Delete files older than the lowest_cleanup_slot in LedgerCleanupService::cleanup_ledger#26651
Delete files older than the lowest_cleanup_slot in LedgerCleanupService::cleanup_ledger#26651yhchiang-sol merged 1 commit intosolana-labs:masterfrom yhchiang-sol:delete_file_in_range
Conversation
|
I had actually noticed this method and been thinking about it too 😁 ; however, the following bit of documentation makes me suspect of whether it will work well for our case:
We call The idea that I had been mulling over was to call The only problem case I can think of here is the one you described on one of our calls that follows a sequence like this:
However, recall that
If their is some subtlety here where the |
|
Oh wow, that's a quick response! I'm still actually baking the PR and just updated it. The updated PR does range delete first, then the delete_file_in_range, as we want to make sure the write-batch went through first -- I should probably check the result of the write_batch before issuing delete_file_in_range. I will update the PR.
Yes, delete_file_in_range works best when we pass My follow-up question is: is it always safe to do |
Ha, just happened to see it near the top on PR's tab
No, I don't think so. One example that comes to mind immediately is when we purge a slot from I think |
 yhchiang-sol
left a comment
yhchiang-sol
left a comment
There was a problem hiding this comment.
Made the following changes:
- LedgerCleanupService::cleanup_ledger becomes the only place that will issue purge_files_in_range.
- The cleanup range in LedgerCleanupService::cleanup_ledger is changed from
(the_oldest_slot_in_db, lowest_slot_to_purge) to (0, lowest_slot_to_purge).
(i.e., anything older than or equal to lowest_slot_to_purge will be purged.) - blockstore::run_purge will run delete_file_in_range if the starting slot is 0.
|
Will circle back for a proper review, but it might be nice to get some runtime on a validator to see if this functions as expected. Two things I'd expect:
|
|
Currently testing. Will share the result once I have enough data points. |
|
Re-running the experiments with the minimum |
|
The experiment with Below are two different recent data points showing ledger size (the green one) constantly stays at ~230GB with this PR while it continues growing in the master branch (the purple one):
The validator log that includes the purge and disk utilization information also shows the same thing: the one with this PR has disk utilization capped at the same level while the disk utilization on the master branch keeps growing. master branch with this PR (the ERROR in the log is my debug log): |
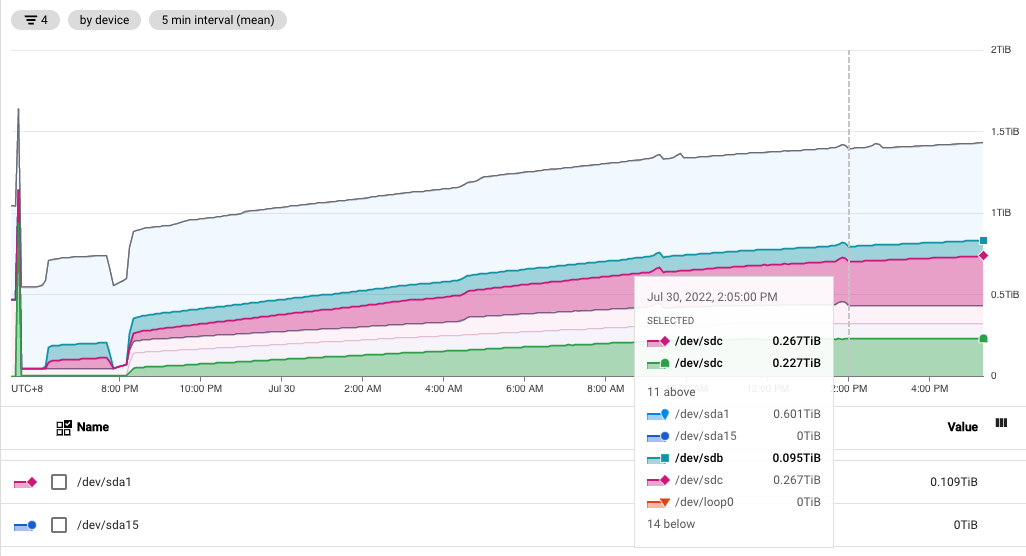
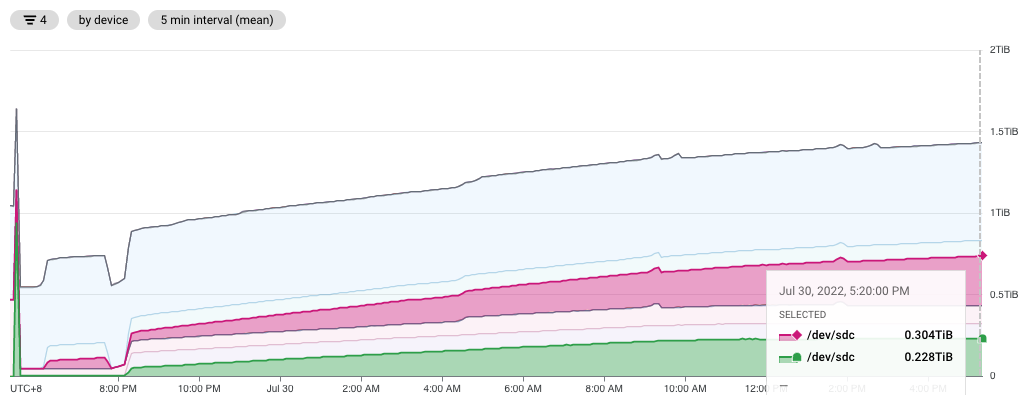
|
Repeated the experiment with In other words, this PR is able to reduce ~33% of the ledger disk space. Below is the disk space usage graph of the two builds (sorry that I failed to start two instances simultaneously, but the experiment should still be valid.) I will go ahead and run this PR with the default |
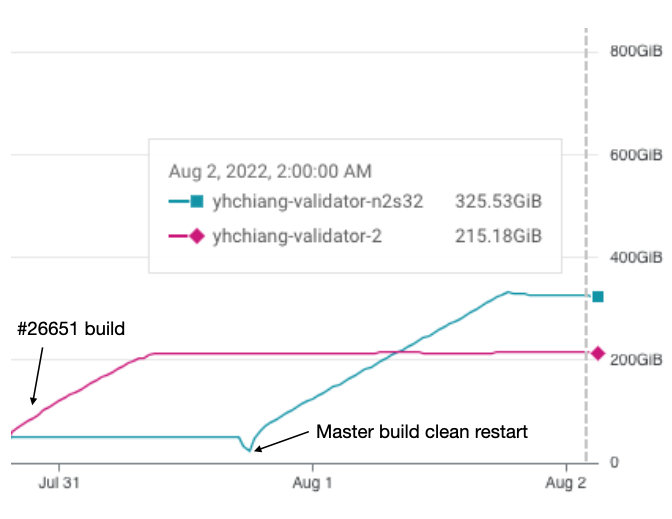
Nice, definitely a meaningful improvement!
I agree, results valid despite offset start times.
Dumping some DM's, the numbers (210/320 GB) seemed a bit large. Upon further inspection, we realized that this number is inclusive of the With this in mind, above numbers are roughly: That works out to > 40%, so even better than the 33% number that was previously mentioned 😄 |
|
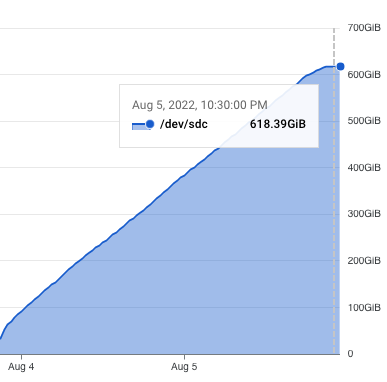
Here're the numbers for the default The ledger size is capped at ~565GB (607402138084 bytes), which is slightly smaller than what we previously predicted. Together with the account index, it is ~618GB.
As for the suggested ledger disk size for the default settings, I previously discussed it with @steviez, and we think 750GB would be a good number as it gives us ~20% additional buffer to handle spikes and some room for the growth of account index. |
 steviez
left a comment
steviez
left a comment
There was a problem hiding this comment.
Looks good to me once you fix the typo. I think this was already the plan, but we can update docs in a different PR.
Additionally, I think this might be a candidate for backport, definitely for v1.11, and maybe even for v1.10. Arguably, this is a bug fix as we allow the ledger to expand to much larger footprint than what the docs state. I saw some chatter in Discord about backports / audits; I don't think there is any official policy change, but might be good to post a question in Discord and check
…ce::cleanup_ledger (solana-labs#26651) #### Problem LedgerCleanupService requires compactions to propagate & digest range-delete tombstones to eventually reclaim disk space. #### Summary of Changes This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with fewer IOps. Experimental results on mainnet validators show that the PR can effectively reduce 33% to 40% ledger disk size.
|
fwiw, I ran bench-tps on this and did not see any significant difference. |
Thanks for the information, @jeffwashington. The change requires blockstore to hit the limit-ledger-size before we can see any difference as the PR improves the way to clean up blockstore when it hits the configured size limit. I will experiment with bench-tps a bit. |
…ce::cleanup_ledger (#26651) #### Problem LedgerCleanupService requires compactions to propagate & digest range-delete tombstones to eventually reclaim disk space. #### Summary of Changes This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with fewer IOps. Experimental results on mainnet validators show that the PR can effectively reduce 33% to 40% ledger disk size. (cherry picked from commit 99ef218)
…ce::cleanup_ledger (backport #26651) (#27304) Delete files older than the lowest_cleanup_slot in LedgerCleanupService::cleanup_ledger (#26651) #### Problem LedgerCleanupService requires compactions to propagate & digest range-delete tombstones to eventually reclaim disk space. #### Summary of Changes This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with fewer IOps. Experimental results on mainnet validators show that the PR can effectively reduce 33% to 40% ledger disk size. (cherry picked from commit 99ef218) Co-authored-by: Yueh-Hsuan Chiang <93241502+yhchiang-sol@users.noreply.github.com>
#### Problem Previously before #26651, our LedgerCleanupService needs RocksDB background compactions to reclaim ledger disk space via our custom CompactionFilter. However, since RocksDB's compaction isn't smart enough to know which file to pick, we rely on the 1-day compaction period so that each file will be forced to be compacted once a day so that we can reclaim ledger disk space in time. The downside of this is each ledger file will be rewritten once per day. #### Summary of Changes As #26651 makes LedgerCleanupService actively delete those files whose entire slot-range is older than both --limit-ledger-size and the current root, we can remove the 1-day compaction period and get rid of the daily ledger file rewrite. The results on mainnet-beta shows that this PR reduces ~20% write-bytes-per-second and reduces ~50% read-bytes-per-second on ledger disk.
…ce::cleanup_ledger (#26651) #### Problem LedgerCleanupService requires compactions to propagate & digest range-delete tombstones to eventually reclaim disk space. #### Summary of Changes This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with fewer IOps. Experimental results on mainnet validators show that the PR can effectively reduce 33% to 40% ledger disk size. (cherry picked from commit 99ef218)
…ce::cleanup_ledger (backport #26651) (#28721) * Delete files older than the lowest_cleanup_slot in LedgerCleanupService::cleanup_ledger (#26651) #### Problem LedgerCleanupService requires compactions to propagate & digest range-delete tombstones to eventually reclaim disk space. #### Summary of Changes This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with fewer IOps. Experimental results on mainnet validators show that the PR can effectively reduce 33% to 40% ledger disk size. (cherry picked from commit 99ef218) * Fixup Co-authored-by: Yueh-Hsuan Chiang <93241502+yhchiang-sol@users.noreply.github.com> Co-authored-by: Steven Czabaniuk <steven@solana.com>
Periodic compaction was previously disabled on all columns in solana-labs#27571 in favor of the delete_file_in_range() approach that solana-labs#26651 introduced. However, several columns still rely on periodic compaction to reclaim storage. Namely, the TransactionStatus and AddressSignatures columns as these columns contain a slot in their key, but as the secondary index. The result of periodic compaction not running on these columns is that no storage space was being reclaimed from columns. This is obviously bad and would lead to a node eventually running of storage space and crashing. This PR reintroduces periodic compaction, but only for the columns that need it.
Periodic compaction was previously disabled on all columns in solana-labs#27571 in favor of the delete_file_in_range() approach that solana-labs#26651 introduced. However, several columns still rely on periodic compaction to reclaim storage. Namely, the TransactionStatus and AddressSignatures columns as these columns contain a slot in their key, but as the secondary index. The result of periodic compaction not running on these columns is that no storage space was being reclaimed from columns. This is obviously bad and would lead to a node eventually running of storage space and crashing. This PR reintroduces periodic compaction, but only for the columns that need it.
Periodic compaction was previously disabled on all columns in #27571 in favor of the delete_file_in_range() approach that #26651 introduced. However, several columns still rely on periodic compaction to reclaim storage. Namely, the TransactionStatus and AddressSignatures columns, as these columns contain a slot in their key, but as a non-primary index. The result of periodic compaction not running on these columns is that no storage space is being reclaimed from columns. This is obviously bad and would lead to a node eventually running of storage space and crashing. This PR reintroduces periodic compaction, but only for the columns that need it.
Periodic compaction was previously disabled on all columns in #27571 in favor of the delete_file_in_range() approach that #26651 introduced. However, several columns still rely on periodic compaction to reclaim storage. Namely, the TransactionStatus and AddressSignatures columns, as these columns contain a slot in their key, but as a non-primary index. The result of periodic compaction not running on these columns is that no storage space is being reclaimed from columns. This is obviously bad and would lead to a node eventually running of storage space and crashing. This PR reintroduces periodic compaction, but only for the columns that need it. (cherry picked from commit d73fa1b)
Problem
LedgerCleanupService requires compactions to propagate & digest range-delete tombstones
to eventually reclaim disk space.
Summary of Changes
This PR makes LedgerCleanupService::cleanup_ledger delete any file whose slot-range is
older than the lowest_cleanup_slot. This allows us to reclaim disk space more often with
fewer IOps because 1) we don't need to wait for rocksdb compactions, and 2) the purge
is done by deleting old files without iterating the checking every single key inside the file
using the compaction filter.
To make the above cleanup consistent with our range-deletion and reclaim disk space
more effectively, the cleanup range in LedgerCleanupService::cleanup_ledger has been
changed from (the-oldest-slot-in-db, lowest_cleanup_slot) to (0, lowest_cleanup_slot).
The detailed reason for this is also commented in the code.