[SPARK-32290][SQL] SingleColumn Null Aware Anti Join Optimize #29104
Conversation
|
@cloud-fan |
| notInSubquerySingleColumnOptimizeStreamedKeyIndex, | ||
| notInSubquerySingleColumnOptimizeStreamedKey.dataType | ||
| ) | ||
| val notInKeyEqual = params.buildSideHashSet.contains(streamedRowNotInKey) |
There was a problem hiding this comment.
Could we reuse [Unsafe|Long]HashedRelation here?
There was a problem hiding this comment.
done changing into HashedRelation, nice advise.
| if leftAttr.semanticEquals(tmpLeft) && rightAttr.semanticEquals(tmpRight) => | ||
| notInSubquerySingleColumnOptimizeSetStreamedKey(leftAttr, rightAttr) | ||
| if (notInSubquerySingleColumnOptimizeStreamedKeyIndex != -1) { | ||
| true | ||
| } else { | ||
| logWarning(s"failed to find notInSubquerySingleColumnOptimizeStreamedKeyIndex," + | ||
| s" fallback to leftExistenceJoin.") | ||
| false |
There was a problem hiding this comment.
This code block is the same with the line244-251? If so, could you merge them? How about defining an extractor object for the case?
There was a problem hiding this comment.
I check on the source code on subquery.scala, found that
Or(EqualTo(a, b), IsNull(EqualTo(a, b))) will be the only option, there is no need to handle two Or pattern. so i remove the duplicate code.
# See. org/apache/spark/sql/catalyst/optimizer/subquery.scala
val inConditions = values.zip(sub.output).map(EqualTo.tupled)
val nullAwareJoinConds = inConditions.map(c => Or(c, IsNull(c)))
| // or(a=b,isnull(a=b)) | ||
| // or(isnull(a=b),a=b) | ||
| condition.get match { | ||
| case _@Or(_@EqualTo(leftAttr: AttributeReference, rightAttr: AttributeReference), |
There was a problem hiding this comment.
btw, could you follow the format in the other code? For example, we need to a space between @ and EqualTo.
|
Could you update |
|
ok to test |
|
oh, btw, thanks for the first contribution, @leanken . |
Will reply your comments ASAP, many thanks. |
|
Test build #125871 has finished for PR 29104 at commit
|
|
retest this please |
I am afraid that TPCDS sqls does not have NotInSubquery case, TPCDS sqls using Not Exists instead of Not In. What i ran before is TPCH Query 16. But i am more than happy to just write TPHC benchmark code and do benchmark after this issue closed, if needed, ^_^ |
|
