Node Topology Manager #693
Comments
|
/sig node |
|
I can help inform this design based on learning from Borg. So count me in as a reviewer/approver. |
Is there any public documentation on how this feature works in borg? |
|
Not about NUMA AFAIK.
…On Mon, Feb 11, 2019, 7:50 AM Jeremy Eder ***@***.*** wrote:
I can help inform this design based on learning from Borg. So count me in
as a reviewer/approver.
Is there any public documentation on how this feature works in borg?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#693 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz>
.
|
|
FYI @claurence This tracking issue and KEP (#781) did not make it in time for the v1.14 enhancements freeze nor the extended deadline. I appreciate that you opened these before the deadlines, but they didn't seem to get sufficient review or sign off. This will need to go through the exception process. Until we decide whether this is worth the exception, I'm inclined to put a hold on all PR's associated with this enhancement. |
|
/cc @jiayingz @dchen1107 |
|
@lmdaly I see y'all are have 1.14 listed in the description as the alpha milestone - since there wasn't a merged implementable KEP this issue is not being tracked for 1.14 - if there are intentions for it to be included in that release please submit an exception request. |
@claurence the KEP is now merged (KEP had been previously merged in the community repo. this was just to move it to the new enhancements repo as per the new guidelines), do we still need to submit an exception request to get this issue tracked for 1.14? |
|
While after reading the design & WIP PRs througoutly, I have concerns that the current implementation is not generic as the original topology design we proposed in #781. This one currently reads more like NUMA topology in node level. I left some comments for further discussion here: kubernetes/kubernetes#74345 (comment) |
Share the same concern about on that :) How about others, e.g. links between device (nvlinke for GPU)? |
|
@resouer @k82cn The initial proposal deals only with aligning the decisions made by cpu manager and device manager to ensure proximity of devices with the cpu the container runs on. Satisfying the inter-device affinity was a non-goal of the proposal. If however, the current implementation is blocking the addition of inter-device affinity in the future then I am happy to change the implementation once I get an understanding of how it is doing so, |
|
I think the main issue I see with the current implementation and the ability to support inter-device affinity is the following:
From what I can tell in the current proposal, the assumption is that these operations happen in reverse order, i.e. the socket affinity is decided before doing the allocation of devices. |
|
That’s not necessarily true @klueska. If the topology hints were extended to encode point-to-point device topology, the Device Manager could consider that when reporting socket affinity. In other words, cross device topology wouldn’t need to leak out of the scope of the device manager. Does that seem feasible? |
|
Maybe I'm confused about the flow somehow. This is how I understand it:
If this is correct, I guess I'm struggling with what happens between the point in time when the device plugin reports its If these hints are meant to encode "preferences" for allocation, then I think what you are saying is to have a structure more like: Where we not only pass a list of socket affinity preferences, but how those socket affinity preferences pair with allocatable GPU preferences. If this is the direction you are thinking, then I think we could make it work, but we would need to somehow coordinate between the Is there something in place that allows this already that I missed? |
