Stabilize automatic garbage collection. #14287
Conversation
|
r? @weihanglo rustbot has assigned @weihanglo. Use |
|
@rfcbot fcp merge |
|
Team member @ehuss has proposed to merge this. The next step is review by the rest of the tagged team members: Concerns:
Once a majority of reviewers approve (and at most 2 approvals are outstanding), this will enter its final comment period. If you spot a major issue that hasn't been raised at any point in this process, please speak up! See this document for info about what commands tagged team members can give me. |
|
@rfcbot concern field-name Something that came up on the tracking issue is whether people will get confused with the I am also somewhat concerned about how to organize and name the config for if/when we get to GC within target directories. I wonder if this would affect the top-level table name (e.g. calling it (sorry, thought of this after the conversation about stabilizing this) |
I agree that this isn't likely to be an issue in practice. However, I also feel like we might as well be more accurate and call it something like "cache cleaning", which is what it actually is. As I mentioned in the other thread, garbage collection is usually related to some concept of reachability and resultant high confidence that something is no longer used. This doesn't reflect how this feature actually works, or ever reasonably could work. And unless I'm missing something here (which is always possible), I don't think there's any cost to simply naming this feature more accurately, aside from taking a bit of time to decide on that name. |
|
Sorry if this is the wrong place to ask, but will there be a way to disable this behaviour? |
I think the PR description already answers this:
|
|
Sure, would be happy to rename it. I opened #14292 to have that suggestion, please express your thoughts over there. |
|
|
||
| * `"never"` --- Never deletes old files. | ||
| * `"always"` --- Checks to delete old files every time Cargo runs. | ||
| * An integer followed by "seconds", "minutes", "hours", "days", "weeks", or "months" --- Checks to delete old files at most the given time frame. |
There was a problem hiding this comment.
“months” is an approximate number.
Lines 373 to 381 in ea14e86
I can foresee someone will interpret months as monthly and think it will be clean on the same day when set, while it is not true especially in February. I don't think this is a thing we can't change after stabilization. Just calling it out if someone disagrees.
There was a problem hiding this comment.
Why not just remove months? It'd be counter-intuitive to anyone trying to use it... The user can already specify something like 180 days for ~6 months, no?
There was a problem hiding this comment.
For myself, being able to say "6 months" is much easier than calculating out the number of days and reading the number of days.
There was a problem hiding this comment.
@epage But would anyone expect it to be 182.62125 days? Principle of least surprise...
There was a problem hiding this comment.
There is an inherent approximation when giving a unit. The larger the unit, the larger the approximation. If you say "6 months", you shouldn't care whether thats 180, 186, 182, or 182.62125.
btw laughing emoji's in a technical discussion like this come across as rude.
There was a problem hiding this comment.
btw laughing emoji's in a technical discussion like this come across as rude.
Sigh... Here we go again. Intent does not carry across text (or emojis), so please don't jump to conclusions like that.
I was not even disagreeing with what you said. Just pointing out that it'd be surpirising for the user, as the OP of this thread has already pointed out (a different surprising aspect).
There was a problem hiding this comment.
@epage But would anyone expect it to be 182.62125 days? Principle of least surprise...
168 would be surprising; a bit over 180 not so much. The kind of surprise we're trying to avoid is purging data way earlier than expected.
There was a problem hiding this comment.
For myself, being able to say "6 months" is much easier than calculating out the number of days and reading the number of days.
If the user goes to the trouble of customizing this in the config, I don't think having to calculate the number of days would be much of an extra hurdle. In effect, removing months would just simplify things with no real downside (and prevent future support questions where people are arguing over this again / trying to figure out what's going on with this approximation).
There was a problem hiding this comment.
A month equals 30 days is easier for me to accept
8dfac6f to
c2af991
Compare
|
☔ The latest upstream changes (presumably #14388) made this pull request unmergeable. Please resolve the merge conflicts. |
|
☔ The latest upstream changes (presumably 4c39aaf) made this pull request unmergeable. Please resolve the merge conflicts. |
This comment has been minimized.
This comment has been minimized.
65f219a to
332a16d
Compare
|
@rfcbot resolve field-name |
|
🔔 This is now entering its final comment period, as per the review above. 🔔 |
|
I am very late to this party, but: Has consideration been given to using the file access time (on Unix at least) to assist with avoiding deleting things that older cargos have accessed recently? I looked for related search terms here and in #12633 and didn't find the answer. |
|
The final comment period, with a disposition to merge, as per the review above, is now complete. As the automated representative of the governance process, I would like to thank the author for their work and everyone else who contributed. This will be merged soon. |
|
Cargo started collecting last use data since 1.78.0, which was almost one year ago. Personally I feel like that is long enough for us to ship this feature in 1.88, which is targeted at 2025-05-09. Adding access time assistant may complicate the mechanism a bit, like figuring out which file's atime Cargo should look at. Also, atime is generally not that reliable I guess? There are mount options like Does that mean by default atime is never older than 1 day? I am not an expert of file system or kernel, but it sounds that atime is always no less than one day old. If that is true, atime is a bit too unreliable. |
The difficulty is that, as I understand it, this feature is poorly compatible with continued use of older versions, that don't record last usage time. Those older versions might end up re-downloading things, which (depending on circumstances) could be a serious regression. I think therefore that this is a breaking change. I don't think it's good enough to say "it's been a year". I need to use Rust 1.31 for MSRV testing, for example, and simply breaking it (or making it behave much worse) is not OK. Happily I think we can fix this feature, at least on Unix, if we use atimes.
Yes, The algorithm ensures than the atime is never wrong by more than a day. (And it is never too recent.) For a cleanup algorithm like cargo's, this is perfect. We should avoid deleting things whose atimes are more recent than the timestamp recorded in the database. Those files are ones which some other program (probably, an old version of cargo) has accessed without making a database record.
atime is not unreliable. On normally-configured systems, it is excellent for this purpose. (Of course people can configure their system in weird ways, but I think we can reasonably tell them that the consequences are on them.) |
I should clarify the effect of the relatime imprecision on such an algorithm. The effect is as follows. Suppose the cutoff for deleting old unused data is 30 days, meaning we don't delete things whose recorded-in-the-database last access is, or whose atime is, is <30d ago. Then with relatime, files which were accessed by old cargo 29 days ago might have an atime which is 30 days ago, and might be deleted. That's OK - it's just a 1-day imprecision in the cutoff, which was a tuning parameter anyway. Files only accessed more than 30 days ago will definitely have an atime at least 30 days old, so are fair game for deletion. Files accessed less than 29 days ago will have an atime of less than 30 days, so will be retained (even if the access was by old cargo and went unrecorded). This would be a pretty good set of behaviours. On the need for the databaseOn Unix with working atimes, the database of access times is not necessary. But, the database is necessary if atimes are completely disabled. And determining if atimes are working is nontrivial. So we need both the database (for systems with noatime) and the atime (for systems which alternately run new cargo, and old, pre-database, versions of cargo). With my suggestion, systems which alternate old and new cargo, and disable atime, don't work well. That seems fair to me, because noatime is not a reasonable configuration choice for a general purpose computer whose role involves subsystems that perform cacheing. |
|
Really appreciate the detailed reply!
Just curious whether setting |
That would restore the behaviour to the previous one. So in some sense it eliminates the regression. But it also means some other cleanup of old things is needed, and I don't believe there is any other sensible mechanism. (In practice a I'm getting a feeling that the cargo team feel the "switch cargo versions" use case is a minority one. I think this is a misconception. Most serious Rust developers who maintain or contribute to a variety of packages are going to be dealing with different MSRVs and/or different nightly versions (eg for cargo expand tests). It would seem unbalanced, to me, to provide such poor support to those users, while having spent a great deal of effort (the explicit usage tracking) to be able to fully support filesystems mounted |
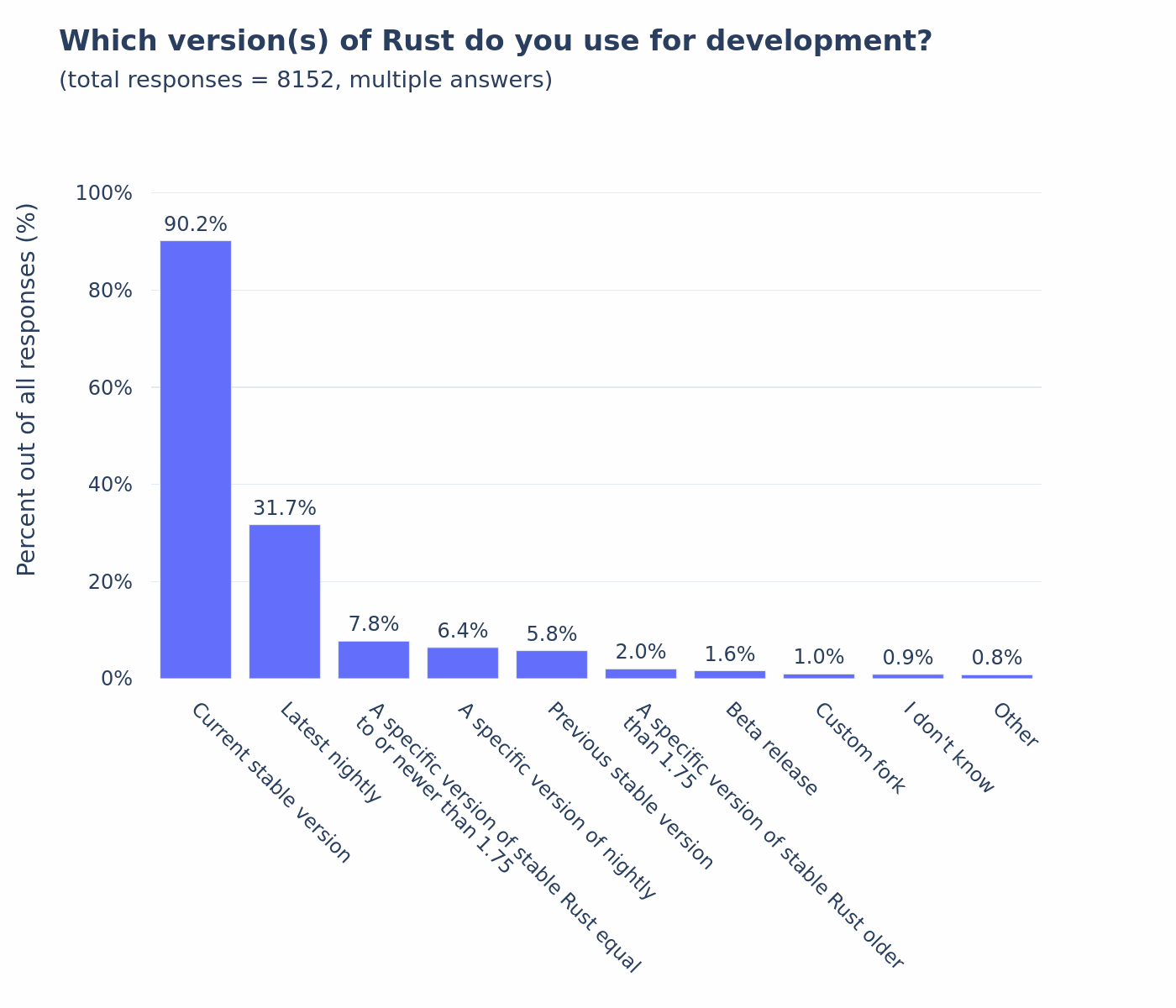
It absolutely is, and we have data to back that up: https://blog.rust-lang.org/2025/02/13/2024-State-Of-Rust-Survey-results.html and in particular https://blog.rust-lang.org/images/2025-02-13-rust-survey-2024/which-version-of-rust-do-you-use.png In particular, using a version of stable older than a year old (1.75 was a year old at the time of the survey) was 2.0%. That doesn't make it an invalid use case, just a demonstrably uncommon one. You may be overestimating the number of people who actively provide support and testing for MSRVs that old. And, for that matter, even of those who do, how many test it locally rather than doing so in CI. That said, I would say that if anything, the Cargo team devotes substantially more than 2% of its time and effort towards reliably supporting older versions of Cargo, and thinking about the impact of changes on older versions of Cargo.
I don't think it's reliable enough for us to rely on by default, for multiple reasons. First, it's not reliably available or updated on all the systems Cargo runs on. On Windows, atime does not seem to be reliably available. Many versions of Windows disabled access times by default, or (later) did so by default on large filesystems. And even on versions that do enable it by default on filesystems of all sizes, it sounds like it may be inconsistent and somewhat unreliable because it's stored in two different places and not kept in sync by different APIs that work with it. On macOS, I haven't managed to find much reliable data (which is a problem in itself), but I've found at least some mentions that by default it doesn't update atime unless it's older than mtime. I haven't found any indication that it also has the relatime-like behavior of also updating if older than some threshold. That doesn't mean it doesn't have that behavior, but I haven't found any evidence one way or another. And, to quote a comment in Cargo's caching implementation, "People tend to run cargo in all sorts of strange environments". Leaving portability aside, the other failure mode of using atime, even as a secondary check (e.g. "if atime is less than N days old don't GC it even if the database says otherwise"), is that too many things may end up updating it. On systems other than Linux, it's common to have background indexing or scanning mechanisms; a system with those running might never do garbage collection if we pay attention to atime. Even on Linux, a recursive grep or other search would update atime.[1] [1] Relatedly, one good reason to use Failing to garbage collect because something touched the atime is not a trivial failure mode. It might seem like failure in that direction is always safer than failure in the direction of GCing too much, but that's not necessarily the case. We see a lot of people complaining about how much disk space Cargo takes; it's a very common complaint about working in Rust. If we do something by default that causes a substantial proportion of systems to fail to reliably GC, we'll have made the feature sufficiently less useful that we're likely to have failed to address the complaint people have. EDIT: the next two paragraphs have a caveat, that if you've only ever handled a file with older Cargo it will never have a database entry, so it may be removed immediately. We may want to fix that to take mtime into account. Leaving all that aside, the proposed behavior of Cargo is "It will delete files that need to be downloaded from the network after 3 months". So, to the best of my understanding, in order for this to cause a problem for people using older versions of Cargo, there would have to be items in Cargo's home directory that are exclusively accessed by an old version of Cargo, for 3 months, while never being accessed by any new version of Cargo. With new versions of Cargo that have the MSRV-aware resolver, that seems much more likely, if some older version of a crate were used only by older Cargo; however, for versions of Cargo older than 1.78 (where we introduced the access tracking), that seems somewhat less likely, unless you have crates you exclusively build using old Cargo and never test with any recent Cargo. Even then, the total impact of this would be that after 3 months some files need re-downloading, and then the issue won't arise again for 3 more months. And note that GC does not happen automatically if you build with So, it's reasonable for us to consider:
I would venture that the answers to the above questions are:
My current position is that this seems like more complexity than we should incur, compared to recommending that people who regularly need to run pre-1.78 versions of Cargo use I would propose that we add a release note along these lines: "When building, Cargo downloads and caches crates needed as dependencies. Historically, these downloaded files would never be cleaned up, leading to an unbounded amount of disk usage in Cargo's home directory. In this version, Cargo introduces a garbage collection mechanism to automatically clean up old files (e.g. Cargo 1.78 and newer track the access information needed for this garbage collection. If you regularly use versions of Cargo older than 1.78, in addition to running current versions of Cargo, and you expect to have some crates accessed exclusively by the older versions of Cargo and don't want to re-download those crates every ~3 months, you may wish to set (We should also include a "For more information, see the cargo documentation for |
{kind=link}
First, an apologyAn earlier version of this message started with some comments that, while well-intentioned, landed very badly, and seemed quite unpleasant to some folks. So, I would like to apologise. I've deleted/reworded things now ,and I will definitely try to avoid any such situation in the future. IntroductionMuch of your message is an argument against enabling atime. I don't think that's relevant, since that's not up to cargo. The remainder seems mostly to be arguments against relying solely on atime. But, no-one is proposing that. Focusing on the suggested improvementLet me try to narrow this down to my suggested improvement:
Then we could check the atime only on non-MacOS Unix platforms, where we expect it to be reliable.
That is expected (and possibly intended). This does not mean that considering the atime is going to cause operational problems. Behaviour of the current proposal without looking at atimes
I think we may have a disconnect about what "after 3 months" means. I take this to mean "files will be deleted unless the database entry records a last access in the last 3 months". For files which are accessed only by old cargo, there will never be any database entry. Therefore this condition will be met. Therefore if we're not looking at file timestamps, they will be deleted immediately. So the same files would be re-downloaded on each switch between old and new cargo. But maybe the current code looks at file modification times to find deletion candidates? In that case the behaviour is as you suggest. But it could be made almost-pareto better on Linux by also considering the atime. Files accessed only by old cargo
I like to do serious engineering. Serious engineering involves providing stability to my downstreams. That means testing my MSRV. It means that there are crates that are only used when I'm working on MSRV support. (I am not surprised that only a small percentage of respondents to the Rust Survey report using older compilers. After all, only a small percentage of respondents are seriously and heavily involved in software engineering in Rust, maintaining high-quality libraries, etc.) MSRV testing can (indeed, usually, must) be done without use of the MSRV-aware resolver, since the MSRV-aware resolver is very new and is not available in my MSRV. The basic approach is to use Note that while obviously MSRV testing happens in CI, it is not unusual for new work to cause MSRV violations. Developers will then want to build and test with the MSRV locally. So a usual workflow does involve switching back and forth between very old and very new versions. Tradeoffs
This is not surprising since currently cargo doesn't ever delete anything. We can't infer anything from this, about the likely receptions of specific details of reclamation strategies.
No-one is proposing this. I am quite prepared to believe that Windows and MacOS have automated systems that mean that atimes can often be far too recent. I care about operating systems that already work reliably - like the ones I use. I think cargo should work well, and reliably, there, even if it must operate in a degraded way on less reliable operating systems. I think atime is either reliable, or disabled, on the vast majority of Linux systems. There, automated scanning systems can be expected to use O_NOATIME (which has existed for decades - there's even an rsync option to use it). |
|
There are more good reasons not to rely on atime (at least by default or without checking mount flags) like CoW filesystems. Ther recommendations for Btrfs and ZFS are to disable atime and there are distributions out there that already do that by default. |
When cargo "adopts" old otherwise-untracked files into the database, it does so using the current date. It will not remove them until 3 months after that. So no, it will not remove such files immediately. We did consider the possibility of never "adopting" old files automatically, and we'll likely consider it further. However, that would have the downside of leaving many files around that for many people would never be used again (because they were used with old versions of cargo that are no longer installed).
Please don't imply that everyone who has different values or priorities than yours is doing unserious engineering, or doesn't care about supporting their users or providing stability for their users. As mentioned, we do care about people using old MSRVs. If there was no solution for that use case, that would be an issue. However, there is always the option of setting
I did mention that possibility in my comment. Alongside mentions of the ongoing cost of inconsistency between targets. We're willing to incur those costs when necessary, especially if there's no other available solution, but as mentioned above there is a solution for old MSRVs, just not the solution one might pick if optimizing more for that case at the expense of other tradeoffs. |
|
As another person who regularly wrangles a bunch of different Rust versions across several operating systems and targets, the proposed solution and workarounds sound entirely reasonable and adequate to me. I can't wait to use this! As things stand, I personally would prefer to have this feature as-is sooner, rather than having further incremental improvements but getting the feature later. I'd feel doubly so if delaying the feature only produces more debate and no significant improvement :) |
|
We understand that this feature will be periodically disruptive to some workflows. In weighing things out though, we've decided to move forward with this. We do think its important that this gets called out in the release notes to raise awareness of this change. Specifically, this will affect people that
The impact of this change will be that every 3 months they will need to redownload the index and The workarounds for this include
Potential solutions include
We also need to balance this against users who would immediately benefit from cleaning up of untracked files that either
Previously, when we needed to weigh the trade offs against different workflows, we found it better to do so in favor of people without an MSRV or those that always develop with their MSRV's dependencies (source). |
 weihanglo
left a comment
weihanglo
left a comment
There was a problem hiding this comment.
Looks great!
Going to merge this without waiting for fixing tiny line breaks issue, so that we can maximize the testing windows before the release of 1.88.
|
|
||
| When running `cargo` commands, Cargo will automatically track which files you are using within the global cache. | ||
| Periodically, Cargo will delete files that have not been used for some period of time. | ||
| It will delete files that have to be downloaded from the network if they have not been used in 3 months. Files that can be generated without network access will be deleted if they have not been used in 1 month. |
There was a problem hiding this comment.
nit: Forgot to add a line break maybe?
And ditto in doc changes in this PR.
(Assuming we follow https://sembr.org)
| It will delete files that have to be downloaded from the network if they have not been used in 3 months. Files that can be generated without network access will be deleted if they have not been used in 1 month. | |
| It will delete files that have to be downloaded from the network if they have not been used in 3 months. | |
| Files that can be generated without network access will be deleted if they have not been used in 1 month. |
Update cargo 10 commits in d811228b14ae2707323f37346aee3f4147e247e6..7918c7eb59614c39f1c4e27e99d557720976bdd7 2025-04-15 15:18:42 +0000 to 2025-04-27 09:44:23 +0000 - overriding-dependencies.md: better readability (rust-lang/cargo#15459) - source-replacement.md: fix typo (rust-lang/cargo#15458) - Stabilize automatic garbage collection. (rust-lang/cargo#14287) - Update doctest xcompile flags (rust-lang/cargo#15455) - fix: Suggest similar looking feature names when feature is missing (rust-lang/cargo#15454) - fix(unit-graph): switch to Package ID Spec (rust-lang/cargo#15447) - chore(deps): update cargo-semver-checks to v0.41.0 (rust-lang/cargo#15446) - Implement RFC3695: Allow boolean literals as cfg predicates (rust-lang/cargo#14649) - chore: remove duplicate word in comment (rust-lang/cargo#15437) - Fix formatting of CliUnstable parsing (rust-lang/cargo#15434) r? ghost
[rendered](https://github.com/weihanglo/cargo/blob/version-bump/src/doc/src/CHANGELOG.md) or preview through `mdbook serve src/doc` --- Note that the long note of `-Zgc` stabilization is from Josh's comment here: <#14287 (comment)>
Pkgsrc changes: * Adjust patches to adapt to upstream changes and new versions. * associated checksums Upstream changes relative to 1.87.0: Version 1.88.0 (2025-06-26) ========================== Language -------- - [Stabilize `#![feature(let_chains)]` in the 2024 edition.] (rust-lang/rust#132833) This feature allows `&&`-chaining `let` statements inside `if` and `while`, allowing intermixture with boolean expressions. The patterns inside the `let` sub-expressions can be irrefutable or refutable. - [Stabilize `#![feature(naked_functions)]`.] (rust-lang/rust#134213) Naked functions allow writing functions with no compiler-generated epilogue and prologue, allowing full control over the generated assembly for a particular function. - [Stabilize `#![feature(cfg_boolean_literals)]`.] (rust-lang/rust#138632) This allows using boolean literals as `cfg` predicates, e.g. `#[cfg(true)]` and `#[cfg(false)]`. - [Fully de-stabilize the `#[bench]` attribute] (rust-lang/rust#134273). Usage of `#[bench]` without `#![feature(custom_test_frameworks)]` already triggered a deny-by-default future-incompatibility lint since Rust 1.77, but will now become a hard error. - [Add warn-by-default `dangerous_implicit_autorefs` lint against implicit autoref of raw pointer dereference.] (rust-lang/rust#123239) The lint [will be bumped to deny-by-default] (rust-lang/rust#141661) in the next version of Rust. - [Add `invalid_null_arguments` lint to prevent invalid usage of null pointers.] (rust-lang/rust#119220) This lint is uplifted from `clippy::invalid_null_ptr_usage`. - [Change trait impl candidate preference for builtin impls and trivial where-clauses.] (rust-lang/rust#138176) - [Check types of generic const parameter defaults] (rust-lang/rust#139646) Compiler -------- - [Stabilize `-Cdwarf-version` for selecting the version of DWARF debug information to generate.] (rust-lang/rust#136926) Platform Support ---------------- - [Demote `i686-pc-windows-gnu` to Tier 2.] (https://blog.rust-lang.org/2025/05/26/demoting-i686-pc-windows-gnu/) Refer to Rust's [platform support page][platform-support-doc] for more information on Rust's tiered platform support. [platform-support-doc]: https://doc.rust-lang.org/rustc/platform-support.html Libraries --------- - [Remove backticks from `#[should_panic]` test failure message.] (rust-lang/rust#136160) - [Guarantee that `[T; N]::from_fn` is generated in order of increasing indices.] (rust-lang/rust#139099), for those passing it a stateful closure. - [The libtest flag `--nocapture` is deprecated in favor of the more consistent `--no-capture` flag.] (rust-lang/rust#139224) - [Guarantee that `{float}::NAN` is a quiet NaN.] (rust-lang/rust#139483) Stabilized APIs --------------- - [`Cell::update`] (https://doc.rust-lang.org/stable/std/cell/struct.Cell.html#method.update) - [`impl Default for *const T`] (https://doc.rust-lang.org/nightly/std/primitive.pointer.html#impl-Default-for-*const+T) - [`impl Default for *mut T`] (https://doc.rust-lang.org/nightly/std/primitive.pointer.html#impl-Default-for-*mut+T) - [`HashMap::extract_if`] (https://doc.rust-lang.org/stable/std/collections/struct.HashMap.html#method.extract_if) - [`HashSet::extract_if`] (https://doc.rust-lang.org/stable/std/collections/struct.HashSet.html#method.extract_if) - [`proc_macro::Span::line`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.line) - [`proc_macro::Span::column`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.column) - [`proc_macro::Span::start`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.start) - [`proc_macro::Span::end`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.end) - [`proc_macro::Span::file`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.file) - [`proc_macro::Span::local_file`] (https://doc.rust-lang.org/stable/proc_macro/struct.Span.html#method.local_file) These previously stable APIs are now stable in const contexts: - [`NonNull<T>::replace`] (https://doc.rust-lang.org/stable/std/ptr/struct.NonNull.html#method.replace) - [`<*mut T>::replace`] (https://doc.rust-lang.org/stable/std/primitive.pointer.html#method.replace) - [`std::ptr::swap_nonoverlapping`] (rust-lang/rust#137280) - [`Cell::{replace, get, get_mut, from_mut, as_slice_of_cells}`] (rust-lang/rust#137928) Cargo ----- - [Stabilize automatic garbage collection.] (rust-lang/cargo#14287) - [use `zlib-rs` for gzip compression in rust code] (rust-lang/cargo#15417) Rustdoc ----- - [Doctests can be ignored based on target names using `ignore-*` attributes.] (rust-lang/rust#137096) - [Stabilize the `--test-runtool` and `--test-runtool-arg` CLI options to specify a program (like qemu) and its arguments to run a doctest.] (rust-lang/rust#137096) Compatibility Notes ------------------- - [Finish changing the internal representation of pasted tokens] (rust-lang/rust#124141). Certain invalid declarative macros that were previously accepted in obscure circumstances are now correctly rejected by the compiler. Use of a `tt` fragment specifier can often fix these macros. - [Fully de-stabilize the `#[bench]` attribute] (rust-lang/rust#134273). Usage of `#[bench]` without `#![feature(custom_test_frameworks)]` already triggered a deny-by-default future-incompatibility lint since Rust 1.77, but will now become a hard error. - [Fix borrow checking some always-true patterns.] (rust-lang/rust#139042) The borrow checker was overly permissive in some cases, allowing programs that shouldn't have compiled. - [Update the minimum external LLVM to 19.] (rust-lang/rust#139275) - [Make it a hard error to use a vector type with a non-Rust ABI without enabling the required target feature.] (rust-lang/rust#139309)
This proposes to stabilize automatic garbage collection of Cargo's global cache data in the cargo home directory.
What is being stabilized?
This PR stabilizes automatic garbage collection, which is triggered at most once per day by default. This automatic gc will delete old, unused files in cargo's home directory.
It will delete files that need to be downloaded from the network after 3 months, and files that can be generated without network access after 1 month. These thresholds are intended to balance the intent of reducing cargo's disk usage versus deleting too often forcing cargo to do extra work when files are missing.
Tracking of the last-use data is stored in a sqlite database in the cargo home directory. Cargo updates timestamps in that database whenever it accesses a file in the cache. This part is already stabilized.
This PR also stabilizes the
gc.auto.frequencyconfiguration option. The primary use case for when a user may want to set that is to set it to "never" to disable gc should the need arise to avoid it.When gc is initiated, and there are files to delete, there will be a progress bar while it is deleting them. The progress bar will disappear when it finishes. If the user runs with
-vverbose option, then cargo will also display which files it deletes.If there is an error while cleaning, cargo will only display a warning, and otherwise continue.
What is not being stabilized?
The manual garbage collection option (via
cargo clean gc) is not proposed to be stabilized at this time. That still needs some design work. This is tracked in #13060.Additionally, there are several low-level config options currently implemented which define the thresholds for when it will delete files. I think these options are probably too low-level and specific. This is tracked in #13061.
Garbage collection of build artifacts is not yet implemented, and tracked in #13136.
Background
This feature is tracked in #12633 and was implemented in a variety of PRs, primarily #12634.
The tests for this feature are located in https://github.com/rust-lang/cargo/blob/master/tests/testsuite/global_cache_tracker.rs.
Cargo started tracking the last-use data on stable via #13492 in 1.78 which was released 2024-05-02. This PR is proposing to stabilize automatic deletion in 1.82 which will be released in 2024-10-17.
Risks
Users who frequently use versions of Rust older than 1.78 will not have the last-use data tracking updated. If they infrequently use 1.78 or newer, and use the same cache files, then the last-use tracking will only be updated by the newer versions. If that time frame is more than 1 month (or 3 months for downloaded data), then cargo will delete files that the older versions are still using. This means the next time they run the older version, it will have to re-download or re-extract the files.
The effects of deleting cache data in environments where cargo's cache is modified by external tools is not fully known. For example, CI caching systems may save and restore cargo's cache. Similarly, things like Docker images that try to save the cache in a layer, or mount the cache in a read-only filesystem may have undesirable interactions.
The once-a-day performance hit might be noticeable to some people. I've been using this for several months, and almost never notice it. However, slower systems, or situations where there is a lot of data to delete might take a while (on the order of seconds hopefully).