Ah, I see and I missed that. You said not TPCDS but TPCH, right. |
|
the Origin 800,000,000 * 4,898 times calculation could easily cost 50~60 mins, after apply this patch, it takes only 9s. |
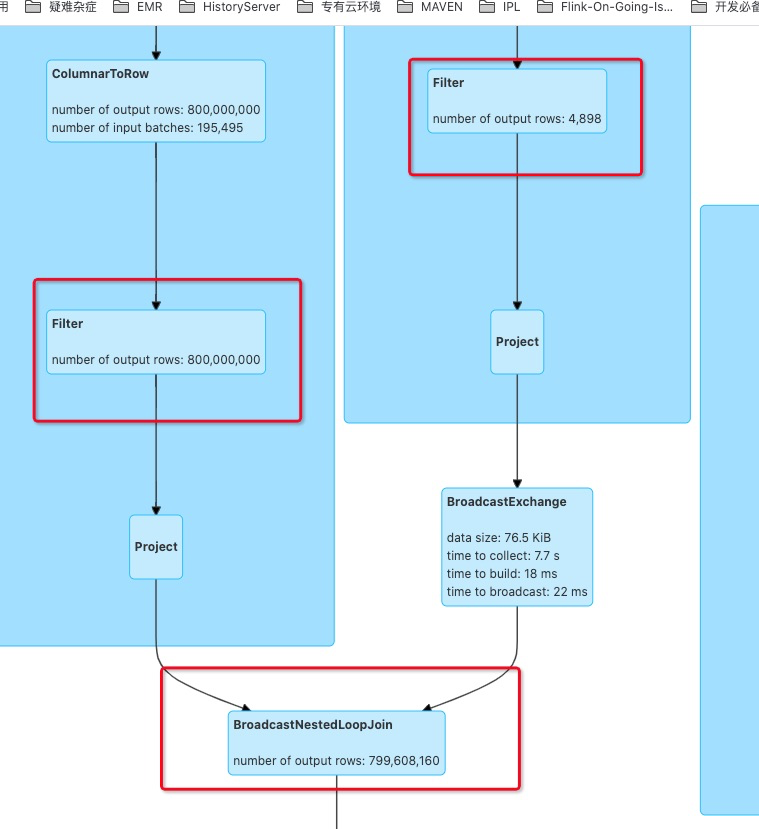
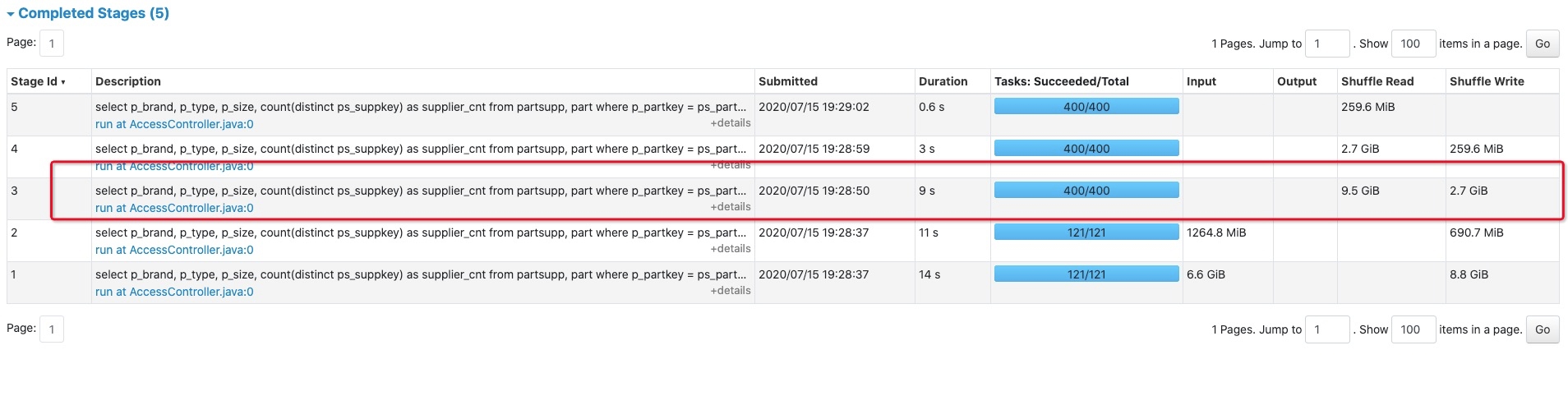
|
Test build #125884 has finished for PR 29104 at commit
|
|
@maropu Any further comments? |
One question; why did you apply this optimization only in the case? The optimization itself looks more general though. |
you mean extend it to support multi columns? |
|
yea, we cannnot handle the case? |
|
-- Test cases for multi-column ``WHERE a NOT IN (SELECT c FROM r ...)'': multi column Not(IsNull) is much more complicated. i am afraid that the lookup code and if-else logic will be un-readable. |
|
let me take some time to find out common pattern among single and multi column support. |
|
hm, it might be okay to support the limited optimization as a first step if it has a huge impact on the performance of common caes. But, I think the method (& parameter) names should be more general and we need to leave to TODO for future work. |
|
For example. in this case, i can't not use InternalRow(null, 1.0) to lookup in HashedRelation. I need to exclude all null column, and try found match within the not null column, which i think HashedRelation is not a suitable structure for multi-column support. But if change into multi column and need to deal with null column, which means i can't use Hash to lookup, so it will still be a M*N, that's no gona help. |
|
let's say in streamedSide there is a record if i need to confirm a Not In, i need to extract second column values, and build HashSet; what if next time streamedSide is a in simple words, i could not rebuild a "CUBE-LIKE" HashSet for all column combinations; or I can just rollback to just compare two records in BuildSide row by row, which is still M*N. So I think multiple column is not suitable for these Hash Optimize because its null safe complexity |
Myself also thinks of these methodName and paramsName being too long, do you have better suggestion for me, that will be great help. |
ping @maropu on the multi column support conclusion. |
|
I don't see a unit test in this PR. Can you please add one. Thanks. |
 agrawaldevesh
left a comment
agrawaldevesh
left a comment
There was a problem hiding this comment.
This is pretty neat and it would make Spark look pretty cool on TPCH. Thanks for taking this up.
But Please add some Unit Tests ! Another way to test this "Exhaustively" would be to have a config to force this optimization and then run it through the existing Not in test suites, which already do a fairly good job. But I think you would have to copy that test perhaps to make sure it runs fully with this "forced config" enabled.
As for the general design of this optimization, I feel a bit uncomfortable doing this check at "Runtime". An alternative design would be to do this check somehow at the optimizer / compile time and then set a flag in the regular BroadcastHashJoin that it should now be null aware. I am wondering if you considered that strategy ? It might be a better UX for the user: The explain plan and spark UI would be more faithful.
On that note ? Is it worth somehow communicating to the user that their BroadcastNLJ was "accelerated" using this approach ? Do you want to up-level that as a metric etc such that it can show up in the Spark UI. Not sure if it is worth the plumbing.
Thanks.
| // BuildSide must be single column, condition must be the following pattern | ||
| // Or(EqualTo(a, b), IsNull(EqualTo(a, b))) | ||
| condition.get match { | ||
| case _ @ Or( |
There was a problem hiding this comment.
I believe you can write this more simply as:
Or(EqualTo(leftAttr, rightAttr), IsNull(tmpLeft, tmpRight)) if ...
I believe you don't need the dashes.
| AttributeSeq(left.output)) | ||
| ) | ||
| streamedIter.filter(row => { | ||
| // See. not-in-unit-tests-single-column.sql for detail filter rules |
There was a problem hiding this comment.
Lets not refer to test code for describing production code :-)
| buildConf("spark.sql.notInSubquery.singleColumn.optimize.enabled") | ||
| .internal() | ||
| .doc("When true, single column not in subquery execution in BroadcastNestedLoopJoinExec " + | ||
| "will be optimized from M*N calculation into M*log(N) calculation using HashMap lookup " + |
There was a problem hiding this comment.
N00b/dumb question: Why M*log(N) instead of M * 1 ? Shouldn't HT probe lookup be O(1) and O(log N).
| .booleanConf | ||
| .createWithDefault(false) | ||
|
|
||
| val NOT_IN_SUBQUERY_SINGLE_COLUMN_OPTIMIZE_ROW_COUNT_THRESHOLD = |
There was a problem hiding this comment.
What should be the relationship of this config vs spark.sql.autoBroadcastJoinThreshold ? Shouldn't the threshold be based on the size of the build size in bytes vs num rows ? I think it is confusing to have two configs for the similar sort of information: How big can the table be.
There was a problem hiding this comment.
done remove this config and use spark.sql.autoBroadcastJoinThreshold
| isBuildRowsEmpty: Boolean) | ||
|
|
||
| private def notInSubquerySingleColumnOptimizeEnabled: Boolean = { | ||
| if (SQLConf.get.notInSubquerySingleColumnOptimizeEnabled && right.output.length == 1) { |
There was a problem hiding this comment.
Dumb question: Should left.output.length be checked as well ?
I believe not everyone would know of the nuances with multi-column Null Aware anti join (see http://www.vldb.org/pvldb/vol2/vldb09-423.pdf section 6.1 and 6.2), so it would be nice to mention atleast that multi-column is not being handled because it is insanely complicated.
There was a problem hiding this comment.
left.output.length could be more than 1.
| ) | ||
| streamedIter.filter(row => { | ||
| // See. not-in-unit-tests-single-column.sql for detail filter rules | ||
| if (params.isBuildRowsEmpty) { |
There was a problem hiding this comment.
I believe you can pull this check out .. No point in going through a "filter" that is unconditionally true.
| val lookupRow: UnsafeRow = keyGenerator(row) | ||
| val notInKeyEqual = params.buildSideHashedRelation.get(lookupRow) match { | ||
| case null => false | ||
| case _ => true |
There was a problem hiding this comment.
Can this be simplified to params.buildSideHashedRelation.get(lookupRow) != null ?
| BindReferences.bindReferences[Expression]( | ||
| Seq(right.output.head), AttributeSeq(right.output)), | ||
| buildRows.length), | ||
| buildRows.exists(row => row.isNullAt(0)), |
There was a problem hiding this comment.
dumb question: row is guaranteed to have only a single column, right ?
| case _ => true | ||
| } | ||
|
|
||
| if (!streamedRowIsNull && !params.isNullExists && !notInKeyEqual) { |
There was a problem hiding this comment.
The check for isNullExists can also be pulled out: If isNullExists, then we will unconditionally return nothing.
You have already paid the one time cost of doing a scan on the build size to check if any nulls exist (when preparing the params), you might as well exploit that check to gain some speed here :-)
| .notInSubquerySingleColumnOptimizeRowCountThreshold}, fallback to leftExistenceJoin.") | ||
| leftExistenceJoin(relation, false) | ||
| } else { | ||
| val params = notInSubquerySingleColumnOptimizeBuildParams(buildRows) |
There was a problem hiding this comment.
This Null aware single column hash join is subtle and could use some comments or perhaps a reference. Perhaps you could link to section 6.1 of that paper above ?
There was a problem hiding this comment.
done. with TODO and comment left.
|
@agrawaldevesh thanks for your feedback, I will first consider your suggestion about doing it in optimizer. it might take some time. |
|
Hi. @agrawaldevesh if i want to translate into BroadcastHashJoinExec, first of all i need a join key, right? Let's see what codegenAnti is like: antiJoin with Key will keep streamedSideRow if streamedSide key is a null, but it's totally opposite in NotInSubquery. I can certainly do some if-else check here, but it might mess up the whole BroadcastHashJoinExec Code. Besides the streamedSide key null difference, need to go through the entire buildSide to see if there is a null key exists, that's also kind of weird. BroadcastHashJoinExec assume that it has join key, but if i apply my NotInSubquery check here, it would like, hey, I found two key should be joined, but wait a minute, there are a tiny corner case here, so back off. if it's up to me to choose, i won't choose to break integrity of BroadcastHashJoinExec, i would rather count NotInSubquerySingleColumn as an runtime optimize. So, I am polling out the relative information for you guys, seeking advice till I move forward to next step. Choose A. Choose B. looking for your reply, many many thanks. |
sub commit 1. change spark.sql.nullAwareAntiJoin.optimize.enabled => spark.sql.optimizeNullAwareAntiJoin 2. add assertion for isNullAware 3. update CONFIG_DIM with spark.sql.optimizeNullAwareAntiJoin 4. code style refined. Change-Id: I871fe95664e233908bb39b63444e73c4a24126c0
typo. Change-Id: Id5db52227468cb4b22bad1923eab85bd6ce6fb5d
Change-Id: Icbf28bdbee90de6b09172ab4c495383002f340a4
sub commit 1. change EmptyHashedRelation and EmptyHashedRelationWithAllNullKeys to singleton object 2. change default implementation of NullAwareHashedRelation to throw UnsupportedOperationException Change-Id: I173ce102bb704677699b89daa1c9906f748c94aa
395823d to
233eff6
Compare
| --CONFIG_DIM1 spark.sql.optimizeNullAwareAntiJoin=true | ||
| --CONFIG_DIM1 spark.sql.optimizeNullAwareAntiJoin=false | ||
|
|
There was a problem hiding this comment.
Thanks for adding these. It gives us more confidence.
There was a problem hiding this comment.
thanks to @cloud-fan I know of this better way to do e2e case coverage when adding a new feature.
|
Test build #126672 has finished for PR 29104 at commit
|
|
github action passes, I'm merging it to master, thanks for your great work! |
| .checkValue(_ >= 0, "The value must be non-negative.") | ||
| .createWithDefault(8) | ||
|
|
||
| val OPTIMIZE_NULL_AWARE_ANTI_JOIN = |
There was a problem hiding this comment.
You forgot to add version(). Here is the follow up PR #29335
| object EmptyHashedRelationWithAllNullKeys extends NullAwareHashedRelation { | ||
| override def asReadOnlyCopy(): EmptyHashedRelationWithAllNullKeys.type = this |
There was a problem hiding this comment.
This object name really confuses. EmptyHashedRelation is from empty input, and EmptyHashedRelationWithAllNullKeys is from non-empty input.
There was a problem hiding this comment.
Yes, indeed, but I can't come out with better naming, could you please help with the naming, and i will create a new PR to do code refine, since this PR is closed.
There was a problem hiding this comment.
probably just remove Empty to make it HashedRelationWithAllNullKeys?
| return s""" | ||
| |boolean $found = false; | ||
| |// generate join key for stream side | ||
| |${keyEv.code} | ||
| |if ($anyNull) { | ||
| | $found = true; | ||
| |} else { | ||
| | UnsafeRow $matched = (UnsafeRow)$relationTerm.getValue(${keyEv.value}); | ||
| | if ($matched != null) { | ||
| | $found = true; | ||
| | } | ||
| |} | ||
| | | ||
| |if (!$found) { | ||
| | $numOutput.add(1); | ||
| | ${consume(ctx, input)} | ||
| |} |
There was a problem hiding this comment.
Seems we can get rid of found variable and move this two lines to above if/else. found looks not correct in its semantics too. anyNull is true, doesn't mean we found matched row.
There was a problem hiding this comment.
how about
s"""
|// generate join key for stream side
|${keyEv.code}
|if (!$anyNull && $relationTerm.getValue(${keyEv.value}) == null) {
| $numOutput.add(1);
| ${consume(ctx, input)}
|}
""".stripMargin
maybe I could update these code as well with the new HashedRelation Name in next PR.
…join ### What changes were proposed in this pull request? NULL-aware ANTI join (https://issues.apache.org/jira/browse/SPARK-32290) detects NULL join keys during building the map for `HashedRelation`, and will immediately return `HashedRelationWithAllNullKeys` without taking care of the map built already. Before returning `HashedRelationWithAllNullKeys`, the map needs to be freed properly to save memory and keep memory accounting correctly. ### Why are the changes needed? Save memory and keep memory accounting correctly for the join query. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests introduced in #29104 . Closes #32939 from c21/free-null-aware. Authored-by: Cheng Su <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…join ### What changes were proposed in this pull request? NULL-aware ANTI join (https://issues.apache.org/jira/browse/SPARK-32290) detects NULL join keys during building the map for `HashedRelation`, and will immediately return `HashedRelationWithAllNullKeys` without taking care of the map built already. Before returning `HashedRelationWithAllNullKeys`, the map needs to be freed properly to save memory and keep memory accounting correctly. ### Why are the changes needed? Save memory and keep memory accounting correctly for the join query. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests introduced in #29104 . Closes #32939 from c21/free-null-aware. Authored-by: Cheng Su <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit e0d81d9) Signed-off-by: Wenchen Fan <[email protected]>
…join ### What changes were proposed in this pull request? NULL-aware ANTI join (https://issues.apache.org/jira/browse/SPARK-32290) detects NULL join keys during building the map for `HashedRelation`, and will immediately return `HashedRelationWithAllNullKeys` without taking care of the map built already. Before returning `HashedRelationWithAllNullKeys`, the map needs to be freed properly to save memory and keep memory accounting correctly. ### Why are the changes needed? Save memory and keep memory accounting correctly for the join query. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests introduced in apache#29104 . Closes apache#32939 from c21/free-null-aware. Authored-by: Cheng Su <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit e0d81d9) Signed-off-by: Wenchen Fan <[email protected]>
…join ### What changes were proposed in this pull request? NULL-aware ANTI join (https://issues.apache.org/jira/browse/SPARK-32290) detects NULL join keys during building the map for `HashedRelation`, and will immediately return `HashedRelationWithAllNullKeys` without taking care of the map built already. Before returning `HashedRelationWithAllNullKeys`, the map needs to be freed properly to save memory and keep memory accounting correctly. ### Why are the changes needed? Save memory and keep memory accounting correctly for the join query. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing unit tests introduced in apache#29104 . Closes apache#32939 from c21/free-null-aware. Authored-by: Cheng Su <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit e0d81d9) Signed-off-by: Wenchen Fan <[email protected]>
…degen is disabled ### What changes were proposed in this pull request? BHJ LeftAnti does not update numOutputRows when codegen is disabled ### Why are the changes needed? PR #29104 Only update numOutputRows when codegen is enabled, but there is no numOutputRows when codegen is disabled, and numOutputRows is equal to 0. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? add UT Closes #38489 from cxzl25/SPARK-41003. Authored-by: sychen <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…degen is disabled ### What changes were proposed in this pull request? BHJ LeftAnti does not update numOutputRows when codegen is disabled ### Why are the changes needed? PR apache#29104 Only update numOutputRows when codegen is enabled, but there is no numOutputRows when codegen is disabled, and numOutputRows is equal to 0. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? add UT Closes apache#38489 from cxzl25/SPARK-41003. Authored-by: sychen <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…degen is disabled ### What changes were proposed in this pull request? BHJ LeftAnti does not update numOutputRows when codegen is disabled ### Why are the changes needed? PR apache#29104 Only update numOutputRows when codegen is enabled, but there is no numOutputRows when codegen is disabled, and numOutputRows is equal to 0. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? add UT Closes apache#38489 from cxzl25/SPARK-41003. Authored-by: sychen <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? Run `NullPropagation` after NOT IN subquery rewrite. ### Why are the changes needed? NOT IN subqueries like `SELECT * FROM t1 WHERE c NOT IN (SELECT c FROM t2)` are rewritten as left anti join `t1.c = t2.c` with additional `OR IsNull(t1.c = t2.c)` conditions which prevents equi join implementations to be used so those joins end up as `BroadcastNestedLoopJoin`. When we know the columns can't be null, we can either drop those additional conditions during subquery rewrite or call `NullPropagation` after the rewrite to simplify them to `false`. This PR contains the latter. Please note that #29104 already optmized the single column NOT IN subqueries from `BroadcastNestedLoopJoin` to "null aware" `BroadcastHashJoin` very well, but when the columns are not nullable we can optimize multi column cases as well and the join don't need to be "null aware". ### Does this PR introduce _any_ user-facing change? Yes, performance improvement. ### How was this patch tested? A new UTs was added and some exsisting tests were adjusted to keep their validity. ### Was this patch authored or co-authored using generative AI tooling? No. Closes #53733 from peter-toth/SPARK-54972-improve-not-in-with-non-nullables. Authored-by: Peter Toth <[email protected]> Signed-off-by: Peter Toth <[email protected]>
### What changes were proposed in this pull request? Run `NullPropagation` after NOT IN subquery rewrite. ### Why are the changes needed? NOT IN subqueries like `SELECT * FROM t1 WHERE c NOT IN (SELECT c FROM t2)` are rewritten as left anti join `t1.c = t2.c` with additional `OR IsNull(t1.c = t2.c)` conditions which prevents equi join implementations to be used so those joins end up as `BroadcastNestedLoopJoin`. When we know the columns can't be null, we can either drop those additional conditions during subquery rewrite or call `NullPropagation` after the rewrite to simplify them to `false`. This PR contains the latter. Please note that apache#29104 already optmized the single column NOT IN subqueries from `BroadcastNestedLoopJoin` to "null aware" `BroadcastHashJoin` very well, but when the columns are not nullable we can optimize multi column cases as well and the join don't need to be "null aware". ### Does this PR introduce _any_ user-facing change? Yes, performance improvement. ### How was this patch tested? A new UTs was added and some exsisting tests were adjusted to keep their validity. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#53733 from peter-toth/SPARK-54972-improve-not-in-with-non-nullables. Authored-by: Peter Toth <[email protected]> Signed-off-by: Peter Toth <[email protected]>
What changes were proposed in this pull request?
Normally, a Null aware anti join will be planed into BroadcastNestedLoopJoin which is very time consuming, for instance, in TPCH Query 16.
In above query, will planed into
LeftAnti
condition Or((ps_suppkey=s_suppkey), IsNull(ps_suppkey=s_suppkey))
Inside BroadcastNestedLoopJoinExec will perform O(M*N), BUT if there is only single column in NAAJ, we can always change buildSide into a HashSet, and streamedSide just need to lookup in the HashSet, then the calculation will be optimized into O(M).
But this optimize is only targeting on null aware anti join with single column case, because multi-column support is much more complicated, we might be able to support multi-column in future.
After apply this patch, the TPCH Query 16 performance decrease from 41mins to 30s
The semantic of null-aware anti join is:
Why are the changes needed?
TPCH is a common benchmark for distributed compute engine, all other 21 Query works fine on Spark, except for Query 16, apply this patch will make Spark more competitive among all these popular engine. BTW, this patch has restricted rules and only apply on NAAJ Single Column case, which is safe enough.
Does this PR introduce any user-facing change?
No.
How was this patch tested?