[SPARK-21175] Reject OpenBlocks when memory shortage on shuffle service. #18388
Conversation
|
Test build #78439 has finished for PR 18388 at commit
|
|
Test build #78440 has finished for PR 18388 at commit
|
|
Test build #78455 has finished for PR 18388 at commit
|
|
@cloud-fan @vanzin @tgravescs |
|
Haven't looked at the path in detail yet. High level questions/thoughts. So an alternative to this is limiting the number of blocks each reducer is fetching at once. Instead of calling open blocks with 500 at once, do them in chunks of say 20. We are working on a patch for that and should have it available in the next couple days. This again though doesn't guarantee it but it allows you to throttle down the # of blocks each reducer would get at once. MapReduce/Tez actually do this with a lot of success. |
|
Thanks a lot for quick reply :) Yes, this patch doesn't guarantee avoiding the OOM on shuffle service when all reducers are opening the blocks at the same time. But we can alleviate this by adjusting |
Is it relevant to |
|
I think having both sides would probably be good. limit the reducer connections and simultaneous block calls but have a fail safe on the shuffle server side where it can reject connections also makes sense. Can you please give more details what is using the memory? If its the netty blocks is it when its actually streaming the data back to reducer? I thought it was using direct buffers for that so it wouldn't show up on the heap. I'll have to look in more detail. |
|
cc @jiangxb1987 |
|
Will review this tomorrow. Thanks! |
|
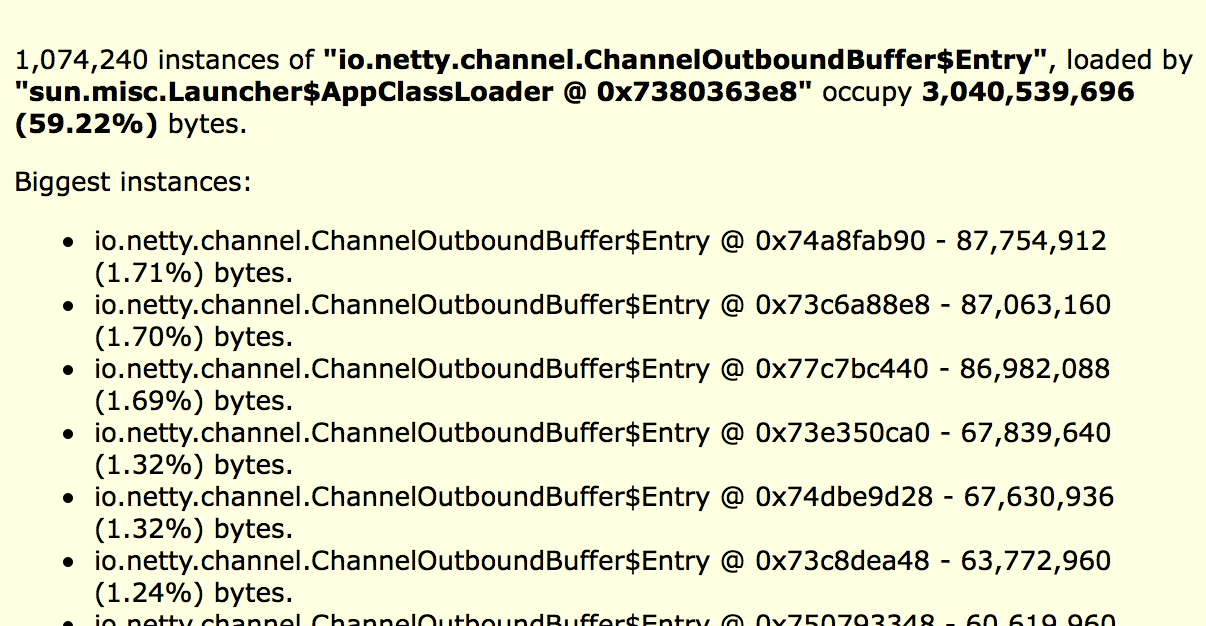
As the screenshot, there are tons of |
 jiangxb1987
left a comment
jiangxb1987
left a comment
There was a problem hiding this comment.
The code quality is pretty good, only have some minor comments.
There was a problem hiding this comment.
Should we move these configs to org.apache.spark.internal.config?
In java, you can use them by:
import org.apache.spark.internal.config.package$;
...
package$.MODULE$.XXX()
There was a problem hiding this comment.
Yes, I do think it's good to put the config into org.apache.spark.internal.config.
But I found it hard. Since org.apache.spark.internal.config in core module. I didn't find a good way to import it from module spark-network-yarn or spark-network-shuffle. Did I miss something ?
There was a problem hiding this comment.
oh, core module relies on spark-network-common, so we don't have to change here.
There was a problem hiding this comment.
This is only for shuffle service. Right? The config should start with spark.shuffle. I'm okey with one config since Netty either uses heap memory or off-heap memory.
There was a problem hiding this comment.
Do we still need this trace?
There was a problem hiding this comment.
I'm not sure, just for debug :)
There was a problem hiding this comment.
What's the purpose of this change?
There was a problem hiding this comment.
