Comparing changes
Open a pull request
Commits on Dec 14, 2020
-
Use OpenJDK instead of OracleJDK in Binder (#1969)
This PR proposes to use OpenJDK instead. Current Oracle JDK download with `wget` is broken: ``` --2020-12-14 08:16:14-- http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz Resolving download.oracle.com (download.oracle.com)... 184.50.116.99 Connecting to download.oracle.com (download.oracle.com)|184.50.116.99|:80... connected. HTTP request sent, awaiting response... 302 Moved Temporarily Location: https://edelivery.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz [following] --2020-12-14 08:16:14-- https://edelivery.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz Resolving edelivery.oracle.com (edelivery.oracle.com)... 2.17.191.76, 2a02:26f0:1700:58b::366, 2a02:26f0:1700:591::366 Connecting to edelivery.oracle.com (edelivery.oracle.com)|2.17.191.76|:443... connected. HTTP request sent, awaiting response... 403 Forbidden 2020-12-14 08:20:14 ERROR 403: Forbidden. tar (child): jdk-8u131-linux-x64.tar.gz: Cannot open: No such file or directory tar (child): Error is not recoverable: exiting now tar: Child returned status 2 tar: Error is not recoverable: exiting now ./postBuild: line 9: cd: jdk1.8.0_131: No such file or directory ./postBuild: line 11: cd: bin: No such file or directory ``` This was tested in https://mybinder.org/v2/gh/hyukjinkwon/koalas/fix-binder?filepath=docs%2Fsource%2Fgetting_started%2F10min.ipynb Apache Spark uses the same approach as well:
Commits on Dec 16, 2020
-
Fix stat functions with no numeric columns. (#1967)
Some statistic functions fail if there are no numeric columns. ```py >>> kdf = ks.DataFrame({"A": pd.date_range("2020-01-01", periods=3), "B": pd.date_range("2021-01-01", periods=3)}) >>> kdf.mean() Traceback (most recent call last): ... ValueError: Current DataFrame has more then the given limit 1 rows. Please set 'compute.max_rows' by using 'databricks.koalas.config.set_option' to retrieve to retrieve more than 1 rows. Note that, before changing the 'compute.max_rows', this operation is considerably expensive. ``` The functions which allow non-numeric columns by default are: - `count` - `min` - `max` -
Simplify plot backend support (#1970)
This PR proposes to simplify plot implementation. Current Koalas implementation attempts to map the argument between other plotting backends (e.g., matplotlib vs plotly). Keeping this map is a huge maintenance cost and it's unrealistic to track their change and keep updating this map. Pandas itself does not keep this map either: ```python >>> import pandas as pd >>> pd.DataFrame([1,2,3]).plot.line(logx=1) <AxesSubplot:> >>> pd.options.plotting.backend = "plotly" >>> pd.DataFrame([1,2,3]).plot.line(logx=1) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../opt/miniconda3/envs/python3.8/lib/python3.8/site-packages/pandas/plotting/_core.py", line 1017, in line return self(kind="line", x=x, y=y, **kwargs) File "/.../opt/miniconda3/envs/python3.8/lib/python3.8/site-packages/pandas/plotting/_core.py", line 879, in __call__ return plot_backend.plot(self._parent, x=x, y=y, kind=kind, **kwargs) File "/.../miniconda3/envs/python3.8/lib/python3.8/site-packages/plotly/__init__.py", line 102, in plot return line(data_frame, **kwargs) TypeError: line() got an unexpected keyword argument 'logx' ```
Commits on Dec 18, 2020
-
Implement (DataFrame|Series).plot.pie in plotly (#1971)
This PR implements `DataFrame.plot.pie` in plotly as below: ```python from databricks import koalas as ks kdf = ks.DataFrame( {'a': [1, 2, 3, 4, 5, 6], 'b': [100, 200, 300, 400, 500, 600]}, index=[10, 20, 30, 40, 50, 60]) ks.options.plotting.backend = 'plotly' kdf.plot.pie(y="b") ``` 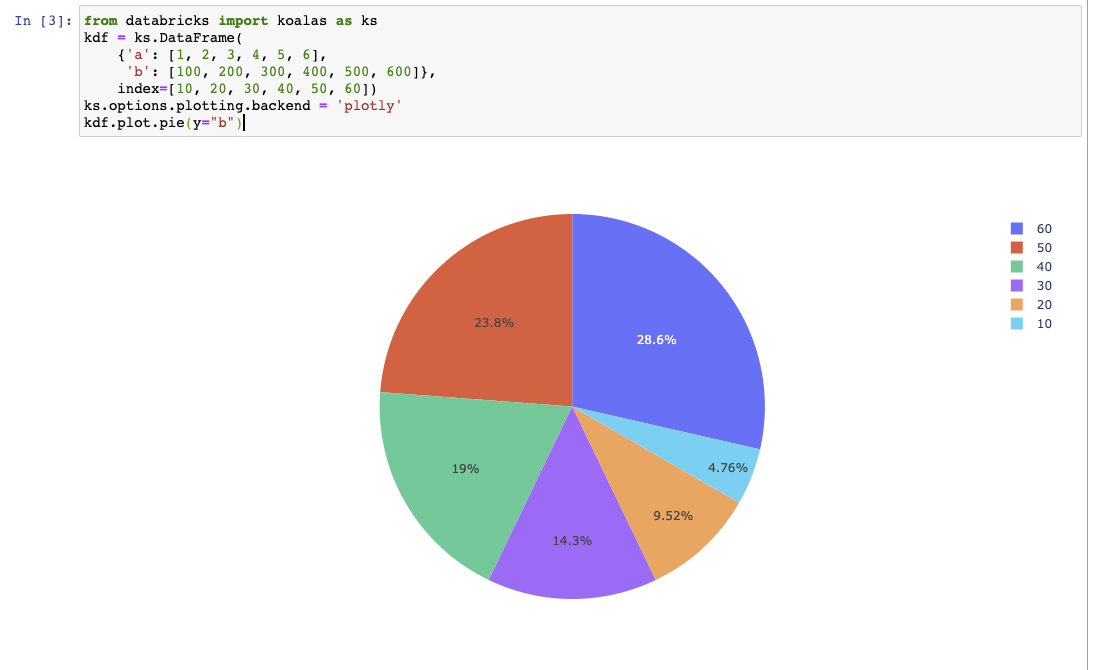 Binder to test: https://mybinder.org/v2/gh/HyukjinKwon/koalas/plotly-pie?filepath=docs%2Fsource%2Fgetting_started%2F10min.ipynb
{kind=link}
Commits on Dec 21, 2020
-
Refine Frame._reduce_for_stat_function. (#1975)
Refines `DataFrame/Series._reduce_for_stat_function` to avoid special handling based on a specific function. Also: - Consolidates the implementations of `count` and support `numeric_only` parameter. - Adds argument type annotations.
Commits on Dec 22, 2020
-
Add min_count parameter for Frame.sum. (#1978)
Adds `min_count` parameter for `Frame.sum`.
Commits on Dec 23, 2020
-
Fix cumsum and cumprod. (#1982)
Fixes `DataFrame/Series/GroupBy.cumsum` and `cumprod`.
-
Fix Frame.abs to support bool type and disallow non-numeric types. (#…
…1980) Fixes `Frame.abs` to support bool type and disallow non-numeric types.
-
Refine DataFrame/Series.product. (#1979)
Refines `DataFrame/Series.product` to: - Consolidate and reuse `_reduce_for_stat_function`. - Support `axis`, `numeric_only`, and `min_count` parameters. - Enable to calculate values including negative values or zeros.
-
The build failed due to conflicts between recent PRs. ``` flake8 checks failed: ./databricks/koalas/series.py:5741:45: F821 undefined name 'BooleanType' if isinstance(kser.spark.data_type, BooleanType): ^ ./databricks/koalas/series.py:5750:45: F821 undefined name 'BooleanType' if isinstance(self.spark.data_type, BooleanType): ^ ``` -
Refine DataFrame/Series.quantile. (#1977)
Refines `DataFrame/Series.quantile` to: - Reuse `_reduce_for_stat_function` when `q` is `float`. - Consolidate the logic when `q` is `Iterable`. Also support `numeric_only` for `DataFrame`.
Commits on Dec 24, 2020
-
Support ddof parameter for std and var. (#1986)
Supports `ddof` parameter for `Frame.std` and `var`.
Commits on Dec 26, 2020
-
Use Python type name instead of Spark's in error messages. (#1985)
Addressing #1980 (comment) to add pandas dtypes.
Commits on Dec 28, 2020
-
Fix wrong condition for almostequals (#1988)
Fixed several wrong condition in `if` statement for `assertPandasAlmostEqual`.
Commits on Dec 29, 2020
-
Support setattr for DataFrame. (#1989)
Support to set attributes for DataFrame. ```py >>> kdf = ks.DataFrame({'A': [1, 2, 3, None]}) >>> kdf.A = kdf.A.fillna(kdf.A.median()) >>> kdf A 0 1.0 1 2.0 2 3.0 3 2.0 ```
Commits on Jan 5, 2021
-
Add note about missing mixed type support to docs (#1990)
Added note about missing support for mixed type to documents.  Resolves #1981
{kind=link}
Commits on Jan 6, 2021
-
Implemented sem() for Series and DataFrame (#1993)
This PR proposes `Series.sem()` and `DataFrame.sem()` ```python >>> kdf = ks.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]}) >>> kdf a b 0 1 4 1 2 5 2 3 6 >>> kdf.sem() a 0.57735 b 0.57735 dtype: float64 >>> kdf.sem(ddof=0) a 0.471405 b 0.471405 dtype: float64 >>> kdf.sem(axis=1) 0 1.5 1 1.5 2 1.5 dtype: float64 Support for Series >>> kser = kdf.a >>> kser 0 1 1 2 2 3 Name: a, dtype: int64 >>> kser.sem() 0.5773502691896258 >>> kser.sem(ddof=0) 0.47140452079103173 ```
Commits on Jan 7, 2021
-
Added ddof parameter for GroupBy.std() and GroupBy.var() (#1994)
Added missing parameter `ddof` for `GroupBy.std()` and `GroupBy.var()`. ```python >>> kdf = ks.DataFrame( ... { ... "a": [1, 2, 6, 4, 4, 6, 4, 3, 7], ... "b": [4, 2, 7, 3, 3, 1, 1, 1, 2], ... "c": [4, 2, 7, 3, None, 1, 1, 1, 2], ... "d": list("abcdefght"), ... }, ... index=[0, 1, 3, 5, 6, 8, 9, 9, 9], ... ) >>> kdf a b c d 0 1 4 4.0 a 1 2 2 2.0 b 3 6 7 7.0 c 5 4 3 3.0 d 6 4 3 NaN e 8 6 1 1.0 f 9 4 1 1.0 g 9 3 1 1.0 h 9 7 2 2.0 t # std >>> kdf.groupby("a").std(ddof=1) b c a 7 NaN NaN 6 4.242641 4.242641 1 NaN NaN 3 NaN NaN 2 NaN NaN 4 1.154701 1.414214 >>> kdf.groupby("a").std(ddof=0) b c a 7 0.000000 0.0 6 3.000000 3.0 1 0.000000 0.0 3 0.000000 0.0 2 0.000000 0.0 4 0.942809 1.0 # var >>> kdf.groupby("a").var(ddof=1) b c a 7 NaN NaN 6 18.000000 18.0 1 NaN NaN 3 NaN NaN 2 NaN NaN 4 1.333333 2.0 >>> kdf.groupby("a").var(ddof=0) b c a 7 0.000000 0.0 6 9.000000 9.0 1 0.000000 0.0 3 0.000000 0.0 2 0.000000 0.0 4 0.888889 1.0 ``` -
Adjust Series.mode to match pandas Series.mode (#1995)
Currently, Series.mode reserves the name of Series in the result, whereas pandas Series.mode doesn't: ``` >>> kser1 x 1 y 2 Name: z, dtype: int64 >>> kser1.mode() 0 1 1 2 Name: z, dtype: int64. # Reserve name >>> pser1 = kser1.to_pandas() >>> pser1.mode() 0 1 1 2 dtype: int64. # Not reserve name ``` In addition, unit tests are added.
Commits on Jan 10, 2021
-
Set upperbound xlrd<2.0.0 to fix read_excel test cases (#2001)
The current test cases are being failed as below, ``` E xlrd.biffh.XLRDError: Excel xlsx file; not supported ``` https://github.com/databricks/koalas/pull/1997/checks?check_run_id=1675264925 I referred to https://stackoverflow.com/questions/65254535/xlrd-biffh-xlrderror-excel-xlsx-file-not-supported
Commits on Jan 12, 2021
-
Optimize histogram calculation as a single pass (#1997)
This PR optimizes histogram plot in Koalas by unioning the transformed results and making it single pass. Previously, when the `DataFrame.plot.hist` is called, each column had to trigger each job. Now, we can do it in single pass even for `DataFrame`s. I also tested that it still result same:  
-
Refactor and extract hist calculation logic from matplotlib (#1998)
This PR extract histogram calculation logic from `matplotlib.py` to `core.py`. This PR is dependent on #1997
-
Support operations between Series and Index. (#1996)
Supports operations between `Series` and `Index`. ```py >>> kser = ks.Series([1, 2, 3, 4, 5, 6, 7]) >>> kidx = ks.Index([0, 1, 2, 3, 4, 5, 6]) >>> (kser + 1 + 10 * kidx).sort_index() 0 2 1 13 2 24 3 35 4 46 5 57 6 68 dtype: int64 >>> (kidx + 1 + 10 * kser).sort_index() 0 11 1 22 2 33 3 44 4 55 5 66 6 77 dtype: int64 ```
{kind=link}
{kind=link}
Commits on Jan 13, 2021
-
Implement (DataFrame|Series).plot.hist in plotly (#1999)
This PR implements `(DataFrame|Series).plot.hist` in plotly: This can be tested via: https://mybinder.org/v2/gh/HyukjinKwon/koalas/plotly-histogram?filepath=docs%2Fsource%2Fgetting_started%2F10min.ipynb Example: ```python # Koalas import databricks.koalas as ks ks.options.plotting.backend = "plotly" kdf = ks.DataFrame({ 'a c': [1, 2, 3, 4, 5, 6, 7, 8, 9, 15, 50], 'b': [2, 3, 4, 5, 7, 9, 10, 15, 10, 20, 20] }) (kdf + 100).plot.hist() # pandas import pandas as pd pd.options.plotting.backend = "plotly" pdf = pd.DataFrame({ 'a c': [1, 2, 3, 4, 5, 6, 7, 8, 9, 15, 50], 'b': [2, 3, 4, 5, 7, 9, 10, 15, 10, 20, 20] }) (pdf + 100).plot.hist() ```   NOTE that the output is a bit different because: - We use Spark for histogram calculation and it's a bit different from pandas' - Histogram plot in plotly cannot be directly used in our case but should work around by leveraging bar charts because we don't use plotly to calculate histogram, see https://plotly.com/python/histograms/.
-
Adjust data when all the values in a column are nulls. (#2004)
For Spark < 3.0, when all the values in a column are nulls, it will be `None` regardless of its data type. ```py >>> pdf = pd.DataFrame( ... { ... "a": [None, None, None, "a"], ... "b": [None, None, None, 1], ... "c": [None, None, None] + list(np.arange(1, 2).astype("i1")), ... "d": [None, None, None, 1.0], ... "e": [None, None, None, True], ... "f": [None, None, None] + list(pd.date_range("20130101", periods=1)), ... }, ... ) >>> >>> kdf = ks.from_pandas(pdf) >>> kdf.iloc[:-1] a b c d e f 0 None None None None None None 1 None None None None None None 2 None None None None None None ``` whereas for pandas: ```py >>> pdf.iloc[:-1] a b c d e f 0 None NaN NaN NaN None NaT 1 None NaN NaN NaN None NaT 2 None NaN NaN NaN None NaT ``` With Spark >= 3.0 seems fine: ```py >>> kdf.iloc[:-1] a b c d e f 0 None NaN NaN NaN None NaT 1 None NaN NaN NaN None NaT 2 None NaN NaN NaN None NaT ``` -
Implement Series.factorize() (#1972)
ref #1929 ``` >>> kser = ks.Series(['b', None, 'a', 'c', 'b']) >>> codes, uniques = kser.factorize() >>> codes 0 1 1 -1 2 0 3 2 4 1 dtype: int64 >>> uniques Index(['a', 'b', 'c'], dtype='object') >>> codes, uniques = kser.factorize(na_sentinel=None) >>> codes 0 1 1 3 2 0 3 2 4 1 dtype: int64 >>> uniques Index(['a', 'b', 'c', None], dtype='object') >>> codes, uniques = kser.factorize(na_sentinel=-2) >>> codes 0 1 1 -2 2 0 3 2 4 1 dtype: int64 >>> uniques Index(['a', 'b', 'c'], dtype='object') ```
{kind=link}
{kind=link}
Commits on Jan 14, 2021
-
Refactor to use one similar logic to call plot backends (#2005)
This PR proposes: - Remove `koalas_plotting_backends`. We don't currently have such mechanism like pandas-dev/pandas@e9a60bb - Load and use plotting backend in the same way: - If a plot module has `plot`, we use it after converting it to pandas instance. - if a plot module has `plot_koalas` (Koalas' `matplotlib` and `plotly` modules for example), we just pass Koalas instances to plot. Now `databricks.koalas.plot.plotly` and `databricks.koalas.plot.matplotlib` modules work like external plotting backends.
-
Extract box computing logic from matplotlib (#2006)
This PR moves core computation logic from matplotlib module to core module in plot.
Commits on Jan 15, 2021
-
Implement Series.plot.box (#2007)
This PR implements Series.plot.box with plotly. Note that DataFrame.plot.box is not already supported in Koalas yet. This can be tested via the link: https://mybinder.org/v2/gh/HyukjinKwon/koalas/plot-box-ser?filepath=docs%2Fsource%2Fgetting_started%2F10min.ipynb Note that you should manually install plotly to test with mybinder above: ``` %%bash pip install plotly ``` Example: ```python # Koalas from databricks import koalas as ks ks.options.plotting.backend = "plotly" kdf = ks.DataFrame({"a": [1, 2, 3, 4, 5, 6, 7, 8, 9, 15, 50],}, index=[0, 1, 3, 5, 6, 8, 9, 9, 9, 10, 10]) kdf.a.plot.box() # pandas import pandas as pd pd.options.plotting.backend = "plotly" pdf = pd.DataFrame({"a": [1, 2, 3, 4, 5, 6, 7, 8, 9, 15, 50],}, index=[0, 1, 3, 5, 6, 8, 9, 9, 9, 10, 10]) pdf.a.plot.box() ```   For the same reason as #1999, the output is slightly different from pandas'. I referred to "Box Plot With Precomputed Quartiles" in https://plotly.com/python/box-plots/
{kind=link}
{kind=link}
Commits on Jan 17, 2021
-
Extract kde computing logic from matplotlib (#2010)
This PR moves core computation logic (in kde) from matplotlib module to core module in plot.
Commits on Jan 19, 2021
-
Fix as_spark_type to not support "bigint". (#2011)
Fix `as_spark_type` to not support "bigint". The string "bigint" is not recognizable by `np.dtype` and it causes an unexpected error: ```py >>> import numpy as np >>> from databricks.koalas.typedef import as_spark_type >>> as_spark_type(np.dtype("datetime64[ns]")) Traceback (most recent call last): ... TypeError: data type "bigint" not understood ``` Also, it doesn't work in pandas: ```py >>> pd.Series([1, 2, 3], dtype="bigint") Traceback (most recent call last): ... TypeError: data type "bigint" not understood ```
Commits on Jan 20, 2021
-
Reuse as_spark_type in infer_pd_series_spark_type. (#2012)
Now that `as_spark_type` is good enough for Koalas, we should reuse it in `infer_pd_series_spark_type` to avoid inconsistency.
-
Implement DataFrame.insert (#1983)
ref #1929 Insert column into DataFrame at a specified location. ``` >>> kdf = ks.DataFrame([1, 2, 3]) >>> kdf.insert(0, 'x', 4) >>> kdf.sort_index() x 0 0 4 1 1 4 2 2 4 3 >>> from databricks.koalas.config import set_option, reset_option >>> set_option("compute.ops_on_diff_frames", True) >>> kdf.insert(1, 'y', [5, 6, 7]) >>> kdf.sort_index() x y 0 0 4 5 1 1 4 6 2 2 4 7 3 >>> kdf.insert(2, 'z', ks.Series([8, 9, 10])) >>> kdf.sort_index() x y z 0 0 4 5 8 1 1 4 6 9 2 2 4 7 10 3 >>> reset_option("compute.ops_on_diff_frames") ```
Commits on Jan 22, 2021
-
Set upperbound for pandas 1.2.0 (#2016)
Set upperbound for pandas 1.2.0 before we fully support pandas 1.2.0 refer #1987
-
Commits on Jan 26, 2021
-
Add a note about Databricks Community Edition (#2021)

{kind=link}
Commits on Jan 27, 2021
-
Add DataFrame/Series.align. (#2019)
Add `DataFrame/Series.align` with parameters `join`, `axis`, and `copy` supported. - https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.align.html - https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.align.html
Commits on Jan 28, 2021
-
Implemented ks.read_orc (#2017)
This PR proposes `ks.read_orc` to support creating `DataFrame` from ORC file. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_orc.html#pandas.read_orc ```python >>> ks.read_orc("example.orc") i32 i64 f bhello 0 0 0 0.0 people >>> pd.read_orc("example.orc") i32 i64 f bhello 0 0 0 0.0 people # with columns >>> ks.read_orc("example.orc", columns=["i32", "f"]) i32 f 0 0 0.0 >>> pd.read_orc("example.orc", columns=["i32", "f"]) i32 f 0 0 0.0 >>> ```
Commits on Jan 29, 2021
-
Implemented DataFrame.to_orc (#2024)
This PR proposes `DataFrame.to_orc` to write the ORC file. pandas doesn't support this, but we do provide it for convenience, though.
Commits on Feb 1, 2021
-
[HOTFIX] set upperbounds numpy to fix CI failure (#2027)
This PR is for quickly fix the `mypy` test failure to unblock other PRs caused by NumPy 1.20.0 release. This upper bound should be removed again when finishing & merging #2026
-
Commits on Feb 2, 2021
-
Change matplotlib as an optional dependency (#2029)
This PR proposes to change matplotlib as an optional dependency. ```python >>> from databricks import koalas as ks >>> ks.range(100).plot.bar() Traceback (most recent call last): ... ImportError: matplotlib is required for plotting when the default backend 'matplotlib' is selected. ``` Resolves #issues
-
Add Int64Index, Float64Index, DatetimeIndex. (#2025)
Adds `Int64Index`, `Float64Index`, and `DatetimeIndex` as a placeholder. We should still add specific attributes and methods in the following PRs. Before: ```py >>> kdf = ks.DataFrame([1,2,3]) >>> type(kdf.index) <class 'databricks.koalas.indexes.Index'> ``` After: ```py >>> type(kdf.index) <class 'databricks.koalas.indexes.numeric.Int64Index'> ```
-
JessicaTegner/pypandoc#154 is merged and released. We can remove the hack for file name handling
-
Upgrade pandas to 1.2 in CI (#1987)
Since pandas 1.2 was released, upgraded pandas version in CI to follow pandas' behavior. https://pandas.pydata.org/pandas-docs/version/1.2.0/whatsnew/v1.2.0.html https://pandas.pydata.org/pandas-docs/version/1.2.1/whatsnew/v1.2.1.html
-
Preserve index for statistical functions with axis==1. (#2036)
Preserves `index` for statistical functions with `axis==1`. ```py >>> kdf = ks.DataFrame( ... { ... "A": [1, -2, 3, -4, 5], ... "B": [1.0, -2, 3, -4, 5], ... "C": [-6.0, -7, -8, -9, 10], ... "D": [True, False, True, False, False], ... }, ... index=[10, 20, 30, 40, 50] ... ) >>> kdf.count(axis=1) 10 4 20 4 30 4 40 4 50 4 dtype: int64 ``` whereas: ```py >>> ks.set_option("compute.shortcut_limit", 2) >>> kdf.count(axis=1) 0 4 1 4 2 4 3 4 4 4 dtype: int64 ``` After: ```py >>> ks.set_option("compute.shortcut_limit", 2) >>> kdf.count(axis=1) 10 4 20 4 30 4 40 4 50 4 dtype: int64 ```
There are no files selected for viewing