Set TCP_USER_TIMEOUT socket option#926
Set TCP_USER_TIMEOUT socket option#926openshift-merge-robot merged 3 commits intoopenshift:masterfrom
Conversation
pkg/config/client/client_config.go
Outdated
| KeepAlive: 30 * time.Second, | ||
| }).DialContext | ||
| Control: func(network, address string, c syscall.RawConn) error { | ||
| // Supported only on Linux |
There was a problem hiding this comment.
do we have to detect connections to the local host?
7c2abcc to
6f5b6b3
Compare
|
Given that I don't think many people will be accessing the apiserver over sattelite internet, these timing parameters seem just fine. However, we need to verify that they do what we want, since these knobs are non-orthogonal and never obvious. The easiest way I can think of to test this is
|
| func dialerWithDefaultOptions() *net.Dialer { | ||
| return &net.Dialer{ | ||
| // TCP_USER_TIMEOUT does affect the behaviour of connect() which is controlled by this field so we set it to the same value | ||
| Timeout: 25 * time.Second, |
There was a problem hiding this comment.
does it make sense?
There was a problem hiding this comment.
Timeout, in this case, is timeout to establish the TCP session. 25 seconds might be gigantic, if this is exclusively intra-cluster traffic.
There was a problem hiding this comment.
yes, this function is primarily used by the operators (https://github.com/search?q=org%3Aopenshift+GetKubeConfigOrInClusterConfig&type=code).
Setting it to 5s would be okay?
There was a problem hiding this comment.
actually, now that I think about it, 20 is probably about right. In a cluster that is thrashing but making progress, setting too low a timeout just leads to additional resource exhaustion. As always, it's a balancing act between keeping lightly-loaded clusters performant vs. tolerating heavliy-loaded ones.
I wish we had better numbers to make this decision. Let me see if we have some metrics.
5b15e39 to
3073050
Compare
| klog.V(2).Info("Creating the default network Dialer (unsupported platform). It may take up to 15 minutes to detect broken connections and establish a new one") | ||
| return &net.Dialer{ | ||
| Timeout: 30 * time.Second, | ||
| KeepAlive: 30 * time.Second, |
There was a problem hiding this comment.
no, KeepAlive setts both TCP_KEEPINTVL and TCP_KEEPIDLE to the same value. Since we want distinct values we are now setting them in setDefaultSocketOptions function
3073050 to
9693567
Compare
|
/hold for testing |
f6b30d9 to
e8be127
Compare
|
re e8be127 commit it turned out that |
|
I did test it on an idle connection and it looks like it actually works. I created a simple app that establishes a watch on never changing Withouth the patch, the connection is terminated after ~
With the patch, the connection is terminated after ~
|


|
I did test it on an active connection and it looks like it actually works. I created a simple app that sends Withouth the patch, the connection is terminated after
With the patch, the connection is terminated after
|
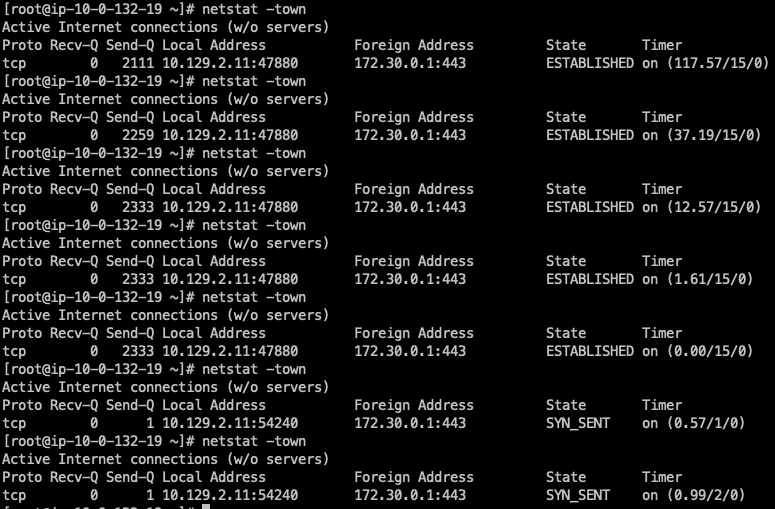

|
/hold cancel |
|
/lgtm |
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: p0lyn0mial, sttts The full list of commands accepted by this bot can be found here. The pull request process is described here DetailsNeeds approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
post-merge /lgtm - this is awesome! |
|
/cherry-pick release-4.6 |
|
@p0lyn0mial: new pull request created: #937 DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
This PR sets the
TCP_USER_TIMEOUT(https://man7.org/linux/man-pages/man7/tcp.7.html) socket option which controls for how long transmitted data may be unacknowledged before the connection is forcefully closed.Without that option, we rely on the TCP stack to detect broken network connection. This can take up to 15 minutes. During that time our platform might be unavailable.
There are already reported cases in which aggregated APIs (i.e.
openshift-apiserver) were unable to establish a new connection to the Kube API for 15 minutes after "ungraceful termination" (https://bugzilla.redhat.com/show_bug.cgi?id=1881878 and after a network error https://bugzilla.redhat.com/show_bug.cgi?id=1879232#c39)It looks like detecting broken connections on the application level is getting more traction and is preferable. Unfortunately, it is on the slow track and will require backporting to golang's std library. Until that time we would like to take advantage of
TCP_USER_TIMEOUT[1] https://go-review.googlesource.com/c/net/+/198040
[2] https://go-review.googlesource.com/c/net/+/236498#message-7bd657ac6960f0dc7acbbe28cbe3d80ac4f3a34b