing, in a major version change?). ## How was this patch tested? Manual test, that loading and writing LibSVM files work fine, both with and without the numFeatures option. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Jan Vrsovsky <[email protected]> Closes apache#18872 from ProtD/master.
This PR adds a `FeatureHasher` transformer, modeled on [scikit-learn](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.FeatureHasher.html) and [Vowpal wabbit](https://github.com/JohnLangford/vowpal_wabbit/wiki/Feature-Hashing-and-Extraction). The transformer operates on multiple input columns in one pass. Current behavior is: * for numerical columns, the values are assumed to be real values and the feature index is `hash(columnName)` while feature value is `feature_value` * for string columns, the values are assumed to be categorical and the feature index is `hash(column_name=feature_value)`, while feature value is `1.0` * For hash collisions, feature values will be summed * `null` (missing) values are ignored The following dataframe illustrates the basic semantics: ``` +---+------+-----+---------+------+-----------------------------------------+ |int|double|float|stringNum|string|features | +---+------+-----+---------+------+-----------------------------------------+ |3 |4.0 |5.0 |1 |foo |(16,[0,8,11,12,15],[5.0,3.0,1.0,4.0,1.0])| |6 |7.0 |8.0 |2 |bar |(16,[0,8,11,12,15],[8.0,6.0,1.0,7.0,1.0])| +---+------+-----+---------+------+-----------------------------------------+ ``` ## How was this patch tested? New unit tests and manual experiments. Author: Nick Pentreath <[email protected]> Closes apache#18513 from MLnick/FeatureHasher.
…executors when tasks still to run
## What changes were proposed in this pull request?
Right now spark lets go of executors when they are idle for the 60s (or configurable time). I have seen spark let them go when they are idle but they were really needed. I have seen this issue when the scheduler was waiting to get node locality but that takes longer than the default idle timeout. In these jobs the number of executors goes down really small (less than 10) but there are still like 80,000 tasks to run.
We should consider not allowing executors to idle timeout if they are still needed according to the number of tasks to be run.
## How was this patch tested?
Tested by manually adding executors to `executorsIdsToBeRemoved` list and seeing if those executors were removed when there are a lot of tasks and a high `numExecutorsTarget` value.
Code used
In `ExecutorAllocationManager.start()`
```
start_time = clock.getTimeMillis()
```
In `ExecutorAllocationManager.schedule()`
```
val executorIdsToBeRemoved = ArrayBuffer[String]()
if ( now > start_time + 1000 * 60 * 2) {
logInfo("--- REMOVING 1/2 of the EXECUTORS ---")
start_time += 1000 * 60 * 100
var counter = 0
for (x <- executorIds) {
counter += 1
if (counter == 2) {
counter = 0
executorIdsToBeRemoved += x
}
}
}
Author: John Lee <[email protected]>
Closes apache#18874 from yoonlee95/SPARK-21656.
…at is closed when the function is too long
## What changes were proposed in this pull request?
Close the whole stage codegen when the function lines is longer than the maxlines which will be setted by
spark.sql.codegen.MaxFunctionLength parameter, because when the function is too long , it will not get the JIT optimizing.
A benchmark test result is 10x slower when the generated function is too long :
ignore("max function length of wholestagecodegen") {
val N = 20 << 15
val benchmark = new Benchmark("max function length of wholestagecodegen", N)
def f(): Unit = sparkSession.range(N)
.selectExpr(
"id",
"(id & 1023) as k1",
"cast(id & 1023 as double) as k2",
"cast(id & 1023 as int) as k3",
"case when id > 100 and id <= 200 then 1 else 0 end as v1",
"case when id > 200 and id <= 300 then 1 else 0 end as v2",
"case when id > 300 and id <= 400 then 1 else 0 end as v3",
"case when id > 400 and id <= 500 then 1 else 0 end as v4",
"case when id > 500 and id <= 600 then 1 else 0 end as v5",
"case when id > 600 and id <= 700 then 1 else 0 end as v6",
"case when id > 700 and id <= 800 then 1 else 0 end as v7",
"case when id > 800 and id <= 900 then 1 else 0 end as v8",
"case when id > 900 and id <= 1000 then 1 else 0 end as v9",
"case when id > 1000 and id <= 1100 then 1 else 0 end as v10",
"case when id > 1100 and id <= 1200 then 1 else 0 end as v11",
"case when id > 1200 and id <= 1300 then 1 else 0 end as v12",
"case when id > 1300 and id <= 1400 then 1 else 0 end as v13",
"case when id > 1400 and id <= 1500 then 1 else 0 end as v14",
"case when id > 1500 and id <= 1600 then 1 else 0 end as v15",
"case when id > 1600 and id <= 1700 then 1 else 0 end as v16",
"case when id > 1700 and id <= 1800 then 1 else 0 end as v17",
"case when id > 1800 and id <= 1900 then 1 else 0 end as v18")
.groupBy("k1", "k2", "k3")
.sum()
.collect()
benchmark.addCase(s"codegen = F") { iter =>
sparkSession.conf.set("spark.sql.codegen.wholeStage", "false")
f()
}
benchmark.addCase(s"codegen = T") { iter =>
sparkSession.conf.set("spark.sql.codegen.wholeStage", "true")
sparkSession.conf.set("spark.sql.codegen.MaxFunctionLength", "10000")
f()
}
benchmark.run()
/*
Java HotSpot(TM) 64-Bit Server VM 1.8.0_111-b14 on Windows 7 6.1
Intel64 Family 6 Model 58 Stepping 9, GenuineIntel
max function length of wholestagecodegen: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------
codegen = F 443 / 507 1.5 676.0 1.0X
codegen = T 3279 / 3283 0.2 5002.6 0.1X
*/
}
## How was this patch tested?
Run the unit test
Author: 10129659 <[email protected]>
Closes apache#18810 from eatoncys/codegen.
## What changes were proposed in this pull request? When a session is closed the Thriftserver doesn't cancel the jobs which may still be running. This is a huge waste of resources. This PR address the problem canceling the pending jobs when a session is closed. ## How was this patch tested? The patch was tested manually. Author: Marco Gaido <[email protected]> Closes apache#18951 from mgaido91/SPARK-21738.
## What changes were proposed in this pull request? When use Vector.compressed to change a Vector to SparseVector, the performance is very low comparing with Vector.toSparse. This is because you have to scan the value three times using Vector.compressed, but you just need two times when use Vector.toSparse. When the length of the vector is large, there is significant performance difference between this two method. ## How was this patch tested? The existing UT Author: Peng Meng <[email protected]> Closes apache#18899 from mpjlu/optVectorCompress.
… than 2GB ## What changes were proposed in this pull request? introduced `DiskBlockData`, a new implementation of `BlockData` representing a whole file. this is somehow related to [SPARK-6236](https://issues.apache.org/jira/browse/SPARK-6236) as well This class follows the implementation of `EncryptedBlockData` just without the encryption. hence: * `toInputStream` is implemented using a `FileInputStream` (todo: encrypted version actually uses `Channels.newInputStream`, not sure if it's the right choice for this) * `toNetty` is implemented in terms of `io.netty.channel.DefaultFileRegion` * `toByteBuffer` fails for files larger than 2GB (same behavior of the original code, just postponed a bit), it also respects the same configuration keys defined by the original code to choose between memory mapping and simple file read. ## How was this patch tested? added test to DiskStoreSuite and MemoryManagerSuite Author: Eyal Farago <[email protected]> Closes apache#18855 from eyalfa/SPARK-3151.
## What changes were proposed in this pull request? For top-most limit, we will use a special operator to execute it: `CollectLimitExec`. `CollectLimitExec` will retrieve `n`(which is the limit) rows from each partition of the child plan output, see https://github.com/apache/spark/blob/v2.2.0/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala#L311. It's very likely that we don't exhaust the child plan output. This is fine when whole-stage-codegen is off, as child plan will release the resource via task completion listener. However, when whole-stage codegen is on, the resource can only be released if all output is consumed. To fix this memory leak, one simple approach is, when `CollectLimitExec` retrieve `n` rows from child plan output, child plan output should only have `n` rows, then the output is exhausted and resource is released. This can be done by wrapping child plan with `LocalLimit` ## How was this patch tested? a regression test Author: Wenchen Fan <[email protected]> Closes apache#18955 from cloud-fan/leak.
