Merged
Conversation
…ionHandler and added tests ### What changes were proposed in this pull request? 1) Added missing match case to SparkUncaughtExceptionHandler, so that it would not halt the process when the exception doesn't match any of the match case statements. 2) Added log message before halting process. During debugging it wasn't obvious why the Worker process would DEAD (until we set SPARK_NO_DAEMONIZE=1) due to the shell-scripts puts the process into background and essentially absorbs the exit code. 3) Added SparkUncaughtExceptionHandlerSuite. Basically we create a Spark exception-throwing application with SparkUncaughtExceptionHandler and then check its exit code. ### Why are the changes needed? SPARK-30310, because the process would halt unexpectedly. ### How was this patch tested? All unit tests (mvn test) were ran and OK. Closes #26955 from tinhto-000/uncaught_exception_fix. Authored-by: git <tinto@us.ibm.com> Signed-off-by: Sean Owen <srowen@gmail.com>
…tion in Web UI ### What changes were proposed in this pull request? SPARK-29894 provides information on the Codegen Stage Id in WEBUI for SQL Plan graphs. Similarly, this proposes to add Codegen Stage Id in the DAG visualization for Stage execution. DAGs for Stage execution are available in the WEBUI under the Jobs and Stages tabs. ### Why are the changes needed? This is proposed as an aid for drill-down analysis of complex SQL statement execution, as it is not always easy to match parts of the SQL Plan graph with the corresponding Stage DAG execution graph. Adding Codegen Stage Id for WholeStageCodegen operations makes this task easier. ### Does this PR introduce any user-facing change? Stage DAG visualization in the WEBUI will show codegen stage id for WholeStageCodegen operations, as in the example snippet from the WEBUI, Jobs tab (the query used in the example is TPCDS 2.4 q14a):  ### How was this patch tested? Manually tested, see also example snippet. Closes #26675 from LucaCanali/addCodegenStageIdtoStageGraph. Authored-by: Luca Canali <luca.canali@cern.ch> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
The default value for backLog set back to -1, as any other value may break existing configuration by overriding Netty's default io.netty.util.NetUtil#SOMAXCONN. The documentation accordingly adjusted. See discussion thread: #24732 ### What changes were proposed in this pull request? Partial rollback of #24732 (default for backLog set back to -1). ### Why are the changes needed? Previous change introduces backward incompatibility by overriding default of Netty's `io.netty.util.NetUtil#SOMAXCONN` Closes #27230 from xCASx/master. Authored-by: Maxim Kolesnikov <swe.kolesnikov@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…ate thread ### What changes were proposed in this pull request? [SPARK-20568](https://issues.apache.org/jira/browse/SPARK-20568) added the possibility to clean up completed files in streaming query. Deleting/archiving uses the main thread which can slow down processing. In this PR I've created thread pool to handle file delete/archival. The number of threads can be configured with `spark.sql.streaming.fileSource.cleaner.numThreads`. ### Why are the changes needed? Do file delete/archival in separate thread. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing unit tests. Closes #26502 from gaborgsomogyi/SPARK-29876. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
### What changes were proposed in this pull request? This is a followup of #26956 to add a migration document for 2.4.5. ### Why are the changes needed? New legacy configuration will restore the previous behavior safely. ### Does this PR introduce any user-facing change? This PR updates the doc. <img width="763" alt="screenshot" src="https://user-images.githubusercontent.com/9700541/72639939-9da5a400-391b-11ea-87b1-14bca15db5a6.png"> ### How was this patch tested? Build the document and see the change manually. Closes #27269 from dongjoon-hyun/SPARK-30312. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
…th subdirectories ### What changes were proposed in this pull request? This PR aims to add these test cases for resolution of ORC table location reported by [SPARK-25993](https://issues.apache.org/jira/browse/SPARK-25993) also add corresponding test cases for Parquet table. ### Why are the changes needed? The current behavior is complex, this test case suites are designed to prevent the accidental behavior change. This pr is rebased on master, the original pr is [23108](#23108) ### Does this PR introduce any user-facing change? No. This adds test cases only. ### How was this patch tested? This is a new test case. Closes #27130 from kevinyu98/spark-25993-2. Authored-by: Kevin Yu <qyu@us.ibm.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…DBC dialect ### What changes were proposed in this pull request? This PR adds a migration guide for MsSQLServer JDBC dialect for Apache Spark 2.4.4 and 2.4.5. ### Why are the changes needed? Apache Spark 2.4.4 updates the type mapping correctly according to MS SQL Server, but missed to mention that in the migration guide. In addition, 2.4.4 adds a configuration for the legacy behavior. ### Does this PR introduce any user-facing change? Yes. This is a documentation change.  ### How was this patch tested? Manually generate and see the doc. Closes #27270 from dongjoon-hyun/SPARK-28152-DOC. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
…nd RegressionModels ### What changes were proposed in this pull request? This PR adds: - `pyspark.ml.regression.JavaRegressor` - `pyspark.ml.regression.JavaRegressionModel` classes and replaces `JavaPredictor` and `JavaPredictionModel` in - `LinearRegression` / `LinearRegressionModel` - `DecisionTreeRegressor` / `DecisionTreeRegressionModel` (just addition as `JavaPredictionModel` hasn't been used) - `RandomForestRegressor` / `RandomForestRegressionModel` (just addition as `JavaPredictionModel` hasn't been used) - `GBTRegressor` / `GBTRegressionModel` (just addition as `JavaPredictionModel` hasn't been used) - `AFTSurvivalRegression` / `AFTSurvivalRegressionModel` - `GeneralizedLinearRegression` / `GeneralizedLinearRegressionModel` - `FMRegressor` / `FMRegressionModel` ### Why are the changes needed? - Internal PySpark consistency. - Feature parity with Scala. - Intermediate step towards implementing [SPARK-29212](https://issues.apache.org/jira/browse/SPARK-29212) ### Does this PR introduce any user-facing change? It adds new base classes, so it will affect `mro`. Otherwise interfaces should stay intact. ### How was this patch tested? Existing tests. Closes #27241 from zero323/SPARK-30533. Authored-by: zero323 <mszymkiewicz@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request? Upgrade the version of Genjavadoc from 0.14 to 0.15. ### Why are the changes needed? To enable to build for Scala 2.13.1. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? I confirmed there is no dependency error related to genjavadoc by manual build. Also, I generated javadoc by `LANG=C build/sbt -Pkinesis-asl -Pyarn -Pkubernetes -Phive-thriftserver unidoc` for both code with/without this change and did `diff -r` target/javadoc. Closes #27255 from sarutak/upgrade-genjavadoc. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? #26809 added `Dataset.tail` API. It should be good to have it in PySpark API as well. ### Why are the changes needed? To support consistent APIs. ### Does this PR introduce any user-facing change? No. It adds a new API. ### How was this patch tested? Manually tested and doctest was added. Closes #27251 from HyukjinKwon/SPARK-30539. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Removes suggestion to use -T for parallel Maven build. ### Why are the changes needed? Parallel builds don't necessarily work in the build right now. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? N/A Closes #27274 from srowen/ParallelBuild. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Pick up the HTTP fix from https://issues.apache.org/jira/browse/HIVE-22708 ### Why are the changes needed? This is a small but important fix to digest handling we should pick up from Hive. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing tests Closes #27273 from srowen/Hive22708. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Resolve the remaining comments in [PR#27226](#27226). ### Why are the changes needed? Resolve the comments. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing unit tests. Closes #27253 from JkSelf/followup-skewjoinoptimization2. Authored-by: jiake <ke.a.jia@intel.