[pull] master from apache:master #22
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
### What changes were proposed in this pull request? This pr aims upgrade scala-maven-plugin to 4.7.2 ### Why are the changes needed? This version set `-release` instead of `-target` to clean up a deprecation compilation warning for Scala 2.13.9 - davidB/scala-maven-plugin#648 The all change from 4.7.1 as follows: - davidB/scala-maven-plugin@4.7.1...4.7.2 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #38524 from LuciferYang/SPARK-41024. Authored-by: yangjie01 <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? This pr aims to fix Scala 2.13 Mima check after #38427: - https://github.com/apache/spark/actions/runs/3401306708/jobs/5656324784 ``` [error] spark-core: Failed binary compatibility check against org.apache.spark:spark-core_2.13:3.3.0! Found 5 potential problems (filtered 948) [error] * method blocks()scala.collection.immutable.Seq in class org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest has a different result type in current version, where it is scala.collection.Seq rather than scala.collection.immutable.Seq [error] filter with: ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest.blocks") [error] * method copy(org.apache.spark.storage.BlockManagerId,scala.collection.immutable.Seq,Boolean)org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest in class org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest's type is different in current version, where it is (org.apache.spark.storage.BlockManagerId,scala.collection.Seq,Boolean)org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest instead of (org.apache.spark.storage.BlockManagerId,scala.collection.immutable.Seq,Boolean)org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest [error] filter with: ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest.copy") [error] * synthetic method copy$default$2()scala.collection.immutable.Seq in class org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest has a different result type in current version, where it is scala.collection.Seq rather than scala.collection.immutable.Seq [error] filter with: ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest.copy$default$2") [error] * method this(org.apache.spark.storage.BlockManagerId,scala.collection.immutable.Seq,Boolean)Unit in class org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest's type is different in current version, where it is (org.apache.spark.storage.BlockManagerId,scala.collection.Seq,Boolean)Unit instead of (org.apache.spark.storage.BlockManagerId,scala.collection.immutable.Seq,Boolean)Unit [error] filter with: ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest.this") [error] * method apply(org.apache.spark.storage.BlockManagerId,scala.collection.immutable.Seq,Boolean)org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest in object org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest in current version does not have a correspondent with same parameter signature among (org.apache.spark.storage.BlockManagerId,scala.collection.Seq,Boolean)org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest, (java.lang.Object,java.lang.Object,java.lang.Object)java.lang.Object [error] filter with: ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.storage.ShuffleBlockFetcherIterator#FetchRequest.apply") [error] java.lang.RuntimeException: Failed binary compatibility check against org.apache.spark:spark-core_2.13:3.3.0! Found 5 potential problems ``` ### Why are the changes needed? Fix Scala 2.13 daily build. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA - Manual test **Scala 2.12** ``` dev/mima -Pscala-2.12 ``` **Scala 2.13** ``` dev/change-scala-version.sh 2.13 dev/mima -Pscala-2.13 ``` Closes #38525 from LuciferYang/SPARK-40950-FOLLOWUP. Authored-by: yangjie01 <[email protected]> Signed-off-by: Sean Owen <[email protected]>
### What changes were proposed in this pull request? I changed some grammatical issues in the documentation. One potential change could be debatable though so please take a look. https://spark.apache.org/docs/latest/tuning.html ### Why are the changes needed? Some grammatical mistakes in the documentation. ### Does this PR introduce _any_ user-facing change? Yes, this corrects some issues in documentation related to Tuning Spark. The following changes were made Check if there are too many garbage collections by collecting GC stats. If a full GC is invoked multiple times ~~for~~ before a task completes, it means that there isn't enough memory available for executing tasks. with `-XX:G1HeapRegionSize`. (added missing period). we can estimate the size of Eden to be `4*3*128MiB`. (added the to estimate the size--this one I guess debatable) ### How was this patch tested? No tests added as this was markdown documentation for the user facing page. Closes #38499 from dwsmith1983/master. Lead-authored-by: Dustin William Smith <[email protected]> Co-authored-by: dustin <[email protected]> Signed-off-by: Sean Owen <[email protected]>
…EXISTS, INDEX_ALREADY_EXISTS, INDEX_NOT_FOUND, ROUTINE_NOT_FOUND ### What changes were proposed in this pull request? This PR aims to test the error classes, include: 1. DEFAULT_DATABASE_NOT_EXISTS 2. INDEX_ALREADY_EXISTS 3. INDEX_NOT_FOUND 4. ROUTINE_NOT_FOUND ### Why are the changes needed? The changes improve the error framework. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? 1. Add new UT. 2. Update existed UT. 3. Pass GA. Closes #38522 from panbingkun/index_test. Authored-by: panbingkun <[email protected]> Signed-off-by: Max Gekk <[email protected]>
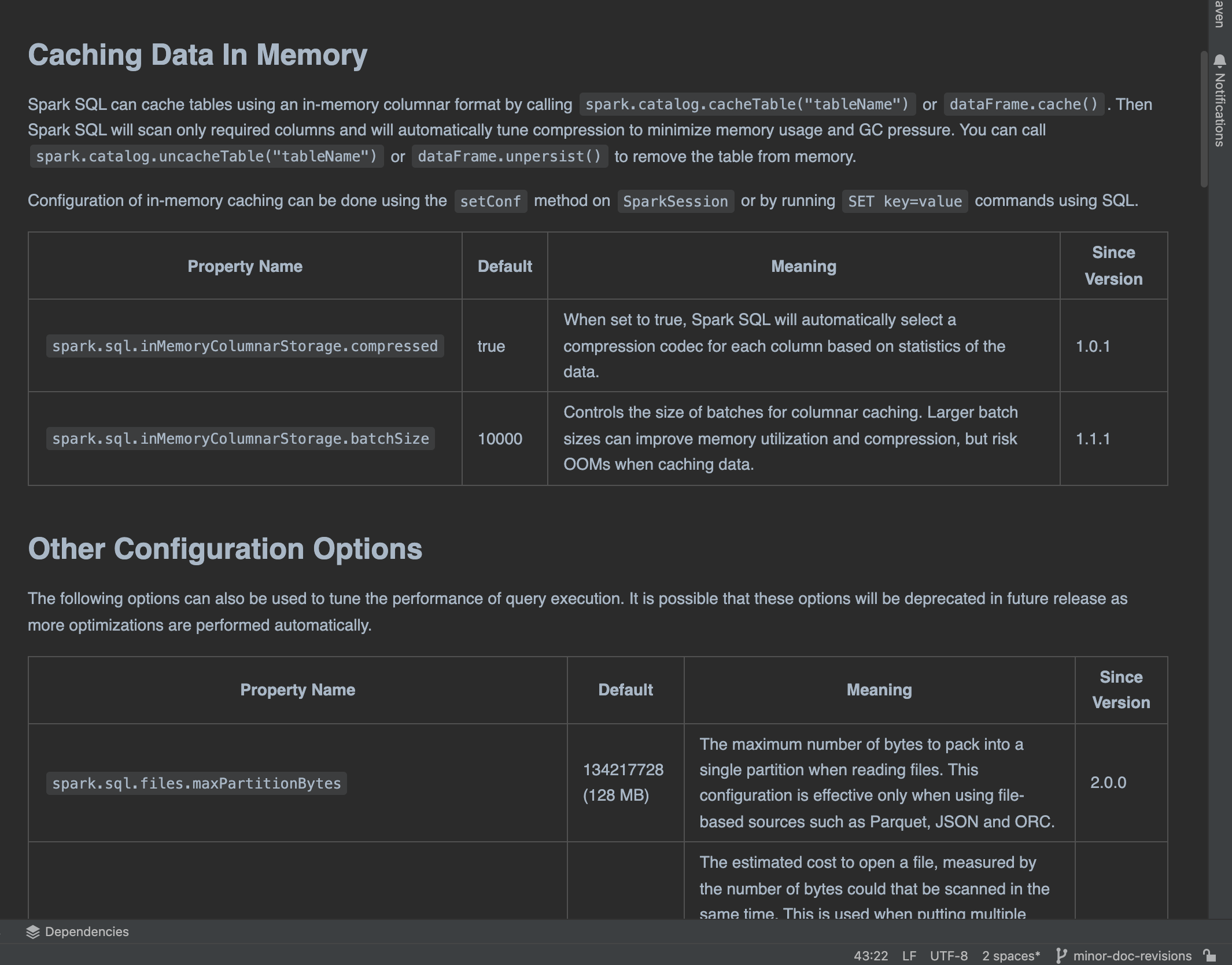
…adability and grammar ### What changes were proposed in this pull request? I made some small grammar fixes related to dependent clause followed but independent clauses, starting a sentence with an introductory phrase, using the plural with when are is present in the sentence, and other small fixes to improve readability. https://spark.apache.org/docs/latest/sql-performance-tuning.html <img width="1065" alt="Screenshot 2022-11-04 at 15 24 17" src="https://user-images.githubusercontent.com/7563201/199998862-d9418bc1-2fcd-4eff-be8e-af412add6946.png"> ### Why are the changes needed? These changes improve the readability of the Spark documentation for new users or those studying up. ### Does this PR introduce _any_ user-facing change? Yes, these changes impact the spark documentation. ### How was this patch tested? No test were created as these changes were solely in markdown. Closes #38510 from dwsmith1983/minor-doc-revisions. Lead-authored-by: Dustin William Smith <[email protected]> Co-authored-by: dustin <[email protected]> Co-authored-by: Dustin Smith <[email protected]> Signed-off-by: Sean Owen <[email protected]>
{kind=link}
pull bot
pushed a commit
that referenced
this pull request
Jul 3, 2025
…pressions in `buildAggExprList` ### What changes were proposed in this pull request? Trim aliases before matching Sort/Having/Filter expressions with semantically equal expression from the Aggregate below in `buildAggExprList` ### Why are the changes needed? For a query like: ``` SELECT course, year, GROUPING(course) FROM courseSales GROUP BY CUBE(course, year) ORDER BY GROUPING(course) ``` Plan after `ResolveReferences` and before `ResolveAggregateFunctions` looks like: ``` !Sort [cast((shiftright(tempresolvedcolumn(spark_grouping_id#18L, spark_grouping_id, false), 1) & 1) as tinyint) AS grouping(course)#22 ASC NULLS FIRST], true +- Aggregate [course#19, year#20, spark_grouping_id#18L], [course#19, year#20, cast((shiftright(spark_grouping_id#18L, 1) & 1) as tinyint) AS grouping(course)#21 AS grouping(course)#15] .... ``` Because aggregate list has `Alias(Alias(cast((shiftright(spark_grouping_id#18L, 1) & 1) as tinyint))` expression from `SortOrder` won't get matched as semantically equal and it will result in adding an unnecessary `Project`. By stripping inner aliases from aggregate list (that are going to get removed anyways in `CleanupAliases`) we can match `SortOrder` expression and resolve it as `grouping(course)#15` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#51339 from mihailotim-db/mihailotim-db/fix_inner_aliases_semi_structured. Authored-by: Mihailo Timotic <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
See Commits and Changes for more details.
Created by pull[bot]
pull[bot]
Can you help keep this open source service alive? 💖 Please sponsor : )