cloud-fan
pushed a commit
that referenced
this pull request
Dec 30, 2019
### Why are the changes needed? `EnsureRequirements` adds `ShuffleExchangeExec` (RangePartitioning) after Sort if `RoundRobinPartitioning` behinds it. This will cause 2 shuffles, and the number of partitions in the final stage is not the number specified by `RoundRobinPartitioning. **Example SQL** ``` SELECT /*+ REPARTITION(5) */ * FROM test ORDER BY a ``` **BEFORE** ``` == Physical Plan == *(1) Sort [a#0 ASC NULLS FIRST], true, 0 +- Exchange rangepartitioning(a#0 ASC NULLS FIRST, 200), true, [id=#11] +- Exchange RoundRobinPartitioning(5), false, [id=#9] +- Scan hive default.test [a#0, b#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [a#0, b#1] ``` **AFTER** ``` == Physical Plan == *(1) Sort [a#0 ASC NULLS FIRST], true, 0 +- Exchange rangepartitioning(a#0 ASC NULLS FIRST, 5), true, [id=#11] +- Scan hive default.test [a#0, b#1], HiveTableRelation `default`.`test`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [a#0, b#1] ``` ### Does this PR introduce any user-facing change? No ### How was this patch tested? Run suite Tests and add new test for this. Closes apache#26946 from stczwd/RoundRobinPartitioning. Lead-authored-by: lijunqing <[email protected]> Co-authored-by: stczwd <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
cloud-fan
pushed a commit
that referenced
this pull request
Feb 27, 2024
…n properly
### What changes were proposed in this pull request?
Make `ResolveRelations` handle plan id properly
### Why are the changes needed?
bug fix for Spark Connect, it won't affect classic Spark SQL
before this PR:
```
from pyspark.sql import functions as sf
spark.range(10).withColumn("value_1", sf.lit(1)).write.saveAsTable("test_table_1")
spark.range(10).withColumnRenamed("id", "index").withColumn("value_2", sf.lit(2)).write.saveAsTable("test_table_2")
df1 = spark.read.table("test_table_1")
df2 = spark.read.table("test_table_2")
df3 = spark.read.table("test_table_1")
join1 = df1.join(df2, on=df1.id==df2.index).select(df2.index, df2.value_2)
join2 = df3.join(join1, how="left", on=join1.index==df3.id)
join2.schema
```
fails with
```
AnalysisException: [CANNOT_RESOLVE_DATAFRAME_COLUMN] Cannot resolve dataframe column "id". It's probably because of illegal references like `df1.select(df2.col("a"))`. SQLSTATE: 42704
```
That is due to existing plan caching in `ResolveRelations` doesn't work with Spark Connect
```
=== Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations ===
'[#12]Join LeftOuter, '`==`('index, 'id) '[#12]Join LeftOuter, '`==`('index, 'id)
!:- '[#9]UnresolvedRelation [test_table_1], [], false :- '[#9]SubqueryAlias spark_catalog.default.test_table_1
!+- '[#11]Project ['index, 'value_2] : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
! +- '[#10]Join Inner, '`==`('id, 'index) +- '[#11]Project ['index, 'value_2]
! :- '[#7]UnresolvedRelation [test_table_1], [], false +- '[#10]Join Inner, '`==`('id, 'index)
! +- '[#8]UnresolvedRelation [test_table_2], [], false :- '[#9]SubqueryAlias spark_catalog.default.test_table_1
! : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
! +- '[#8]SubqueryAlias spark_catalog.default.test_table_2
! +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_2`, [], false
Can not resolve 'id with plan 7
```
`[#7]UnresolvedRelation [test_table_1], [], false` was wrongly resolved to the cached one
```
:- '[#9]SubqueryAlias spark_catalog.default.test_table_1
+- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false
```
### Does this PR introduce _any_ user-facing change?
yes, bug fix
### How was this patch tested?
added ut
### Was this patch authored or co-authored using generative AI tooling?
ci
Closes apache#45214 from zhengruifeng/connect_fix_read_join.