|
I think what happens, making some minor corrections to your flow is:
In this case, what will be represented as topology-aware in the Kubelet are the For this:
This is what the
|
|
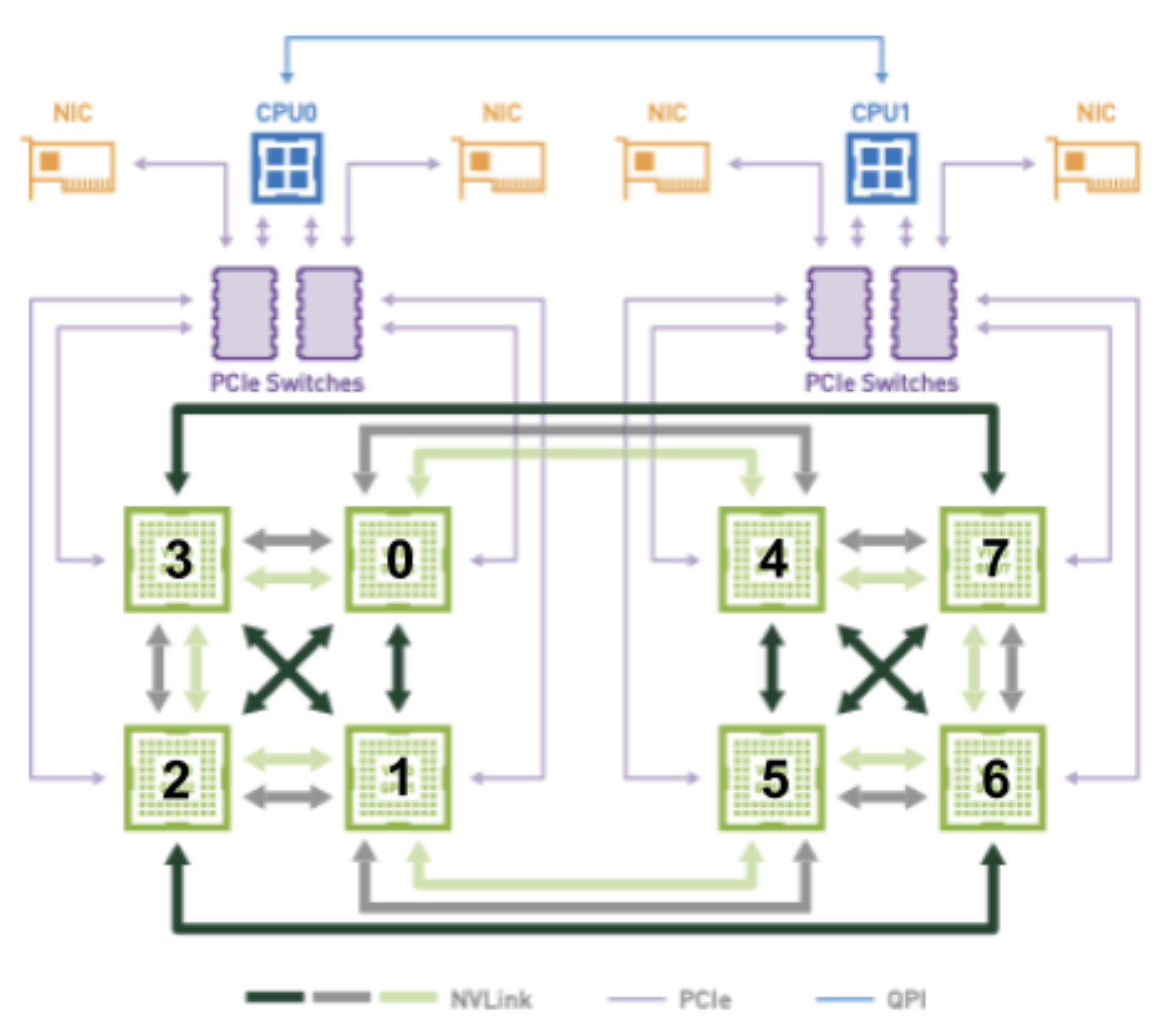
I see. So the Circling back to the original question / issue I raised though.... From Nvidia's perspective, I think we can make everything work with this proposed flow, assuming more information is added to the However, I think starting with a For example, consider the figure below, when attempting to allocate 2 GPUs to a pod with optimal connectivity:
The GPU combinations of (2, 3) and (6, 7) both have 2 NVLINKs and reside on the same PCIe bus. They should therefore be considered equal candidates when attempting to allocate 2 GPUs to a pod. Depending on which combination is chosen, however, a different socket will obviously be preferred as (2, 3) is connected to socket 0 and (6, 7) is connected to socket 1. This information will somehow need to be encoded in the A potential solution specific to Nvidia GPUs for this example would look something like: Where the While this may or may not provide a generic enough solution for all accelerators, replacing Note that Thoughts? |
|
Hey again @swatisehgal @klueska |
Thanks for the reminder, I am waiting for another round of PRR review. |
|
I have also pinged SIG node approvers on slack. Let's see if we can manage to get this in this release. |
|
@swatisehgal ok, just commented - please take your reply and put it in the KEP and we're good to go for PRR |
|
@Atharva-Shinde this KEP should satisfy all requirements now. Ready to be marked as Tracked |
|
Awesome! The status of this enhancement is marked as |
|
/reopen Some PRs are still pending and need to be merged for this work to be marked as complete. |
|
@swatisehgal: Reopened this issue. In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
Hi @klueska @khenidak @lmdaly 👋, I’m reaching out from the 1.27 Release Docs team. This enhancement is marked as ‘Needs Docs’ for the 1.27 release. Please follow the steps detailed in the documentation to open a PR against dev-1.27 branch in the k/website repo. This PR can be just a placeholder at this time, and must be created by March 16. For more information, please take a look at Documenting for a release to familiarize yourself with the documentation requirements for the release. Please feel free to reach out with any questions. Thanks! |
|
@swatisehgal ^^ |
|
Hey again @swatisehgal @klueska 👋 Enhancements team here, Here's where this enhancement currently stands:
Also please let me know if there are other PRs in k/k we should be tracking for this KEP. |
@mickeyboxell I have created docs PR and linked it to the comment tracking GA graduation work here. |
|
/stage stable |
|
NEXT: remove the feature gate in 1.29 and mark it as "implemented" in kep.yaml. |
|
/remove-label lead-opted-in |
|
Hi, I am new to use kubelet topology-manager with single-numa-node to manage my workloads. I have some questions, why we make this option as a node-level setting? Is there any problem if the option is a pod-level setting? |
Enhancement Description
k/enhancements) update PR(s):k/k) update PR(s):k/website) update(s):k/k) update PR(s):k/website) update(s):k/enhancements) update PR(s):k/k) update PR(s):k/website) update(s):The text was updated successfully, but these errors were encountered: