HDDS-4408: Datanode State Machine Thread should keep alive during the whole lifetime of Datanode #1533
Conversation
|
-1, lets analyze the heapdump to understand the root cause of the memory consumption. |
|
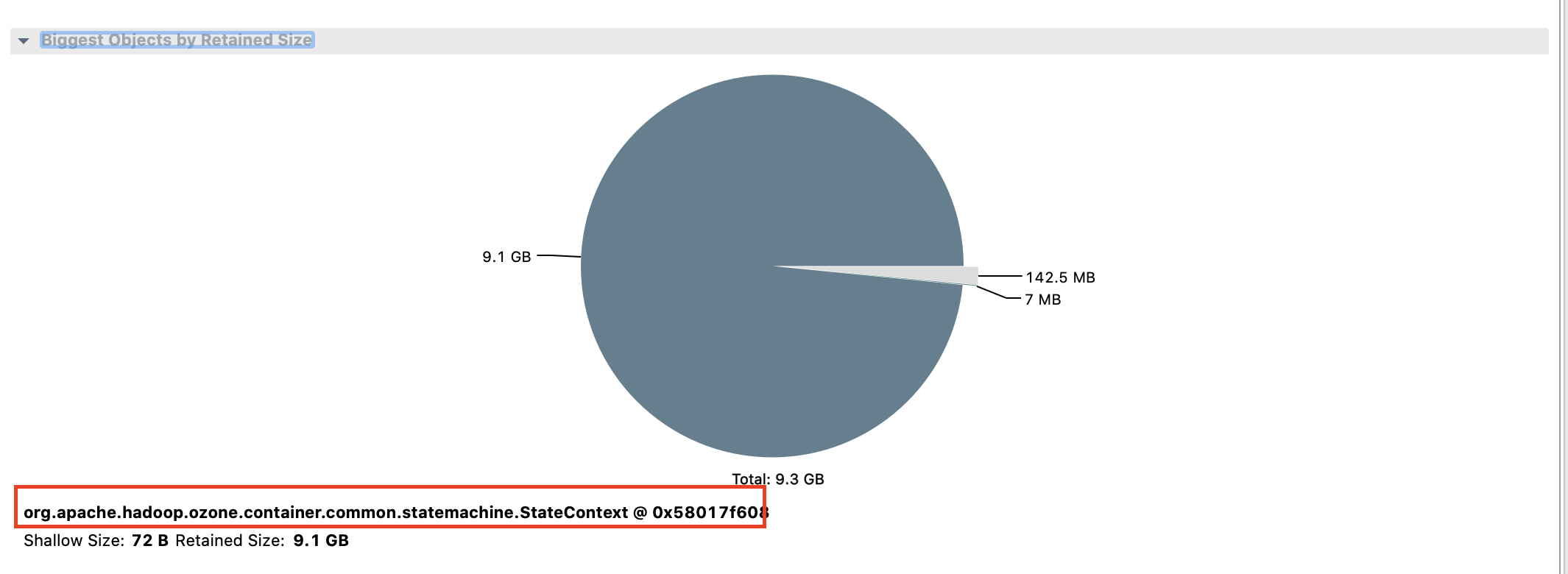
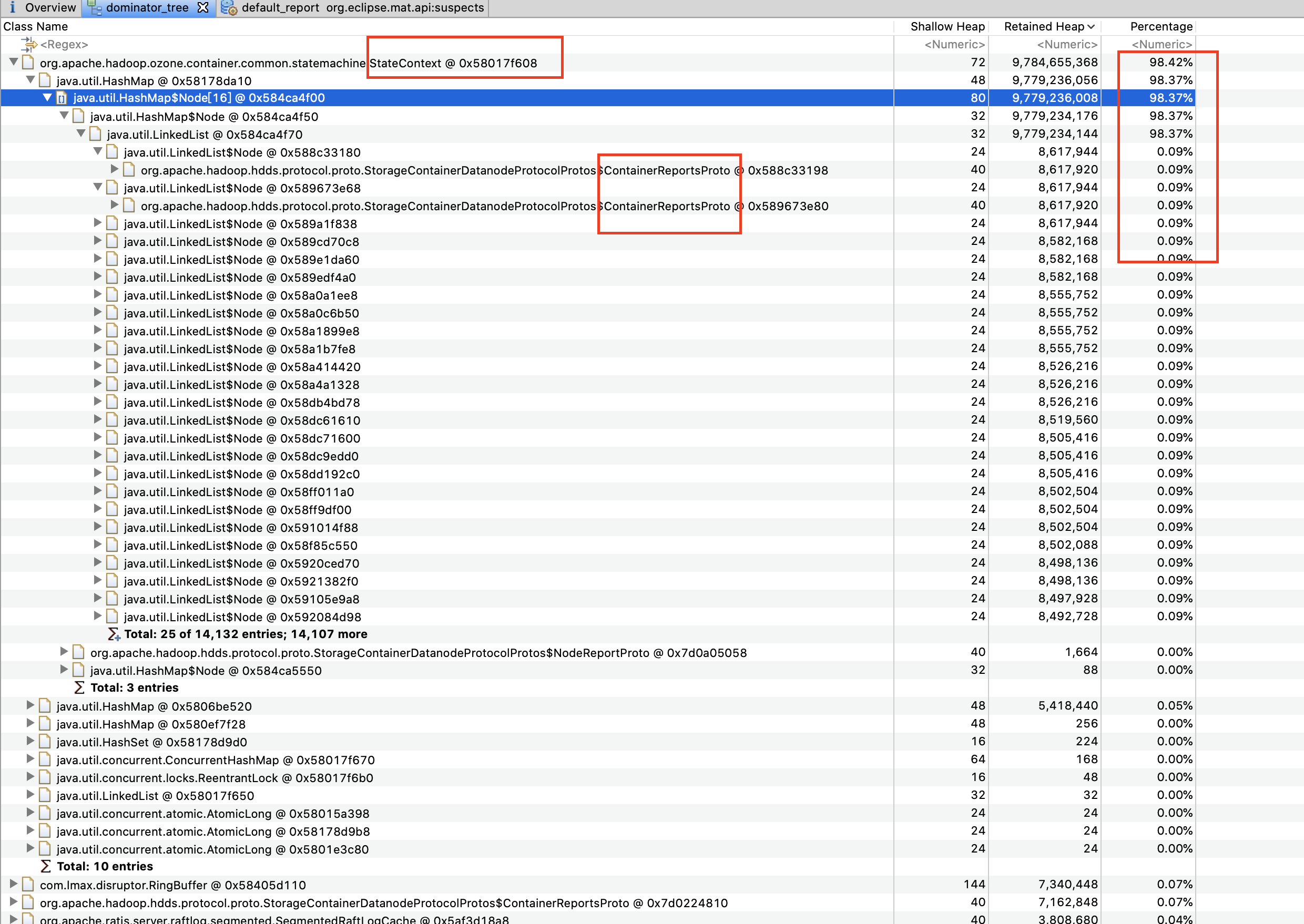
@mukul1987 I consider the previous description for this PR/Jira is not properly, I've updated them. First of all, the key point here is not about OOM. The key point is Datanode State Machine Thread should keep alive during the whole lifetime of Datanode. Without this thread, DN is just a zombie. Let's talk about the OOM. The root cause for OOM is quite straightforward: as explained in HDDS-4404, we have a dead Recon, the report for Recon is blocked in StateContext, after running for more than 1 week, the DN finally suffers from continually OOM. btw, the -Xmx is 10G |
There was a problem hiding this comment.
Would it be better for the DN to just self-terminate if there is an uncaught exception in the state machine thread? Do we know what was the exact uncaught exception?
There was a problem hiding this comment.
Yes, we know the uncaught exception, it is the OOM due to queued reports for a dead Recon. You may find the detail from above conversations.
Either a HA solution or a fast fail solution is fine to me.
BTW, the restart thread solution is already used in cmdProcessThread and leaseMonitorThread.
|
@GlenGeng thank you for the patch.
Overall this is an unhealthy situation for the whole cluster. How would keeping the datanode state machine thread alive help this situation ? Instead it would keep reporting in heartbeat that data node is healthy. |
You are right. All DNs in our cluster are eventually affected by this OOM issue.
Agree. Restarting the thread will not help DN to recover to a healthy state, for this OOM issue. |
…uncaught exception.
4e88b00 to
aeaa76a
Compare
|
The last patch LGTM + 1. I will merge it soon since we need this patch in our production environment. Thanks @GlenGeng for the contribution, @mukul1987 @arp7 @prashantpogde for the review and suggestion. |