Authored-by: Ruifeng Zheng <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
cloud-fan
pushed a commit
that referenced
this pull request
May 7, 2024
…plan properly ### What changes were proposed in this pull request? Make `ResolveRelations` handle plan id properly cherry-pick bugfix apache#45214 to 3.5 ### Why are the changes needed? bug fix for Spark Connect, it won't affect classic Spark SQL before this PR: ``` from pyspark.sql import functions as sf spark.range(10).withColumn("value_1", sf.lit(1)).write.saveAsTable("test_table_1") spark.range(10).withColumnRenamed("id", "index").withColumn("value_2", sf.lit(2)).write.saveAsTable("test_table_2") df1 = spark.read.table("test_table_1") df2 = spark.read.table("test_table_2") df3 = spark.read.table("test_table_1") join1 = df1.join(df2, on=df1.id==df2.index).select(df2.index, df2.value_2) join2 = df3.join(join1, how="left", on=join1.index==df3.id) join2.schema ``` fails with ``` AnalysisException: [CANNOT_RESOLVE_DATAFRAME_COLUMN] Cannot resolve dataframe column "id". It's probably because of illegal references like `df1.select(df2.col("a"))`. SQLSTATE: 42704 ``` That is due to existing plan caching in `ResolveRelations` doesn't work with Spark Connect ``` === Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations === '[#12]Join LeftOuter, '`==`('index, 'id) '[#12]Join LeftOuter, '`==`('index, 'id) !:- '[#9]UnresolvedRelation [test_table_1], [], false :- '[#9]SubqueryAlias spark_catalog.default.test_table_1 !+- '[#11]Project ['index, 'value_2] : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false ! +- '[#10]Join Inner, '`==`('id, 'index) +- '[#11]Project ['index, 'value_2] ! :- '[#7]UnresolvedRelation [test_table_1], [], false +- '[#10]Join Inner, '`==`('id, 'index) ! +- '[#8]UnresolvedRelation [test_table_2], [], false :- '[#9]SubqueryAlias spark_catalog.default.test_table_1 ! : +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false ! +- '[#8]SubqueryAlias spark_catalog.default.test_table_2 ! +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_2`, [], false Can not resolve 'id with plan 7 ``` `[#7]UnresolvedRelation [test_table_1], [], false` was wrongly resolved to the cached one ``` :- '[#9]SubqueryAlias spark_catalog.default.test_table_1 +- 'UnresolvedCatalogRelation `spark_catalog`.`default`.`test_table_1`, [], false ``` ### Does this PR introduce _any_ user-facing change? yes, bug fix ### How was this patch tested? added ut ### Was this patch authored or co-authored using generative AI tooling? ci Closes apache#46291 from zhengruifeng/connect_fix_read_join_35. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
cloud-fan
pushed a commit
that referenced
this pull request
Nov 26, 2025
### What changes were proposed in this pull request? This PR proposes to add `doCanonicalize` function for DataSourceV2ScanRelation. The implementation is similar to [the one in BatchScanExec](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala#L150), as well as the [the one in LogicalRelation](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/LogicalRelation.scala#L52). ### Why are the changes needed? Query optimization rules such as MergeScalarSubqueries check if two plans are identical by [comparing their canonicalized form](https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/MergeScalarSubqueries.scala#L219). For DSv2, for physical plan, the canonicalization goes down in the child hierarchy to the BatchScanExec, which [has a doCanonicalize function](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/BatchScanExec.scala#L150); for logical plan, the canonicalization goes down to the DataSourceV2ScanRelation, which, however, does not have a doCanonicalize function. As a result, two logical plans who are semantically identical are not identified. Moreover, for reference, [DSv1 LogicalRelation](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/LogicalRelation.scala#L52) also has `doCanonicalize()`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A new unit test is added to show that `MergeScalarSubqueries` is working for DataSourceV2ScanRelation. For a query ```sql select (select max(i) from df) as max_i, (select min(i) from df) as min_i ``` Before introducing the canonicalization, the plan is ``` == Parsed Logical Plan == 'Project [scalar-subquery#2 [] AS max_i#3, scalar-subquery#4 [] AS min_i#5] : :- 'Project [unresolvedalias('max('i))] : : +- 'UnresolvedRelation [df], [], false : +- 'Project [unresolvedalias('min('i))] : +- 'UnresolvedRelation [df], [], false +- OneRowRelation == Analyzed Logical Plan == max_i: int, min_i: int Project [scalar-subquery#2 [] AS max_i#3, scalar-subquery#4 [] AS