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? As we are not going to follow ANSI to implement year-month and day-time interval types, it is weird to compare the year-month part to the day-time part for our current implementation of interval type now. Additionally, the current ordering logic comes from PostgreSQL where the implementation of the interval is messy. And we are not aiming PostgreSQL compliance at all. THIS PR will revert #26681 and #26337 ### Why are the changes needed? make interval type more future-proofing ### Does this PR introduce any user-facing change? there are new in 3.0, so no ### How was this patch tested? existing uts shall work Closes #27262 from yaooqinn/SPARK-30551. Authored-by: Kent Yao <yaooqinn@hotmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? In the PR, I propose to fix the bug reported in SPARK-30530. CSV datasource returns invalid records in the case when `parsedSchema` is shorter than number of tokens returned by UniVocity parser. In the case `UnivocityParser.convert()` always throws `BadRecordException` independently from the result of applying filters. For the described case, I propose to save the exception in `badRecordException` and continue value conversion according to `parsedSchema`. If a bad record doesn't pass filters, `convert()` returns empty Seq otherwise throws `badRecordException`. ### Why are the changes needed? It fixes the bug reported in the JIRA ticket. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Added new test from the JIRA ticket. Closes #27239 from MaxGekk/spark-30530-csv-filter-is-null. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? make KUBERNETES_MASTER_INTERNAL_URL configurable ### Why are the changes needed? we do not always use the default port number 443 to access our kube-apiserver, and even in some mulit-tenant cluster, people do not use the service `kubernetes.default.svc` to access the kube-apiserver, so make the internal master configurable is necessary。 ### Does this PR introduce any user-facing change? user can configure the internal master url by ``` --conf spark.kubernetes.internal.master=https://kubernetes.default.svc:6443 ``` ### How was this patch tested? run in multi-cluster that do not use the https://kubernetes.default.svc to access the kube-apiserver Closes #27029 from wackxu/internalmaster. Authored-by: xushiwei 00425595 <xushiwei5@huawei.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…PROPERTIES ### What changes were proposed in this pull request? This PR adds a migration guide for `SHOW TBLPROPERTIES` for Apache Spark 3.0.0. ### Why are the changes needed? The behavior of `SHOW TBLPROPERTIES` changed when the table does not exist. The migration guide reflects this user facing change. ### Does this PR introduce any user-facing change? Yes. This is a documentation change. ### How was this patch tested? No tests were added because this is a doc change. Closes #27276 from imback82/SPARK-30282-followup. Authored-by: Terry Kim <yuminkim@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…terator" properly in Scala 2.13
### What changes were proposed in this pull request?
Renamed an identifier `iterator` to `iter` to avoid compile error with Scala 2.13.
### Why are the changes needed?
As of Scala 2.13, scala.collection.Iterator has "iterator" method so if an inner class of Iterator means to refer an outer identifier named "iterator", it does not work as we think.
I listed source files that can be affected by that change by `find . -name "*.scala" -exec grep -El "new .*Iterator\[.* +{" {} \;`
As far as I confirmed util.Utils` is affected.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes #27275 from sarutak/fix-iterator-for-2.13.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? This PR aims to add a fallback Maven repository when a mirror to `central` fail. ### Why are the changes needed? We use `Google Maven Central` in GitHub Action as a mirror of `central`. However, `Google Maven Central` sometimes doesn't have newly published artifacts and there is no guarantee when we get the newly published artifacts. By duplicating `Maven Central` with a new ID, we can add a fallback Maven repository which is not mirrored by `Google Maven Central`. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Manually testing with the new `Twitter` chill artifacts by switching `chill.version` from `0.9.3` to `0.9.5`. ``` $ rm -rf ~/.m2/repository/com/twitter/chill* $ mvn compile | grep chill Downloading from google-maven-central: https://maven-central.storage-download.googleapis.com/repos/central/data/com/twitter/chill_2.12/0.9.5/chill_2.12-0.9.5.pom Downloading from central_without_mirror: https://repo.maven.apache.org/maven2/com/twitter/chill_2.12/0.9.5/chill_2.12-0.9.5.pom Downloaded from central_without_mirror: https://repo.maven.apache.org/maven2/com/twitter/chill_2.12/0.9.5/chill_2.12-0.9.5.pom (2.8 kB at 11 kB/s) ``` Closes #27281 from dongjoon-hyun/SPARK-30572. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? Update Twitter Chill to 0.9.5. ### Why are the changes needed? Primarily, Scala 2.13 support for later. Other changes from 0.9.3 are apparently just minor fixes and improvements: https://github.com/twitter/chill/releases ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing tests Closes #27227 from srowen/SPARK-29290. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request? This pr intends to upgrade lz4-java from 1.7.0 to 1.7.1. ### Why are the changes needed? This release includes a bug fix for older macOS. You can see the link below for the changes; https://github.com/lz4/lz4-java/blob/master/CHANGES.md#171 ### Does this PR introduce any user-facing change? ### How was this patch tested? Existing tests. Closes #27271 from maropu/SPARK-30486. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…onstructor, plus related optimization in ParquetMapConverter ### What changes were proposed in this pull request? This PR implements a tiny performance optimization for a `GenericArrayData` constructor, avoiding an unnecessary roundtrip through `WrappedArray` when the provided value is already an array of objects. It also fixes a related performance problem in `ParquetRowConverter`. ### Why are the changes needed? `GenericArrayData` has a `this(seqOrArray: Any)` constructor, which was originally added in #13138 for use in `RowEncoder` (where we may not know concrete types until runtime) but is also called (perhaps unintentionally) in a few other code paths. In this constructor's existing implementation, a call to `new WrappedArray(Array[Object](""))` is dispatched to the `this(seqOrArray: Any)` constructor, where we then call `this(array.toSeq)`: this wraps the provided array into a `WrappedArray`, which is subsequently unwrapped in a `this(seq.toArray)` call. For an interactive example, see https://scastie.scala-lang.org/7jOHydbNTaGSU677FWA8nA This PR changes the `this(seqOrArray: Any)` constructor so that it calls the primary `this(array: Array[Any])` constructor, allowing us to save a `.toSeq.toArray` call; this comes at the cost of one additional `case` in the `match` statement (but I believe this has a negligible performance impact relative to the other savings). As code cleanup, I also reverted the JVM 1.7 workaround from #14271. I also fixed a related performance problem in `ParquetRowConverter`: previously, this code called `ArrayBasedMapData.apply` which, in turn, called the `this(Any)` constructor for `GenericArrayData`: this PR's micro-benchmarks show that this is _significantly_ slower than calling the `this(Array[Any])` constructor (and I also observed time spent here during other Parquet scan benchmarking work). To fix this performance problem, I replaced the call to the `ArrayBasedMapData.apply` method with direct calls to the `ArrayBasedMapData` and `GenericArrayData` constructors. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? I tested this by running code in a debugger and by running microbenchmarks (which I've added to a new `GenericArrayDataBenchmark` in this PR): - With JDK8 benchmarks: this PR's changes more than double the performance of calls to the `this(Any)` constructor. Even after improvements, however, calls to the `this(Array[Any])` constructor are still ~60x faster than calls to `this(Any)` when passing a non-primitive array (thereby motivating this patch's other change in `ParquetRowConverter`). - With JDK11 benchmarks: the changes more-or-less completely eliminate the performance penalty associated with the `this(Any)` constructor. Closes #27088 from JoshRosen/joshrosen/GenericArrayData-optimization. Authored-by: Josh Rosen <rosenville@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
`CalendarInterval` is maintained as a private class but might be used in a public way by users
e.g.
```scala
scala> spark.udf.register("getIntervalMonth", (_:org.apache.spark.unsafe.types.CalendarInterval).months)
scala> sql("select interval 2 month 1 day a").selectExpr("getIntervalMonth(a)").show
+-------------------+
|getIntervalMonth(a)|
+-------------------+
| 2|
+-------------------+
```
And it exists since 1.5.0, now we go to the 3.x era,may be it's time to make it public
### Why are the changes needed?
make the interval more future-proofing
### Does this PR introduce any user-facing change?
doc change
### How was this patch tested?
add ut.
Closes #27258 from yaooqinn/SPARK-30547.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? Changed signature of `rawParser` passed to `FailureSafeParser`. I propose to change return type from `Seq` to `Iterable`. I took `Iterable` to easier port the changes on Scala collections 2.13. Also, I replaced `Seq` by `Option` in CSV datasource - `UnivocityParser`, and in JSON parser exception one place in the case when specified schema is `StructType`, and JSON input is an array. ### Why are the changes needed? `Seq` is unnecessary requirement for return type from rawParser which may not have multiple rows per input like CSV datasource. ### Does this PR introduce any user-facing change? No ### How was this patch tested? By existing test suites `JsonSuite`, `UnivocityParserSuite`, `JsonFunctionsSuite`, `JsonExpressionsSuite`, `CsvSuite`, and `CsvFunctionsSuite`. Closes #27264 from MaxGekk/failuresafe-parser-seq. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? In the PR, I propose move out creation of `AvroOption` from `AvroPartitionReaderFactory.buildReader`, and create it earlier in `AvroScan.createReaderFactory`. ### Why are the changes needed? - To avoid building `AvroOptions` from a map of Avro options and Hadoop conf per each partition. - If an instance of `AvroOptions` is built only once at the driver side, we could output warnings while parsing Avro options and don't worry about noisiness of the warnings. ### Does this PR introduce any user-facing change? No ### How was this patch tested? By `AvroSuite` Closes #27272 from MaxGekk/avro-options-once-for-read. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? Use the new framework to resolve the ALTER TABLE commands. This PR also refactors ALTER TABLE logical plans such that they extend a base class `AlterTable`. Each plan now implements `def changes: Seq[TableChange]` for any table change operations. Additionally, `UnresolvedV2Relation` and its usage is completely removed. ### Why are the changes needed? This is a part of effort to make the relation lookup behavior consistent: [SPARK-29900](https://issues.apache.org/jira/browse/SPARK-29900). ### Does this PR introduce any user-facing change? No ### How was this patch tested? Updated existing tests Closes #27243 from imback82/v2commands_newframework. Authored-by: Terry Kim <yuminkim@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…rcFilterSuite ### What changes were proposed in this pull request? Explicitly set conf to let orc use DSv2 in `OrcFilterSuite` in both v1.2 and v2.3. ### Why are the changes needed? Tests should not rely on default conf when they're going to test something intentionally, which can be fail when conf changes. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Pass Jenkins. Closes #27285 from Ngone51/fix-orcfilter-test. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…appenders while reaching the limit ### What changes were proposed in this pull request? In the PR, I propose to output additional msg from the tests where a log appender is added. The message is printed as a part of `IllegalStateException` in the case of reaching the limit of maximum number of logged events. ### Why are the changes needed? If a log appender is not removed from the log4j appenders list. the caller message could help to investigate the problem and find the test which doesn't remove the log appender. ### Does this PR introduce any user-facing change? No ### How was this patch tested? By running the modified test suites `AvroSuite`, `CSVSuite`, `ResolveHintsSuite` and etc. Closes #27296 from MaxGekk/assign-name-to-log-appender. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ts accordingly in UnivocityParser ### What changes were proposed in this pull request? This PR proposes to clean up `UnivocityParser`. ### Why are the changes needed? It will slightly improve the performance since we don't do unnecessary computation for Array concatenations/creation. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Manually ran the existing tests. Closes #27287 from HyukjinKwon/SPARK-30530-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? Add `owner` property to v2 table, it is reversed by `TableCatalog`, indicates the table's owner. ### Why are the changes needed? enhance ownership management of catalog API ### Does this PR introduce any user-facing change? yes, add 1 reserved property - `owner` , and it is not allowed to use in OPTIONS/TBLPROPERTIES anymore, only if legacy on ### How was this patch tested? add uts Closes #27249 from yaooqinn/SPARK-30019. Authored-by: Kent Yao <yaooqinn@hotmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… scheduler backend changes ### What changes were proposed in this pull request? This is another PR for stage level scheduling. In particular this adds changes to the dynamic allocation manager and the scheduler backend to be able to track what executors are needed per ResourceProfile. Note the api is still private to Spark until the entire feature gets in, so this functionality will be there but only usable by tests for profiles other then the DefaultProfile. The main changes here are simply tracking things on a ResourceProfile basis as well as sending the executor requests to the scheduler backend for all ResourceProfiles. I introduce a ResourceProfileManager in this PR that will track all the actual ResourceProfile objects so that we can keep them all in a single place and just pass around and use in datastructures the resource profile id. The resource profile id can be used with the ResourceProfileManager to get the actual ResourceProfile contents. There are various places in the code that use executor "slots" for things. The ResourceProfile adds functionality to keep that calculation in it. This logic is more complex then it should due to standalone mode and mesos coarse grained not setting the executor cores config. They default to all cores on the worker, so calculating slots is harder there. This PR keeps the functionality to make the cores the limiting resource because the scheduler still uses that for "slots" for a few things. This PR does also add the resource profile id to the Stage and stage info classes to be able to test things easier. That full set of changes will come with the scheduler PR that will be after this one. The PR stops at the scheduler backend pieces for the cluster manager and the real YARN support hasn't been added in this PR, that again will be in a separate PR, so this has a few of the API changes up to the cluster manager and then just uses the default profile requests to continue. The code for the entire feature is here for reference: https://github.com/apache/spark/pull/27053/files although it needs to be upmerged again as well. ### Why are the changes needed? Needed for stage level scheduling feature. ### Does this PR introduce any user-facing change? No user facing api changes added here. ### How was this patch tested? Lots of unit tests and manually testing. I tested on yarn, k8s, standalone, local modes. Ran both failure and success cases. Closes #27313 from tgravescs/SPARK-29148. Authored-by: Thomas Graves <tgraves@nvidia.com> Signed-off-by: Thomas Graves <tgraves@apache.org>
### What changes were proposed in this pull request?
`spark.sql("select map()")` returns {}.
After these changes it will return map<null,null>
### Why are the changes needed?
After changes introduced due to #27521, it is important to maintain consistency while using map().
### Does this PR introduce any user-facing change?
Yes. Now map() will give map<null,null> instead of {}.
### How was this patch tested?
UT added. Migration guide updated as well
Closes #27542 from iRakson/SPARK-30790.
Authored-by: iRakson <raksonrakesh@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? This PR adds a config for Dynamic Partition Pruning subquery duplication and turns it off by default due to its potential performance regression. When planning a DPP filter, it seeks to reuse the broadcast exchange relation if the corresponding join is a BHJ with the filter relation being on the build side, otherwise it will either opt out or plan the filter as an un-reusable subquery duplication based on the cost estimate. However, the cost estimate is not accurate and only takes into account the table scan overhead, thus adding an un-reusable subquery duplication DPP filter can sometimes cause perf regression. This PR turns off the subquery duplication DPP filter by: 1. adding a config `spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly` and setting it `true` by default. 2. removing the existing meaningless config `spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcast` since we always want to reuse broadcast results if possible. ### Why are the changes needed? This is to fix a potential performance regression caused by DPP. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Updated DynamicPartitionPruningSuite to test the new configuration. Closes #27551 from maryannxue/spark-30528. Authored-by: maryannxue <maryannxue@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? This PR proposes to support Hive-style `ALTER TABLE ... REPLACE COLUMNS ...` as described in https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-Add/ReplaceColumns The user now can do the following: ```SQL CREATE TABLE t (col1 int, col2 int) USING Foo; ALTER TABLE t REPLACE COLUMNS (col2 string COMMENT 'comment2', col3 int COMMENT 'comment3'); ``` , which drops the existing columns `col1` and `col2`, and add new columns `col2` and `col3`. ### Why are the changes needed? This is a new DDL statement. Spark currently supports the Hive-style `ALTER TABLE ... CHANGE COLUMN ...`, so this new addition can be useful. ### Does this PR introduce any user-facing change? Yes, adding a new DDL statement. ### How was this patch tested? More tests to be added. Closes #27482 from imback82/replace_cols. Authored-by: Terry Kim <yuminkim@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? Although Spark SQL support bracketed comments, but `SQLQueryTestSuite` can't treat bracketed comments well and lead to generated golden files can't display bracketed comments well. This PR will improve the treatment of bracketed comments and add three test case in `PlanParserSuite`. Spark SQL can't support nested bracketed comments and #27495 used to support it. ### Why are the changes needed? Golden files can't display well. ### Does this PR introduce any user-facing change? No ### How was this patch tested? New UT. Closes #27481 from beliefer/ansi-brancket-comments. Authored-by: beliefer <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…constraint
### What changes were proposed in this pull request?
This PR add support infer constraints from cast equality constraint. For example:
```scala
scala> spark.sql("create table spark_29231_1(c1 bigint, c2 bigint)")
res0: org.apache.spark.sql.DataFrame = []
scala> spark.sql("create table spark_29231_2(c1 int, c2 bigint)")
res1: org.apache.spark.sql.DataFrame = []
scala> spark.sql("select t1.* from spark_29231_1 t1 join spark_29231_2 t2 on (t1.c1 = t2.c1 and t1.c1 = 1)").explain
== Physical Plan ==
*(2) Project [c1#5L, c2#6L]
+- *(2) BroadcastHashJoin [c1#5L], [cast(c1#7 as bigint)], Inner, BuildRight
:- *(2) Project [c1#5L, c2#6L]
: +- *(2) Filter (isnotnull(c1#5L) AND (c1#5L = 1))
: +- *(2) ColumnarToRow
: +- FileScan parquet default.spark_29231_1[c1#5L,c2#6L] Batched: true, DataFilters: [isnotnull(c1#5L), (c1#5L = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/root/spark-3.0.0-preview2-bin-hadoop2.7/spark-warehouse/spark_29231_1], PartitionFilters: [], PushedFilters: [IsNotNull(c1), EqualTo(c1,1)], ReadSchema: struct<c1:bigint,c2:bigint>
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint))), [id=#209]
+- *(1) Project [c1#7]
+- *(1) Filter isnotnull(c1#7)
+- *(1) ColumnarToRow
+- FileScan parquet default.spark_29231_2[c1#7] Batched: true, DataFilters: [isnotnull(c1#7)], Format: Parquet, Location: InMemoryFileIndex[file:/root/spark-3.0.0-preview2-bin-hadoop2.7/spark-warehouse/spark_29231_2], PartitionFilters: [], PushedFilters: [IsNotNull(c1)], ReadSchema: struct<c1:int>
```
After this PR:
```scala
scala> spark.sql("select t1.* from spark_29231_1 t1 join spark_29231_2 t2 on (t1.c1 = t2.c1 and t1.c1 = 1)").explain
== Physical Plan ==
*(2) Project [c1#0L, c2#1L]
+- *(2) BroadcastHashJoin [c1#0L], [cast(c1#2 as bigint)], Inner, BuildRight
:- *(2) Project [c1#0L, c2#1L]
: +- *(2) Filter (isnotnull(c1#0L) AND (c1#0L = 1))
: +- *(2) ColumnarToRow
: +- FileScan parquet default.spark_29231_1[c1#0L,c2#1L] Batched: true, DataFilters: [isnotnull(c1#0L), (c1#0L = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/root/opensource/spark/spark-warehouse/spark_29231_1], PartitionFilters: [], PushedFilters: [IsNotNull(c1), EqualTo(c1,1)], ReadSchema: struct<c1:bigint,c2:bigint>
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint))), [id=#99]
+- *(1) Project [c1#2]
+- *(1) Filter ((cast(c1#2 as bigint) = 1) AND isnotnull(c1#2))
+- *(1) ColumnarToRow
+- FileScan parquet default.spark_29231_2[c1#2] Batched: true, DataFilters: [(cast(c1#2 as bigint) = 1), isnotnull(c1#2)], Format: Parquet, Location: InMemoryFileIndex[file:/root/opensource/spark/spark-warehouse/spark_29231_2], PartitionFilters: [], PushedFilters: [IsNotNull(c1)], ReadSchema: struct<c1:int>
```
### Why are the changes needed?
Improve query performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
Closes #27252 from wangyum/SPARK-29231.
Authored-by: Yuming Wang <yumwang@ebay.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
In this PR, we add a parameter in the python function vector_to_array(col) that allows converting to a column of arrays of Float (32bits) in scala, which would be mapped to a numpy array of dtype=float32.
### Why are the changes needed?
In the downstream ML training, using float32 instead of float64 (default) would allow a larger batch size, i.e., allow more data to fit in the memory.
### Does this PR introduce any user-facing change?
Yes.
Old: `vector_to_array()` only take one param
```
df.select(vector_to_array("colA"), ...)
```
New: `vector_to_array()` can take an additional optional param: `dtype` = "float32" (or "float64")
```
df.select(vector_to_array("colA", "float32"), ...)
```
### How was this patch tested?
Unit test in scala.
doctest in python.
Closes #27522 from liangz1/udf-float32.