* master: (53 commits) HDDS-4458. Fix Max Transaction ID value in OM. (apache#1585) HDDS-4442. Disable the location information of audit logger to reduce overhead (apache#1567) HDDS-4441. Add metrics for ACL related operations.(Addendum for HA). (apache#1584) HDDS-4081. Create ZH translation of StorageContainerManager.md in doc. (apache#1558) HDDS-4080. Create ZH translation of OzoneManager.md in doc. (apache#1541) HDDS-4079. Create ZH translation of Containers.md in doc. (apache#1539) HDDS-4184. Add Features menu for Chinese document. (apache#1547) HDDS-4235. Ozone client FS path validation is not present in OFS. (apache#1582) HDDS-4338. Fix the issue that SCM web UI banner shows "HDFS SCM". (apache#1583) HDDS-4337. Implement RocksDB options cache for new datanode DB utilities. (apache#1544) HDDS-4083. Create ZH translation of Recon.md in doc (apache#1575) HDDS-4453. Replicate closed container for random selected datanodes. (apache#1574) HDDS-4408: terminate Datanode when Datanode State Machine Thread got uncaught exception. (apache#1533) HDDS-4443. Recon: Using Mysql database throws exception and fails startup (apache#1570) HDDS-4315. Use Epoch to generate unique ObjectIDs (apache#1480) HDDS-4455. Fix typo in README.md doc (apache#1578) HDDS-4441. Add metrics for ACL related operations. (apache#1571) HDDS-4437. Avoid unnecessary builder conversion in setting volume Quota/Owner request (apache#1564) HDDS-4417. Simplify Ozone client code with configuration object (apache#1542) HDDS-4363. Add metric to track the number of RocksDB open/close operations. (apache#1530) ...
What changes were proposed in this pull request?
Datanode State Machine Thread should keep alive during the whole lifetime of Datanode, since it periodic generates heartbeat tasks which trigger DN to actively talk with DN. If this thread crashes, DN will become a zombie: although it is alive, heartbeats between itself and SCM are stopped.
In Tencent internal production environment, we got several dead DNs which can never come back without a restart.
We found that the thread "Datanode State Machine Thread - 0" does not exist in the output of jstack, thus no HeartbeatEndpointTask will be created, this DN will soon become dead and can not recover unless being restarted.
After checked the .out log, we saw that OOM occurred in thread "Datanode State Machine Thread", which should be responsible for this issue:
BTW, after running DN for more than a week, we see a lot of "java.lang.OutOfMemoryError: GC overhead limit exceeded" in DN's log. Since we configured a dead Recon, we guess this could be an evidence for HDDS-4404.
What is the link to the Apache JIRA
https://issues.apache.org/jira/browse/HDDS-4408
How was this patch tested?
CI