Add Parquet column index filtering to Iceberg#13584
Add Parquet column index filtering to Iceberg#13584electrum wants to merge 3 commits intotrinodb:masterfrom
Conversation
|
There's an existing PR #12977. I don't mind closing my PR, but probably we need to find way to add tests in this PR. |
e941993 to
3205ed7
Compare
3205ed7 to
1c32786
Compare
|
The native parquet writer doesn't produce page indexes, and that's the only writer in iceberg connector, so we won't benefit from this unless another engine writes the page indexes. |
| ImmutableList.Builder<Optional<ColumnIndexStore>> columnIndexes = ImmutableList.builder(); | ||
| for (BlockMetaData block : parquetMetadata.getBlocks()) { | ||
| long firstDataPage = block.getColumns().get(0).getFirstDataPageOffset(); | ||
| Optional<ColumnIndexStore> columnIndex = getColumnIndexStore(dataSource, block, descriptorsByPath, parquetTupleDomain, options); |
There was a problem hiding this comment.
Although we won't read the column index from file until later, it would be better to avoid creating columnIndex until it's needed (after the start <= firstDataPage && firstDataPage < start + length). We can make same change in ParquetPageSourceFactory as well.
There was a problem hiding this comment.
This will change the indentation of the block and make the diff harder to read, and is unrelated to the Iceberg change, so let's do that as a follow up.
|
I updated 3a5a15a that includes a generated Parquet file. Please feel free to pick up the commit. |
|
@electrum thanks for helping to add this feature! |
thanks @ebyhr! Looks like you have a test case with the generated file as well: https://github.com/trinodb/trino/blob/3a5a15a53ba5e639287d073f661945672f5f6bc3/plugin/trino-iceberg/src/test/java/io/trino/plugin/iceberg/TestIcebergParquetPageSkipping.java Are there any other test that needs to be added? I'll be happy to work. |
|
I'm trying to backport to 391 and test it.
|
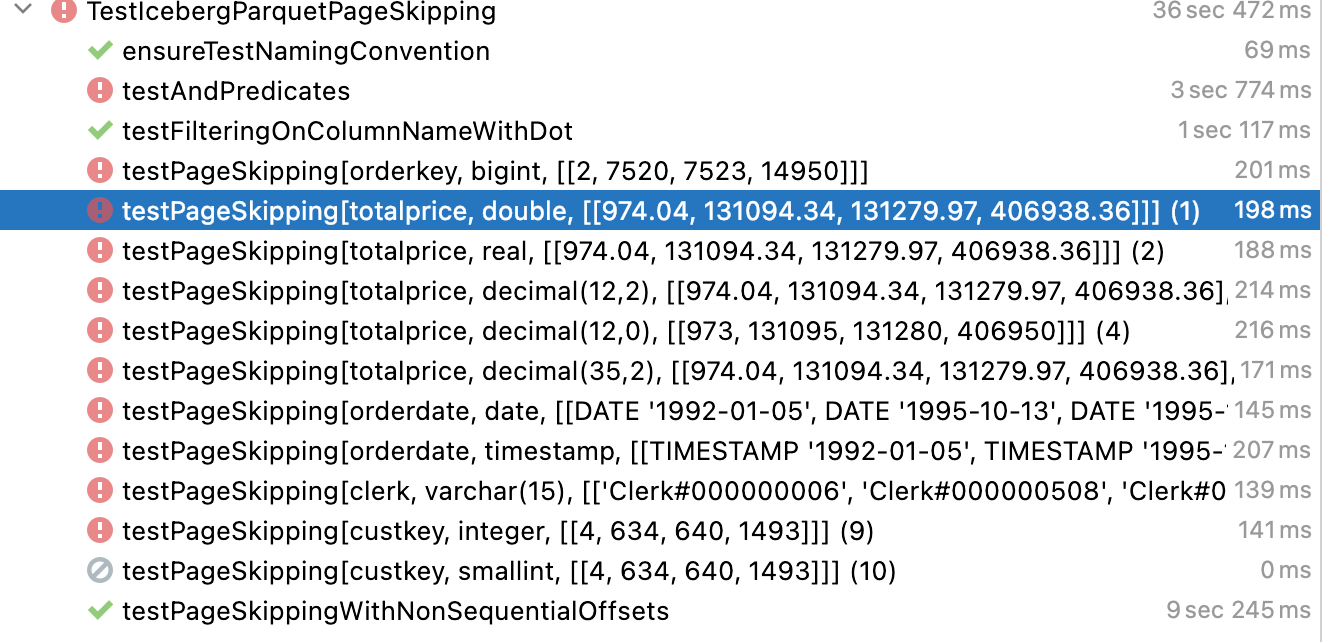
Those tests fail because the native trino parquet writer used by iceberg connector does not write page indexes to file yet. |
Thanks, @raunaqmorarka for the detailed response! |
There is an open PR about that #14428 |
|
@electrum @raunaqmorarka @ebyhr @osscm .. is this still in progress or replaced by some other work? |
|
After cherry-picking the commits in this PR, I want to bring up an issue that was discovered. I performed the following steps:
I observed that no rows were returned by the query ran in step 3. Digging a bit more into the Trino code, I can see the following: In the After the column index object is constructed and Trino uses it to match the different blocks in the parquet file, Trino will proceed to configure the fields of the In the above code, |
|
This pull request has gone a while without any activity. Tagging the Trino developer relations team: @bitsondatadev @colebow @mosabua |
|
@electrum is this something you are still pursuing? |
|
@cwsteinbach @alexjo2144 @findinpath ... I checked with @electrum and it would be good if someone from the team could pick this up. |
|
This pull request has gone a while without any activity. Tagging the Trino developer relations team: @bitsondatadev @colebow @mosabua |
Description
improvement
Related issues, pull requests, and links
Fixes #11000
Documentation
(x) No documentation is needed.
Release notes
(x) Release notes entries required with the following suggested text: