[SPARK-41423][CORE] Protobuf serializer for StageDataWrapper#39192
[SPARK-41423][CORE] Protobuf serializer for StageDataWrapper#39192panbingkun wants to merge 17 commits intoapache:masterfrom
Conversation
|
Waiting for me to add new UT. |
|
|
||
| repeated int64 rdd_ids = 43; | ||
| repeated AccumulableInfo accumulator_updates = 44; | ||
| map<int64, TaskData> tasks = 45; |
There was a problem hiding this comment.
optional map is not supported by pb
There was a problem hiding this comment.
I see, hmm... should we encapsulate this map?
such as
optional TaskMap tasks = 45;
message TaskMap {
map<int64, TaskData> tasks = 1;
}
also cc @gengliangwang
There was a problem hiding this comment.
Simply a map is OK here. An empty map should make no difference with None here.
| val description = | ||
| getOptional(binary.hasDescription, () => weakIntern(binary.getDescription)) | ||
| val accumulatorUpdates = Utils.deserializeAccumulableInfos(binary.getAccumulatorUpdatesList) | ||
| val tasks = MapUtils.isEmpty(binary.getTasksMap) match { |
There was a problem hiding this comment.
optional map is not supported by pb
|
Can one of the admins verify this patch? |
|
also cc @techaddict |
| } | ||
|
|
||
| message StageData { | ||
| enum StageStatus { |
There was a problem hiding this comment.
Why StageStatus designed as StageData inside enum ?
There was a problem hiding this comment.
If StageStatus is defined outside, the error message is as follows:
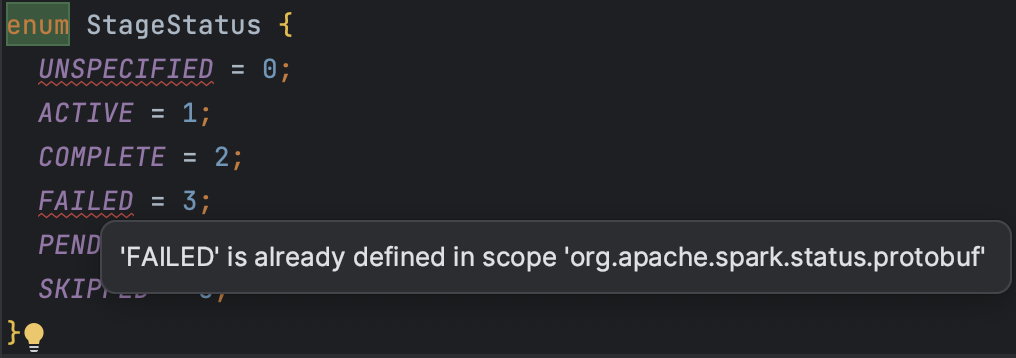
Then If StageStatus is defined as follows:
enum StageStatus {
STAGE_STATUS_UNSPECIFIED = 0;
STAGE_STATUS_ACTIVE = 1;
STAGE_STATUS_COMPLETE = 2;
STAGE_STATUS_FAILED = 3;
STAGE_STATUS_PENDING = 4;
STAGE_STATUS_SKIPPED = 5;
}
The Code of Serializer and Deerializer will be very ugly!
Will have to handle the operations of adding prefix and deleting prefix.
There was a problem hiding this comment.
Similarly, the enum definition of JobExecutionStatus seems more reasonable in JobData ?
There was a problem hiding this comment.
JobExecutionStatus is used in SQLExecutionUIData. So it can't be moved into JobData
There was a problem hiding this comment.
As described in https://github.com/apache/spark/pull/39270/files, UNSPECIFIED in StageStatus should change to STAGE_STATUS_UNSPECIFIED and moved out of StageData
There was a problem hiding this comment.
Ok, Let us follow code style(https://developers.google.com/protocol-buffers/docs/style#enums):
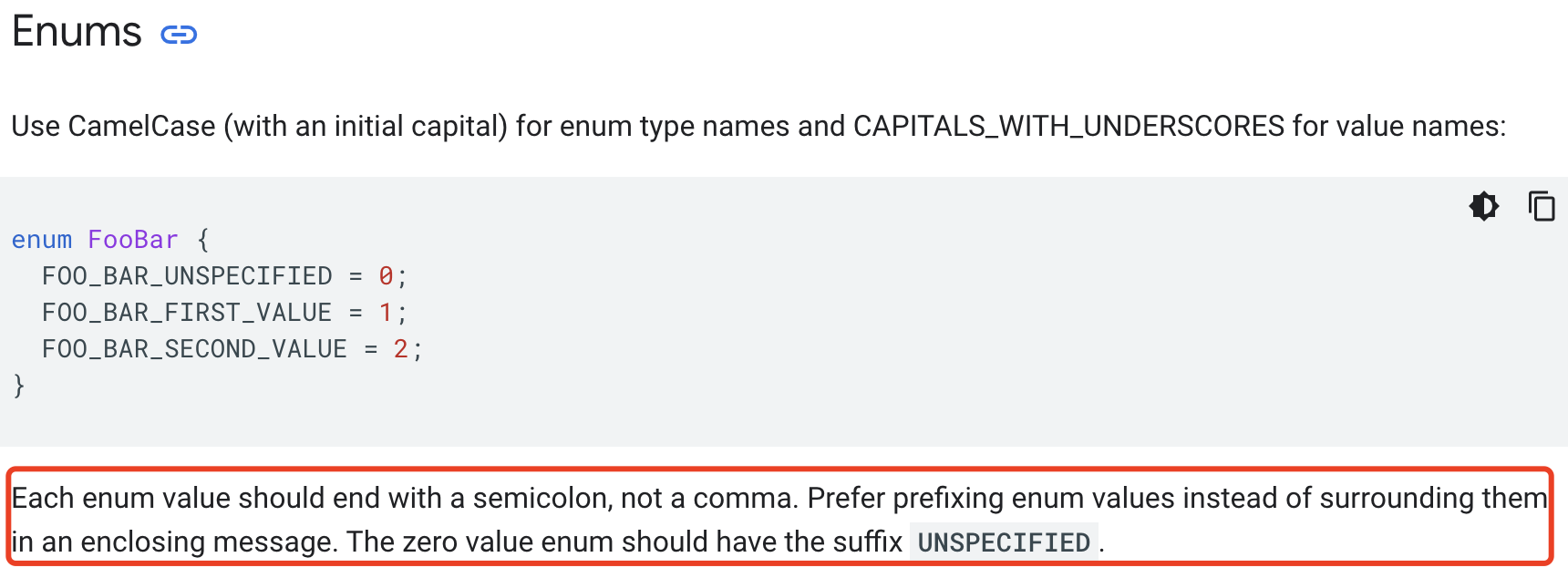
There was a problem hiding this comment.
New pr for JobExecutionStatus: #39286
@gengliangwang @LuciferYang
|
|
||
| repeated int64 rdd_ids = 43; | ||
| repeated AccumulableInfo accumulator_updates = 44; | ||
| map<int64, TaskData> tasks = 45; |
There was a problem hiding this comment.
I see, hmm... should we encapsulate this map?
such as
optional TaskMap tasks = 45;
message TaskMap {
map<int64, TaskData> tasks = 1;
}
also cc @gengliangwang
| repeated int64 rdd_ids = 43; | ||
| repeated AccumulableInfo accumulator_updates = 44; | ||
| map<int64, TaskData> tasks = 45; | ||
| map<string, ExecutorStageSummary> executor_summary = 46; |
| stageData.rddIds.foreach(id => stageDataBuilder.addRddIds(id.toLong)) | ||
| stageData.accumulatorUpdates.foreach { update => | ||
| stageDataBuilder.addAccumulatorUpdates(Utils.serializeAccumulableInfo(update)) | ||
| } |
There was a problem hiding this comment.
I think there are 3 choices for the definition of serializeAccumulableInfo function:
- Move it from class
TaskDataWrapperSerializerto companion objectTaskDataWrapperSerializer - Move it from class
TaskDataWrapperSerializerto objectAccumulableInfoSerializer - Keep the status quo and let
StageDataWrapperSerializerhold aTaskDataWrapperSerializerinstance
Similar suggestions for deserializeAccumulableInfo\serializeExecutorStageSummary\deserializeExecutorStageSummary and I think Utils should be a more general functions
There was a problem hiding this comment.
+1 for AccumulableInfoSerializer
There was a problem hiding this comment.
Ok, let me do it.
|
This is a big one. @panbingkun Thanks for working on it! |
|
|
||
| object AccumulableInfoSerializer { | ||
|
|
||
| private[protobuf] def serializeAccumulableInfo( |
There was a problem hiding this comment.
serializeAccumulableInfo -> serialize
| builder.build() | ||
| } | ||
|
|
||
| private[protobuf] def deserializeAccumulableInfos( |
There was a problem hiding this comment.
deserializeAccumulableInfos -> deserialize,
nit: I prefer to deserialize(info AccumulableInfo), looks more generic, but now is also ok
|
|
||
| private[protobuf] def deserializeAccumulableInfos( | ||
| updates: JList[StoreTypes.AccumulableInfo]): ArrayBuffer[AccumulableInfo] = { | ||
| val accumulatorUpdates = new ArrayBuffer[AccumulableInfo]() |
|
|
||
| override val supportClass: Class[_] = classOf[StageDataWrapper] | ||
|
|
||
| override def serialize(input: Any): Array[Byte] = |
There was a problem hiding this comment.
we can merge the two serialize to one
| val executorSummary = MapUtils.isEmpty(binary.getExecutorSummaryMap) match { | ||
| case true => None | ||
| case _ => Some(binary.getExecutorSummaryMap.asScala.mapValues( | ||
| ExecutorStageSummarySerializer.deserializeExecutorStageSummary(_)).toMap |
There was a problem hiding this comment.
can convertible to a method value
| case _ => Some(binary.getTasksMap.asScala.map( | ||
| entry => (entry._1.toLong, deserializeTaskData(entry._2))).toMap) | ||
| } | ||
| val executorSummary = MapUtils.isEmpty(binary.getExecutorSummaryMap) match { |
There was a problem hiding this comment.
just true and false, I prefer to if {} else {}
| new ExecutorPeakMetricsDistributions( | ||
| quantiles = binary.getQuantilesList.asScala.map(_.toDouble).toIndexedSeq, | ||
| executorMetrics = binary.getExecutorMetricsList.asScala.map( | ||
| ExecutorMetricsSerializer.deserialize(_)).toIndexedSeq |
There was a problem hiding this comment.
can convertible to a method value
| launchTime = new Date(binary.getLaunchTime), | ||
| resultFetchStart = resultFetchStart, | ||
| duration = duration, | ||
| executorId = weakIntern(binary.getExecutorId), |
There was a problem hiding this comment.
When should we use weakIntern? Seems not all serializers use it, will this affect performance?
For example, when new AccumulableInfo in AccumulableInfoSerializer, we didn't use weakIntern
There was a problem hiding this comment.
For consistency, we use weak here, eg:
As far as I know, when the field is of type string (not include map<string....>)
| import org.apache.spark.status.api.v1.AccumulableInfo | ||
| import org.apache.spark.status.protobuf.Utils.getOptional | ||
|
|
||
| object AccumulableInfoSerializer { |
There was a problem hiding this comment.
Let's put the private[protobuf] before the object AccumulableInfoSerializer
There was a problem hiding this comment.
So that we don't need to have private[protobuf] before each method
|
|
||
| object ExecutorStageSummarySerializer { | ||
|
|
||
| private[protobuf] def serialize(input: ExecutorStageSummary): StoreTypes.ExecutorStageSummary = { |
|
|
||
| import org.apache.spark.status.api.v1.StageStatus | ||
|
|
||
| object StageStatusSerializer { |
| } | ||
| } | ||
|
|
||
| private def assert(result: TaskMetrics, input: TaskMetrics): Unit = { |
There was a problem hiding this comment.
nit: rename all the assert methods as checkAnwser(result, expected)?
 gengliangwang
left a comment
gengliangwang
left a comment
There was a problem hiding this comment.
LGTM except a few minor comments
|
@panbingkun Thanks for the work, merging to master |
…atorUpdates for Scala 2.13 ### What changes were proposed in this pull request? This PR is a followup of #39192 that excludes `StageData.rddIds` and `StageData.accumulatorUpdates` for Scala 2.13 ### Why are the changes needed? To recover the Scala 2.13 build. It is currently broken (https://github.com/apache/spark/actions/runs/3824617107/jobs/6506925003): ``` [error] spark-core: Failed binary compatibility check against org.apache.spark:spark-core_2.13:3.3.0! Found 3 potential problems (filtered 997) [error] * method rddIds()scala.collection.immutable.Seq in class org.apache.spark.status.api.v1.StageData has a different result type in current version, where it is scala.collection.Seq rather than scala.collection.immutable.Seq [error] filter with: ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.status.api.v1.StageData.rddIds") [error] * method accumulatorUpdates()scala.collection.immutable.Seq in class org.apache.spark.status.api.v1.StageData has a different result type in current version, where it is scala.collection.Seq rather than scala.collection.immutable.Seq [error] filter with: ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.status.api.v1.StageData.accumulatorUpdates") [error] * method this(org.apache.spark.status.api.v1.StageStatus,Int,Int,Int,Int,Int,Int,Int,Int,scala.Option,scala.Option,scala.Option,scala.Option,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,java.lang.String,scala.Option,java.lang.String,java.lang.String,scala.collection.immutable.Seq,scala.collection.immutable.Seq,scala.Option,scala.Option,scala.Option,scala.collection.immutable.Map,Int,scala.Option,scala.Option,scala.Option)Unit in class org.apache.spark.status.api.v1.StageData's type is different in current version, where it is (org.apache.spark.status.api.v1.StageStatus,Int,Int,Int,Int,Int,Int,Int,Int,scala.Option,scala.Option,scala.Option,scala.Option,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,java.lang.String,scala.Option,java.lang.String,java.lang.String,scala.collection.Seq,scala.collection.Seq,scala.Option,scala.Option,scala.Option,scala.collection.immutable.Map,Int,scala.Option,scala.Option,scala.Option)Unit instead of (org.apache.spark.status.api.v1.StageStatus,Int,Int,Int,Int,Int,Int,Int,Int,scala.Option,scala.Option,scala.Option,scala.Option,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,Long,java.lang.String,scala.Option,java.lang.String,java.lang.String,scala.collection.immutable.Seq,scala.collection.immutable.Seq,scala.Option,scala.Option,scala.Option,scala.collection.immutable.Map,Int,scala.Option,scala.Option,scala.Option)Unit [error] filter with: ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.status.api.v1.StageData.this") ``` ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested. Closes #39356 from HyukjinKwon/SPARK-41423. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
What changes were proposed in this pull request?
Add Protobuf serializer for StageDataWrapper.
Why are the changes needed?
Support fast and compact serialization/deserialization for StageDataWrapper over RocksDB.
Does this PR introduce any user-facing change?
No.
How was this patch tested?
New UT.