MesosExternalShuffleService can use it.
|
@jiangxb1987 |
There was a problem hiding this comment.
nit: it's better to use Iterator pattern here, as the input list may not be an indexed list and list.get(i) becomes O(n).
There was a problem hiding this comment.
do we have a config for shuffle service JVM heap size? maybe we can use that.
There was a problem hiding this comment.
I'm hesitant. Because Netty could use off-heap or on-heap(depends on spark.shuffle.io.preferDirectBufs) for allocating memory.
There was a problem hiding this comment.
This is inconsistent with the executor memory configuration. For executor memory, we have spark.executor.memory for heap size, and spark.memory.offHeap.size for off-heap size, and these 2 together is the total memory consumption for each executor process.
Now we have a single config for shuffle service total memory consumption, this seems better, shall we fix the executor memory config?
There was a problem hiding this comment.
Sorry, you mean:
- the change(
spark.network.netty.memCostWaterMark) in this pr is ok - we merge
spark.executor.memory(heap size) andspark.memory.offHeap.size(off-heap size, used by Tungsten) to be one in executor memory config.
Do I understand correctly ?
There was a problem hiding this comment.
Currently, I do think spark.memory.offHeap.size is quite confusing.
There was a problem hiding this comment.
maybe we can create a JIRA and send it to dev-list to gather feedbacks. Do you mind to do this if you have time?
There was a problem hiding this comment.
Sure, really would love to :)
There was a problem hiding this comment.
@cloud-fan
I made a JIRA(https://issues.apache.org/jira/browse/SPARK-21270) about merging the memory configs. Please take a look when you have time and give some comments.
There was a problem hiding this comment.
shall we merge this and the above log into one log entry?
There was a problem hiding this comment.
nit: this.reason == o.reason?
There was a problem hiding this comment.
can you add some comments to explain the test?
|
LGTM except some minor comments, thanks for working on it! |
|
Test build #78880 has finished for PR 18388 at commit
|
|
Jenkins, retest this please. |
|
Test build #78897 has finished for PR 18388 at commit
|
|
LGTM. Can we add descriptions of these new configs in |
|
Test build #78914 has finished for PR 18388 at commit
|
docs/configuration.md
Outdated
There was a problem hiding this comment.
cc @rxin @JoshRosen @zsxwing any suggestion for the config name?
|
does this patch require server side change for shuffle service? |
|
Yes, there is a change. Server side may return |
|
cc @zsxwing how strictly we require for shuffle service compatibility? |
| channel.close(); | ||
| } | ||
| ManagedBuffer buf; | ||
|
|
|
Test build #79855 has finished for PR 18388 at commit
|
|
Test build #79856 has finished for PR 18388 at commit
|
|
Test build #79857 has finished for PR 18388 at commit
|
|
retest this please |
|
@jinxing64 Sorry, I forgot to mention one request. Could you add a unit test? Right now it's disabled so the new codes are not tested. It will help avoid some obvious mistakes, such as the missing |
|
Test build #79858 has finished for PR 18388 at commit
|
|
Test build #79879 has finished for PR 18388 at commit
|
|
Jenkins, retest this please. |
|
Test build #79886 has finished for PR 18388 at commit
|
|
Test build #79923 has finished for PR 18388 at commit
|
|
thanks, merging to master! |
|
Thanks for merging ! |
|
sorry I didn't get a chance to review this. Started but kept getting distracted by other higher priority things. I think we should expand the description of the config to say what happens when the limit is hit. Since its not using real flow control a user might set this thinking nothing bad will happen, but its dropping connections so could cause failures if the retries don't work. I'll file a separate jira for that. Also what was the issue with implementing the actual flow control part? Was it just adding a queueing type mechanism? We should file a separate jira so we can add that later. |
|
@tgravescs
Could you give the link for the JIRA ? I'm happy to work on a follow-up PR if possible. For the flow control part, I'm just worrying the queue will be too large and causing memory issue. |
|
if it's ok to break shuffle service backward compatibility(by default this config is off), I think we should introduce a new response type to tell the client that, the shuffle service is still up but just in memory shortage, please do not give up and keep trying. Currently we just close the connection, so the client has no idea what's going on and may mistakenly report FetchFailure and fail the stage/job. |
|
its not ok to break the shuffle service backward compatibility though. Especially not in a minor release. We may choose to do it in like a 3.0 but even then it makes upgrading very hard to users. |
|
OK then let's go with the flow control direction.
We can make an external queue, i.e. if it's too large, spill to disk. Another concern is, with flow control, shuffle service may hang a request for a long time, and cause the client to timeout and fail. It's better than just closing the connection, but there is still a chance that the client mistakenly reports FetchFailure. |
|
the idea of the queue is not to queue entire reqeusts, its just to flow contol the # chunks being sent at once. for example you only create 5 outgoing chunks at a time per connection, once one of those has been sent you add another one. This limits the amount of memory being used by those outgoing chunks. This should not affect closing the connection, at least not change it from the current behavior. |
|
oh i see, it's orthogonal to the current approach. Makes sense. |
What changes were proposed in this pull request?
A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBuffer@Entry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service.
93dd0c5 and 85c6ce6 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read.
How was this patch tested?
Added unit test.