Authored-by: Liang Zhang <liang.zhang@databricks.com>
Signed-off-by: WeichenXu <weichen.xu@databricks.com>
### What changes were proposed in this pull request? This pr intends to add a document for the ANSI mode; <img width="600" alt="Screen Shot 2020-02-13 at 8 08 52" src="https://user-images.githubusercontent.com/692303/74386041-5934f780-4e38-11ea-8162-26e524e11c65.png"> <img width="600" alt="Screen Shot 2020-02-13 at 8 09 13" src="https://user-images.githubusercontent.com/692303/74386040-589c6100-4e38-11ea-8a64-899788eaf55f.png"> <img width="600" alt="Screen Shot 2020-02-13 at 8 09 26" src="https://user-images.githubusercontent.com/692303/74386039-5803ca80-4e38-11ea-949f-049208d2203d.png"> <img width="600" alt="Screen Shot 2020-02-13 at 8 09 38" src="https://user-images.githubusercontent.com/692303/74386036-563a0700-4e38-11ea-9ec3-87a8f6771cf0.png"> ### Why are the changes needed? For better document coverage and usability. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? N/A Closes #27489 from maropu/SPARK-30703. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…in optimizations <!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html 2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'. 4. Be sure to keep the PR description updated to reflect all changes. 5. Please write your PR title to summarize what this PR proposes. 6. If possible, provide a concise example to reproduce the issue for a faster review. --> ### What changes were proposed in this pull request? <!-- Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue. If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below. 1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers. 2. If you fix some SQL features, you can provide some references of other DBMSes. 3. If there is design documentation, please add the link. 4. If there is a discussion in the mailing list, please add the link. --> This is a followup of #26434 This PR use one special shuffle reader for skew join, so that we only have one join after optimization. In order to do that, this PR 1. add a very general `CustomShuffledRowRDD` which support all kind of partition arrangement. 2. move the logic of coalescing shuffle partitions to a util function, and call it during skew join optimization, to totally decouple with the `ReduceNumShufflePartitions` rule. It's too complicated to interfere skew join with `ReduceNumShufflePartitions`, as you need to consider the size of split partitions which don't respect target size already. ### Why are the changes needed? <!-- Please clarify why the changes are needed. For instance, 1. If you propose a new API, clarify the use case for a new API. 2. If you fix a bug, you can clarify why it is a bug. --> The current skew join optimization has a serious performance issue: the size of the query plan depends on the number and size of skewed partitions. ### Does this PR introduce any user-facing change? <!-- If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible. If no, write 'No'. --> no ### How was this patch tested? <!-- If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible. If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future. If tests were not added, please describe why they were not added and/or why it was difficult to add. --> existing tests test UI manually:  explain output ``` AdaptiveSparkPlan(isFinalPlan=true) +- OverwriteByExpression org.apache.spark.sql.execution.datasources.noop.NoopTable$403a2ed5, [AlwaysTrue()], org.apache.spark.sql.util.CaseInsensitiveStringMap1f +- *(5) SortMergeJoin(skew=true) [key1#2L], [key2#6L], Inner :- *(3) Sort [key1#2L ASC NULLS FIRST], false, 0 : +- SkewJoinShuffleReader 2 skewed partitions with size(max=5 KB, min=5 KB, avg=5 KB) : +- ShuffleQueryStage 0 : +- Exchange hashpartitioning(key1#2L, 200), true, [id=#53] : +- *(1) Project [(id#0L % 2) AS key1#2L] : +- *(1) Filter isnotnull((id#0L % 2)) : +- *(1) Range (0, 100000, step=1, splits=6) +- *(4) Sort [key2#6L ASC NULLS FIRST], false, 0 +- SkewJoinShuffleReader 2 skewed partitions with size(max=5 KB, min=5 KB, avg=5 KB) +- ShuffleQueryStage 1 +- Exchange hashpartitioning(key2#6L, 200), true, [id=#64] +- *(2) Project [((id#4L % 2) + 1) AS key2#6L] +- *(2) Filter isnotnull(((id#4L % 2) + 1)) +- *(2) Range (0, 100000, step=1, splits=6) ``` Closes #27493 from cloud-fan/aqe. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: herman <herman@databricks.com>
{kind=link}
### What changes were proposed in this pull request? This PR aims to support JDK11 test in K8S integration tests. - This is an update in testing framework instead of individual tests. - This will enable JDK11 runtime test when you didn't installed JDK11 on your local system. ### Why are the changes needed? Apache Spark 3.0.0 adds JDK11 support, but K8s integration tests use JDK8 until now. ### Does this PR introduce any user-facing change? No. This is a dev-only test-related PR. ### How was this patch tested? This is irrelevant to Jenkins UT, but Jenkins K8S IT (JDK8) should pass. - #27559 (comment) (JDK8 Passed) And, manually do the following for JDK11 test. ``` $ NO_MANUAL=1 ./dev/make-distribution.sh --r --pip --tgz -Phadoop-3.2 -Pkubernetes $ resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh --java-image-tag 11-jre-slim --spark-tgz $PWD/spark-*.tgz ``` ``` $ docker run -it --rm kubespark/spark:1318DD8A-2B15-4A00-BC69-D0E90CED235B /usr/local/openjdk-11/bin/java --version | tail -n1 OpenJDK 64-Bit Server VM 18.9 (build 11.0.6+10, mixed mode) ``` Closes #27559 from dongjoon-hyun/SPARK-30807. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…empty params ### What changes were proposed in this pull request? This PR aims to fix `dev-run-integration-tests.sh` to ignore empty params correctly. ### Why are the changes needed? The following script runs `mvn` integration test like the following. ``` $ resource-managers/kubernetes/integration-tests/dev/dev-run-integration-tests.sh ... build/mvn integration-test -f /Users/dongjoon/APACHE/spark/pom.xml -pl resource-managers/kubernetes/integration-tests -am -Pscala-2.12 -Pkubernetes -Pkubernetes-integration-tests -Djava.version=8 -Dspark.kubernetes.test.sparkTgz=N/A -Dspark.kubernetes.test.imageTag=N/A -Dspark.kubernetes.test.imageRepo=docker.io/kubespark -Dspark.kubernetes.test.deployMode=minikube -Dtest.include.tags=k8s -Dspark.kubernetes.test.namespace= -Dspark.kubernetes.test.serviceAccountName= -Dspark.kubernetes.test.kubeConfigContext= -Dspark.kubernetes.test.master= -Dtest.exclude.tags= -Dspark.kubernetes.test.jvmImage=spark -Dspark.kubernetes.test.pythonImage=spark-py -Dspark.kubernetes.test.rImage=spark-r ``` After this PR, the empty parameters like the followings will be skipped like the original design. ``` -Dspark.kubernetes.test.namespace= -Dspark.kubernetes.test.serviceAccountName= -Dspark.kubernetes.test.kubeConfigContext= -Dspark.kubernetes.test.master= -Dtest.exclude.tags= ``` ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Pass the Jenkins K8S integration test. Closes #27566 from dongjoon-hyun/SPARK-30816. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
### What changes were proposed in this pull request?
This PR scopes `SparkSession.active` to prevent problems with processing queries with possibly different spark sessions (and different configs). A new method, `withActive` is introduced on `SparkSession` that restores the previous spark session after the block of code is executed.
### Why are the changes needed?
`SparkSession.active` is a thread local variable that points to the current thread's spark session. It is important to note that the `SQLConf.get` method depends on `SparkSession.active`. In the current implementation it is possible that `SparkSession.active` points to a different session which causes various problems. Most of these problems arise because part of the query processing is done using the configurations of a different session. For example, when creating a data frame using a new session, i.e., `session.sql("...")`, part of the data frame is constructed using the currently active spark session, which can be a different session from the one used later for processing the query.