min_i#5] : :- Aggregate [max(i#0) AS max(i)#7] : : +- SubqueryAlias df : : +- View (`df`, [i#0, j#1]) : : +- RelationV2[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 : +- Aggregate [min(i#10) AS min(i)#9] : +- SubqueryAlias df : +- View (`df`, [i#10, j#11]) : +- RelationV2[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 +- OneRowRelation == Optimized Logical Plan == Project [scalar-subquery#2 [] AS max_i#3, scalar-subquery#4 [] AS min_i#5] : :- Aggregate [max(i#0) AS max(i)#7] : : +- Project [i#0] : : +- RelationV2[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 : +- Aggregate [min(i#10) AS min(i)#9] : +- Project [i#10] : +- RelationV2[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 +- OneRowRelation == Physical Plan == AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 0 +- *(1) Project [Subquery subquery#2, [id=apache#32] AS max_i#3, Subquery subquery#4, [id=apache#33] AS min_i#5] : :- Subquery subquery#2, [id=apache#32] : : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) HashAggregate(keys=[], functions=[max(i#0)], output=[max(i)#7]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=58] +- *(1) HashAggregate(keys=[], functions=[partial_max(i#0)], output=[max#14]) +- *(1) Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == HashAggregate(keys=[], functions=[max(i#0)], output=[max(i)#7]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=19] +- HashAggregate(keys=[], functions=[partial_max(i#0)], output=[max#14]) +- Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] : +- Subquery subquery#4, [id=apache#33] : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) HashAggregate(keys=[], functions=[min(i#10)], output=[min(i)#9]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=63] +- *(1) HashAggregate(keys=[], functions=[partial_min(i#10)], output=[min#15]) +- *(1) Project [i#10] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == HashAggregate(keys=[], functions=[min(i#10)], output=[min(i)#9]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=30] +- HashAggregate(keys=[], functions=[partial_min(i#10)], output=[min#15]) +- Project [i#10] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- *(1) Scan OneRowRelation[] +- == Initial Plan == Project [Subquery subquery#2, [id=apache#32] AS max_i#3, Subquery subquery#4, [id=apache#33] AS min_i#5] : :- Subquery subquery#2, [id=apache#32] : : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) HashAggregate(keys=[], functions=[max(i#0)], output=[max(i)#7]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=58] +- *(1) HashAggregate(keys=[], functions=[partial_max(i#0)], output=[max#14]) +- *(1) Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == HashAggregate(keys=[], functions=[max(i#0)], output=[max(i)#7]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=19] +- HashAggregate(keys=[], functions=[partial_max(i#0)], output=[max#14]) +- Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] : +- Subquery subquery#4, [id=apache#33] : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) HashAggregate(keys=[], functions=[min(i#10)], output=[min(i)#9]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=63] +- *(1) HashAggregate(keys=[], functions=[partial_min(i#10)], output=[min#15]) +- *(1) Project [i#10] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == HashAggregate(keys=[], functions=[min(i#10)], output=[min(i)#9]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=30] +- HashAggregate(keys=[], functions=[partial_min(i#10)], output=[min#15]) +- Project [i#10] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- Scan OneRowRelation[] ``` After introducing the canonicalization, the plan is as following, where you can see **ReusedSubquery** ``` == Parsed Logical Plan == 'Project [scalar-subquery#2 [] AS max_i#3, scalar-subquery#4 [] AS min_i#5] : :- 'Project [unresolvedalias('max('i))] : : +- 'UnresolvedRelation [df], [], false : +- 'Project [unresolvedalias('min('i))] : +- 'UnresolvedRelation [df], [], false +- OneRowRelation == Analyzed Logical Plan == max_i: int, min_i: int Project [scalar-subquery#2 [] AS max_i#3, scalar-subquery#4 [] AS min_i#5] : :- Aggregate [max(i#0) AS max(i)#7] : : +- SubqueryAlias df : : +- View (`df`, [i#0, j#1]) : : +- RelationV2[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 : +- Aggregate [min(i#10) AS min(i)#9] : +- SubqueryAlias df : +- View (`df`, [i#10, j#11]) : +- RelationV2[i#10, j#11] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 +- OneRowRelation == Optimized Logical Plan == Project [scalar-subquery#2 [].max(i) AS max_i#3, scalar-subquery#4 [].min(i) AS min_i#5] : :- Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] : : +- Aggregate [max(i#0) AS max(i)#7, min(i#0) AS min(i)#9] : : +- Project [i#0] : : +- RelationV2[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 : +- Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] : +- Aggregate [max(i#0) AS max(i)#7, min(i#0) AS min(i)#9] : +- Project [i#0] : +- RelationV2[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5 +- OneRowRelation == Physical Plan == AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 0 +- *(1) Project [Subquery subquery#2, [id=apache#40].max(i) AS max_i#3, ReusedSubquery Subquery subquery#2, [id=apache#40].min(i) AS min_i#5] : :- Subquery subquery#2, [id=apache#40] : : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] +- *(2) HashAggregate(keys=[], functions=[max(i#0), min(i#0)], output=[max(i)#7, min(i)#9]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=71] +- *(1) HashAggregate(keys=[], functions=[partial_max(i#0), partial_min(i#0)], output=[max#16, min#17]) +- *(1) Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] +- HashAggregate(keys=[], functions=[max(i#0), min(i#0)], output=[max(i)#7, min(i)#9]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=22] +- HashAggregate(keys=[], functions=[partial_max(i#0), partial_min(i#0)], output=[max#16, min#17]) +- Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] : +- ReusedSubquery Subquery subquery#2, [id=apache#40] +- *(1) Scan OneRowRelation[] +- == Initial Plan == Project [Subquery subquery#2, [id=apache#40].max(i) AS max_i#3, Subquery subquery#4, [id=apache#41].min(i) AS min_i#5] : :- Subquery subquery#2, [id=apache#40] : : +- AdaptiveSparkPlan isFinalPlan=true +- == Final Plan == ResultQueryStage 1 +- *(2) Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] +- *(2) HashAggregate(keys=[], functions=[max(i#0), min(i#0)], output=[max(i)#7, min(i)#9]) +- ShuffleQueryStage 0 +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=71] +- *(1) HashAggregate(keys=[], functions=[partial_max(i#0), partial_min(i#0)], output=[max#16, min#17]) +- *(1) Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- == Initial Plan == Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] +- HashAggregate(keys=[], functions=[max(i#0), min(i#0)], output=[max(i)#7, min(i)#9]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=22] +- HashAggregate(keys=[], functions=[partial_max(i#0), partial_min(i#0)], output=[max#16, min#17]) +- Project [i#0] +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] : +- Subquery subquery#4, [id=apache#41] : +- AdaptiveSparkPlan isFinalPlan=false : +- Project [named_struct(max(i), max(i)#7, min(i), min(i)#9) AS mergedValue#14] : +- HashAggregate(keys=[], functions=[max(i#0), min(i#0)], output=[max(i)#7, min(i)#9]) : +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=37] : +- HashAggregate(keys=[], functions=[partial_max(i#0), partial_min(i#0)], output=[max#16, min#17]) : +- Project [i#0] : +- BatchScan class org.apache.spark.sql.connector.SimpleDataSourceV2$$anon$5[i#0, j#1] class org.apache.spark.sql.connector.SimpleDataSourceV2$MyScanBuilder RuntimeFilters: [] +- Scan OneRowRelation[] ``` ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#52529 from yhuang-db/scan-canonicalization. Authored-by: yhuang-db <[email protected]> Signed-off-by: Peter Toth <[email protected]>
cloud-fan
pushed a commit
that referenced
this pull request
Nov 26, 2025
…int/Dockerfile` building ### What changes were proposed in this pull request? This PR aims to add `libwebp-dev` to fix `dev/spark-test-image/lint/Dockerfile` building in both `master` and `branch-4.1`. ### Why are the changes needed? Currently, `dev/spark-test-image/lint/Dockerfile` fails to build. - For master branch, it wasn't revealed yet because we use the cached image. - For `branch-4.1`, it is currently breaking the CIs. - https://github.com/apache/spark/tree/branch-4.1 - https://github.com/apache/spark/actions/runs/19015025991/job/54307102990 ``` #9 454.6 -------------------------- [ERROR MESSAGE] --------------------------- #9 454.6 <stdin>:1:10: fatal error: ft2build.h: No such file or directory #9 454.6 compilation terminated. #9 454.6 -------------------------------------------------------------------- #9 454.6 ERROR: configuration failed for package 'ragg' #9 454.6 * removing '/usr/local/lib/R/site-library/ragg' ``` ### Does this PR introduce _any_ user-facing change? No behavior change. ### How was this patch tested? Pass the CIs. Especially, `Base image build` job. - https://github.com/dongjoon-hyun/spark/actions/runs/19018354185/job/54309542386 ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#52838 from dongjoon-hyun/SPARK-54140. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
TODO: