[MINOR][DOC] revisions for spark sql performance tuning to improve readability and grammar #38510
Conversation
…k completes, as it sounds strange
…roadcasting large variables)
…points of data locality didnt have commas or periods but periods were being used for multiple sentences in a bullet points. I opted for periods but could be commas with last one using and then period
|
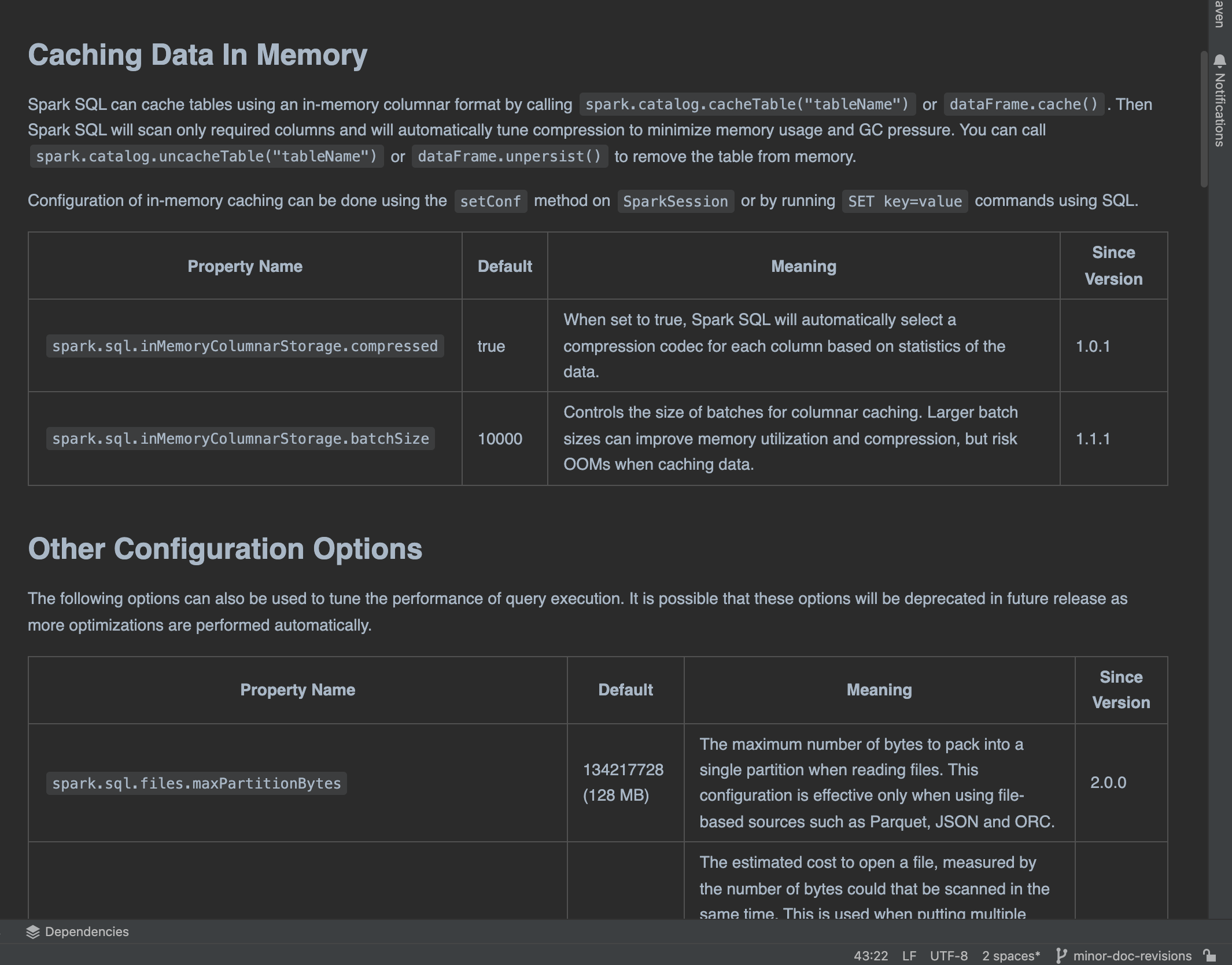
@itholic I was going over another topic and made some updates on sql performance tuning as well. I added a screenshot of the markdown. This how you want it correct? |
|
Can one of the admins verify this patch? |
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
OK, any other related files you want to check while your'e here?
I am doing some studying so not sure what other docs I will read and when. |
|
Anyone know why it failed this run? None of code has been touched. |
|
Yeah it's not related, looks like an error with the master branch right now. We can wait a bit for someone to fix that |
|
@srowen masters seems to be fine now. I merged mastered into my branch to see if it will fix the tests. |
|
@srowen is the failure related to the bot tagging of connect? There is some connect file that was added after this tag. |
|
Weird, the error is on code that isn't in the repo (now). Can you fully rebase and force-push your changes? |
…e number of bytes <that> could be scanned in the same time; I added that but still this sentence just seems off
… above preceeded it. another option would be to keep same as a above and remove the preceeding statement, but I believe this makes more sense to keep the actual instruction
…ay: Coalesce hints allow Spark SQL users to control the number of output files just like coalesce, repartition and repartitionByRange in the Dataset API,
…, we are using are which is plural so we need to use is or talk in the plural.
add suggestion from @srowen
e0ba562 to
5a63e51
Compare
removed file that shouldn't be in the repo
|
@srowen so the streaming test suite passed now so it should be fine now. |
|
Merged to master |
|
Late LGTM. |
…adability and grammar ### What changes were proposed in this pull request? I made some small grammar fixes related to dependent clause followed but independent clauses, starting a sentence with an introductory phrase, using the plural with when are is present in the sentence, and other small fixes to improve readability. https://spark.apache.org/docs/latest/sql-performance-tuning.html <img width="1065" alt="Screenshot 2022-11-04 at 15 24 17" src="https://user-images.githubusercontent.com/7563201/199998862-d9418bc1-2fcd-4eff-be8e-af412add6946.png"> ### Why are the changes needed? These changes improve the readability of the Spark documentation for new users or those studying up. ### Does this PR introduce _any_ user-facing change? Yes, these changes impact the spark documentation. ### How was this patch tested? No test were created as these changes were solely in markdown. Closes apache#38510 from dwsmith1983/minor-doc-revisions. Lead-authored-by: Dustin William Smith <[email protected]> Co-authored-by: dustin <[email protected]> Co-authored-by: Dustin Smith <[email protected]> Signed-off-by: Sean Owen <[email protected]>
{kind=link}
What changes were proposed in this pull request?
I made some small grammar fixes related to dependent clause followed but independent clauses, starting a sentence with an introductory phrase, using the plural with when are is present in the sentence, and other small fixes to improve readability.
https://spark.apache.org/docs/latest/sql-performance-tuning.html
Why are the changes needed?
These changes improve the readability of the Spark documentation for new users or those studying up.
Does this PR introduce any user-facing change?
Yes, these changes impact the spark documentation.
How was this patch tested?
No test were created as these changes were solely in markdown.