### Does this PR introduce any user-facing change?
The `withActive` method is introduced on `SparkSession`.
### How was this patch tested?
Unit tests (to be added)
Closes #27387 from dbaliafroozeh/UseWithActiveSessionInQueryExecution.
Authored-by: Ali Afroozeh <ali.afroozeh@databricks.com>
Signed-off-by: herman <herman@databricks.com>
### What changes were proposed in this pull request?
The `allGather` method is added to the `BarrierTaskContext`. This method contains the same functionality as the `BarrierTaskContext.barrier` method; it blocks the task until all tasks make the call, at which time they may continue execution. In addition, the `allGather` method takes an input message. Upon returning from the `allGather` the task receives a list of all the messages sent by all the tasks that made the `allGather` call.
### Why are the changes needed?
There are many situations where having the tasks communicate in a synchronized way is useful. One simple example is if each task needs to start a server to serve requests from one another; first the tasks must find a free port (the result of which is undetermined beforehand) and then start making requests, but to do so they each must know the port chosen by the other task. An `allGather` method would allow them to inform each other of the port they will run on.
### Does this PR introduce any user-facing change?
Yes, an `BarrierTaskContext.allGather` method will be available through the Scala, Java, and Python APIs.
### How was this patch tested?
Most of the code path is already covered by tests to the `barrier` method, since this PR includes a refactor so that much code is shared by the `barrier` and `allGather` methods. However, a test is added to assert that an all gather on each tasks partition ID will return a list of every partition ID.
An example through the Python API:
```python
>>> from pyspark import BarrierTaskContext
>>>
>>> def f(iterator):
... context = BarrierTaskContext.get()
... return [context.allGather('{}'.format(context.partitionId()))]
...
>>> sc.parallelize(range(4), 4).barrier().mapPartitions(f).collect()[0]
[u'3', u'1', u'0', u'2']
```
Closes #27395 from sarthfrey/master.
Lead-authored-by: sarthfrey-db <sarth.frey@databricks.com>
Co-authored-by: sarthfrey <sarth.frey@gmail.com>
Signed-off-by: Xiangrui Meng <meng@databricks.com>
This reverts commit 57254c9.
…ed links in documentation of `Data{Frame,Stream}{Reader,Writer}`
This commit is published into the public domain.
### What changes were proposed in this pull request?
This PR fixes the documentation of `DataFrameReader`, `DataFrameWriter`, `DataStreamReader`, and `DataStreamWriter`, where attributes of other classes were misrepresented as functions. Additionally, creation of hyperlinks across modules was fixed in these instances.
### Why are the changes needed?
The old state produced documentation that suggested invalid usage of PySpark objects (accessing attributes as though they were callable.)
### Does this PR introduce any user-facing change?
No, except for improved documentation.
### How was this patch tested?
No test added; documentation build runs through.
Closes #27553 from DavidToneian/docfix-DataFrameReader-DataFrameWriter-DataStreamReader-DataStreamWriter.
Authored-by: David Toneian <david@toneian.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? This PR makes sure AQE is either enabled or disabled for the entire query, including the main query and all subqueries. Currently there are unsupported queries by AQE, e.g., queries that contain DPP filters. We need to make sure that if the main query is unsupported, none of the sub-queries should apply AQE, otherwise it can lead to performance regressions due to missed opportunity of sub-query reuse. ### Why are the changes needed? To get rid of potential perf regressions when AQE is turned on. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Updated DynamicPartitionPruningSuite: 1. Removed the existing workaround `withSQLConf(SQLConf.ADAPTIVE_EXECUTION_ENABLED.key, "false")` 2. Added `DynamicPartitionPruningSuiteAEOn` and `DynamicPartitionPruningSuiteAEOff` to enable testing this suite with AQE on and off options 3. Added a check in `checkPartitionPruningPredicate` to verify that the subqueries are always in sync with the main query in terms of whether AQE is applied. Closes #27554 from maryannxue/spark-30801. Authored-by: maryannxue <maryannxue@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…documentation on Windows This commit is published into the public domain. ### What changes were proposed in this pull request? In analogy to `python/docs/Makefile`, which has > export PYTHONPATH=$(realpath ..):$(realpath ../lib/py4j-0.10.8.1-src.zip) on line 10, this PR adds > set PYTHONPATH=..;..\lib\py4j-0.10.8.1-src.zip to `make2.bat`. Since there is no `realpath` in default installations of Windows, I left the relative paths unresolved. Per the instructions on how to build docs, `make.bat` is supposed to be run from `python/docs` as the working directory, so this should probably not cause issues (`%BUILDDIR%` is a relative path as well.) ### Why are the changes needed? When building the PySpark documentation on Windows, by changing directory to `python/docs` and running `make.bat` (which runs `make2.bat`), the majority of the documentation may not be built if pyspark is not in the default `%PYTHONPATH%`. Sphinx then reports that `pyspark` (and possibly dependencies) cannot be imported. If `pyspark` is in the default `%PYTHONPATH%`, I suppose it is that version of `pyspark` – as opposed to the version found above the `python/docs` directory – that is considered when building the documentation, which may result in documentation that does not correspond to the development version one is trying to build. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Manual tests on my Windows 10 machine. Additional tests with other environments very welcome! Closes #27569 from DavidToneian/SPARK-30823. Authored-by: David Toneian <david@toneian.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…types correctly ### What changes were proposed in this pull request? We should convert Spark InternalRows to hive data via `HiveInspectors.wrapperFor`. ### Why are the changes needed? We may hit below exception without this change: ``` [info] org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 1 times, most recent failure: Lost task 0.0 in stage 1.0 (TID 1, 192.168.1.6, executor driver): java.lang.ClassCastException: org.apache.spark.sql.types.Decimal cannot be cast to org.apache.hadoop.hive.common.type.HiveDecimal [info] at org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaHiveDecimalObjectInspector.getPrimitiveJavaObject(JavaHiveDecimalObjectInspector.java:55) [info] at org.apache.hadoop.hive.serde2.lazy.LazyUtils.writePrimitiveUTF8(LazyUtils.java:321) [info] at org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.serialize(LazySimpleSerDe.java:292) [info] at org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.serializeField(LazySimpleSerDe.java:247) [info] at org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe.doSerialize(LazySimpleSerDe.java:231) [info] at org.apache.hadoop.hive.serde2.AbstractEncodingAwareSerDe.serialize(AbstractEncodingAwareSerDe.java:55) [info] at org.apache.spark.sql.hive.execution.ScriptTransformationWriterThread.$anonfun$run$2(ScriptTransformationExec.scala:300) [info] at org.apache.spark.sql.hive.execution.ScriptTransformationWriterThread.$anonfun$run$2$adapted(ScriptTransformationExec.scala:281) [info] at scala.collection.Iterator.foreach(Iterator.scala:941) [info] at scala.collection.Iterator.foreach$(Iterator.scala:941) [info] at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) [info] at org.apache.spark.sql.hive.execution.ScriptTransformationWriterThread.$anonfun$run$1(ScriptTransformationExec.scala:281) [info] at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) [info] at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1932) [info] at org.apache.spark.sql.hive.execution.ScriptTransformationWriterThread.run(ScriptTransformationExec.scala:270) ``` ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Added new test. But please note that this test returns different result between Hive1.2 and Hive2.3 due to `HiveDecimal` or `SerDe` difference(don't know the root cause yet). Closes #27556 from Ngone51/script_transform. Lead-authored-by: yi.wu <yi.wu@databricks.com> Co-authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…column from 'value' in csv(dataset) API
### What changes were proposed in this pull request?
This PR fixes `DataFrameReader.csv(dataset: Dataset[String])` API to take a `Dataset[String]` originated from a column name different from `value`. This is a long-standing bug started from the very first place.
`CSVUtils.filterCommentAndEmpty` assumed the `Dataset[String]` to be originated with `value` column. This PR changes to use the first column name in the schema.
### Why are the changes needed?
For `DataFrameReader.csv(dataset: Dataset[String])` to support any `Dataset[String]` as the signature indicates.
### Does this PR introduce any user-facing change?
Yes,
```scala
val ds = spark.range(2).selectExpr("concat('a,b,', id) AS text").as[String]
spark.read.option("header", true).option("inferSchema", true).csv(ds).show()
```
Before:
```
org.apache.spark.sql.AnalysisException: cannot resolve '`value`' given input columns: [text];;
'Filter (length(trim('value, None)) > 0)
+- Project [concat(a,b,, cast(id#0L as string)) AS text#2]
+- Range (0, 2, step=1, splits=Some(2))
```
After:
```
+---+---+---+
| a| b| 0|
+---+---+---+
| a| b| 1|
+---+---+---+
```
### How was this patch tested?
Unittest was added.
Closes #27561 from HyukjinKwon/SPARK-30810.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…Y` levels
### What changes were proposed in this pull request?
In the PR, I propose to use Java 8 time API in timestamp truncations to the levels of `HOUR` and `DAY`. The problem is in the usage of `timeZone.getOffset(millis)` in days/hours truncations where the combined calendar (Julian + Gregorian) is used underneath.
### Why are the changes needed?
The change fix wrong truncations. For example, the following truncation to hours should print `0010-01-01 01:00:00` but it outputs wrong timestamp:
```scala
Seq("0010-01-01 01:02:03.123456").toDF()
.select($"value".cast("timestamp").as("ts"))
.select(date_trunc("HOUR", $"ts").cast("string"))
.show(false)
+------------------------------------+
|CAST(date_trunc(HOUR, ts) AS STRING)|
+------------------------------------+
|0010-01-01 01:30:17 |
+------------------------------------+
```
### Does this PR introduce any user-facing change?
Yes. After the changes, the result of the example above is:
```scala
+------------------------------------+
|CAST(date_trunc(HOUR, ts) AS STRING)|
+------------------------------------+
|0010-01-01 01:00:00 |
+------------------------------------+
```
### How was this patch tested?
- Added new test to `DateFunctionsSuite`
- By `DateExpressionsSuite` and `DateTimeUtilsSuite`
Closes #27512 from MaxGekk/fix-trunc-old-timestamp.
Authored-by: Maxim Gekk <max.gekk@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… variable to set in both executor and driver ### What changes were proposed in this pull request? This PR address the comment at #26496 (comment) and improves the migration guide to explicitly note that the legacy environment variable to set in both executor and driver. ### Why are the changes needed? To clarify this env should be set both in driver and executors. ### Does this PR introduce any user-facing change? Nope. ### How was this patch tested? I checked it via md editor. Closes #27573 from HyukjinKwon/SPARK-29748. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
…emption support This PR is based on an existing/previou PR - #19045 ### What changes were proposed in this pull request? This changes adds a decommissioning state that we can enter when the cloud provider/scheduler lets us know we aren't going to be removed immediately but instead will be removed soon. This concept fits nicely in K8s and also with spot-instances on AWS / preemptible instances all of which we can get a notice that our host is going away. For now we simply stop scheduling jobs, in the future we could perform some kind of migration of data during scale-down, or at least stop accepting new blocks to cache. There is a design document at https://docs.google.com/document/d/1xVO1b6KAwdUhjEJBolVPl9C6sLj7oOveErwDSYdT-pE/edit?usp=sharing ### Why are the changes needed? With more move to preemptible multi-tenancy, serverless environments, and spot-instances better handling of node scale down is required. ### Does this PR introduce any user-facing change? There is no API change, however an additional configuration flag is added to enable/disable this behaviour. ### How was this patch tested? New integration tests in the Spark K8s integration testing. Extension of the AppClientSuite to test decommissioning seperate from the K8s. Closes #26440 from holdenk/SPARK-20628-keep-track-of-nodes-which-are-going-to-be-shutdown-r4. Lead-authored-by: Holden Karau <hkarau@apple.com> Co-authored-by: Holden Karau <holden@pigscanfly.ca> Signed-off-by: Holden Karau <hkarau@apple.com>
### What changes were proposed in this pull request? 1. `InMemoryTable` was flatting the nested columns, and then the flatten columns was used to look up the indices which is not correct. This PR implements partitioned by nested column for `InMemoryTable`. ### Why are the changes needed? This PR implements partitioned by nested column for `InMemoryTable`, so we can test this features in DSv2 ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing unit tests and new tests. Closes #26929 from dbtsai/addTests. Authored-by: DB Tsai <d_tsai@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com>
…d down to parquet ### What changes were proposed in this pull request? In the PR, I propose to convert the attribute name of `StringStartsWith` pushed down to the Parquet datasource to column reference via the `nameToParquetField` map. Similar conversions are performed for other source filters pushed down to parquet. ### Why are the changes needed? This fixes the bug described in [SPARK-30826](https://issues.apache.org/jira/browse/SPARK-30826). The query from an external table: ```sql CREATE TABLE t1 (col STRING) USING parquet OPTIONS (path '$path') ``` created on top of written parquet files by `Seq("42").toDF("COL").write.parquet(path)` returns wrong empty result: ```scala spark.sql("SELECT * FROM t1 WHERE col LIKE '4%'").show +---+ |col| +---+ +---+ ``` ### Does this PR introduce any user-facing change? Yes. After the changes the result is correct for the example above: ```scala spark.sql("SELECT * FROM t1 WHERE col LIKE '4%'").show +---+ |col| +---+ | 42| +---+ ``` ### How was this patch tested? Added a test to `ParquetFilterSuite` Closes #27574 from MaxGekk/parquet-StringStartsWith-case-sens. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? Fix typo def setRest(dstId: VertexId, localDstId: Int, dstAttr: VD, attr: ED) to def setDest(dstId: VertexId, localDstId: Int, dstAttr: VD, attr: ED) ### Why are the changes needed? Typo ### Does this PR introduce any user-facing change? No ### How was this patch tested? N/A Closes #27594 from xwu99/fix-graphx-setDest. Authored-by: Wu, Xiaochang <xiaochang.wu@intel.com> Signed-off-by: Sean Owen <srowen@gmail.com>
…s the side bar names ### What changes were proposed in this pull request? Make link names exactly the same as the side bar names ### Why are the changes needed? Make doc look better ### Does this PR introduce any user-facing change? before:  after: 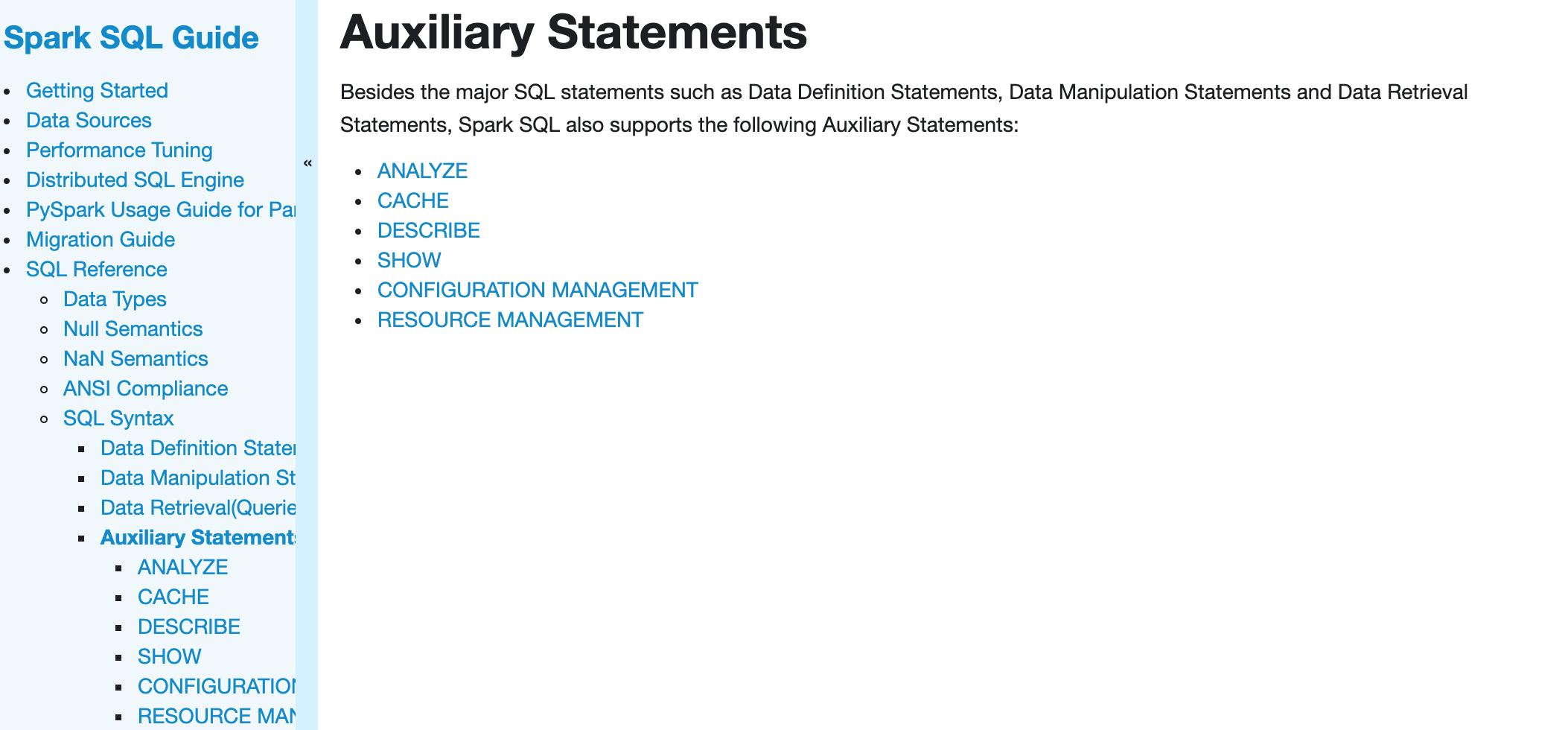 ### How was this patch tested? Manually build and check the docs Closes #27591 from huaxingao/spark-doc-followup. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Sean Owen <srowen@gmail.com>
{kind=link}
{kind=link}
### What changes were proposed in this pull request? Change the link to the Scala API document. ``` $ git grep "#org.apache.spark.package" docs/_layouts/global.html: <li><a href="api/scala/index.html#org.apache.spark.package">Scala</a></li> docs/index.md:* [Spark Scala API (Scaladoc)](api/scala/index.html#org.apache.spark.package) docs/rdd-programming-guide.md:[Scala](api/scala/#org.apache.spark.package), [Java](api/java/), [Python](api/python/) and [R](api/R/). ``` ### Why are the changes needed? The home page link for Scala API document is incorrect after upgrade to 3.0 ### Does this PR introduce any user-facing change? Document UI change only. ### How was this patch tested? Local test, attach screenshots below: Before:  After:  Closes #27549 from xuanyuanking/scala-doc. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
{kind=link}
{kind=link}
…ent the transient tag ### What changes were proposed in this pull request? it is said in [LeastSquaresAggregator](https://github.com/apache/spark/blob/12e1bbaddbb2ef304b5880a62df6683fcc94ea54/mllib/src/main/scala/org/apache/spark/ml/optim/aggregator/LeastSquaresAggregator.scala#L188) that : > // do not use tuple assignment above because it will circumvent the transient tag I then check this issue with Scala 2.13.1 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241) ### Why are the changes needed? avoid tuple assignment because it will circumvent the transient tag ### Does this PR introduce any user-facing change? No ### How was this patch tested? existing testsuites Closes #27523 from zhengruifeng/avoid_tuple_assign_to_transient. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
shanyu
pushed a commit
that referenced
this pull request
Feb 16, 2020
### What changes were proposed in this pull request? `org.apache.spark.sql.kafka010.KafkaDelegationTokenSuite` failed lately. After had a look at the logs it just shows the following fact without any details: ``` Caused by: sbt.ForkMain$ForkError: sun.security.krb5.KrbException: Server not found in Kerberos database (7) - Server not found in Kerberos database ``` Since the issue is intermittent and not able to reproduce it we should add more debug information and wait for reproduction with the extended logs. ### Why are the changes needed? Failing test doesn't give enough debug information. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? I've started the test manually and checked that such additional debug messages show up: ``` >>> KrbApReq: APOptions are 00000000 00000000 00000000 00000000 >>> EType: sun.security.krb5.internal.crypto.Aes128CtsHmacSha1EType Looking for keys for: kafka/localhostEXAMPLE.COM Added key: 17version: 0 Added key: 23version: 0 Added key: 16version: 0 Found unsupported keytype (3) for kafka/localhostEXAMPLE.COM >>> EType: sun.security.krb5.internal.crypto.Aes128CtsHmacSha1EType Using builtin default etypes for permitted_enctypes default etypes for permitted_enctypes: 17 16 23. >>> EType: sun.security.krb5.internal.crypto.Aes128CtsHmacSha1EType MemoryCache: add 1571936500/174770/16C565221B70AAB2BEFE31A83D13A2F4/client/localhostEXAMPLE.COM to client/localhostEXAMPLE.COM|kafka/localhostEXAMPLE.COM MemoryCache: Existing AuthList: #3: 1571936493/200803/8CD70D280B0862C5DA1FF901ECAD39FE/client/localhostEXAMPLE.COM #2: 1571936499/985009/BAD33290D079DD4E3579A8686EC326B7/client/localhostEXAMPLE.COM #1: 1571936499/995208/B76B9D78A9BE283AC78340157107FD40/client/localhostEXAMPLE.COM ``` Closes apache#26252 from gaborgsomogyi/SPARK-29580. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?