[data] update datasets API structure#27592
Conversation
Signed-off-by: Matthew Deng <matt@anyscale.com>
Signed-off-by: Matthew Deng <matt@anyscale.com>
Signed-off-by: Matthew Deng <matt@anyscale.com>
Signed-off-by: Matthew Deng <matt@anyscale.com>
|
This is looking awesome! The main thing that needs to be tweaked is the CSS around the autosummary tables; it looks like its bleeding into the right sidebar which is causing the docstring summaries to be cut off, but if it were properly constrained to its box, those docstring summaries should properly wrap. Also I don't know if the tabbed view is going to work since there are a lot of tabs and the tab titles are too long... I think that a flat layout at the top of the page, or breaking up the autosummary into each section, would be less clunky. |
doc/source/data/api/dataset.rst
Outdated
| ray.data.Dataset.randomize_block_order | ||
| ray.data.Dataset.repartition | ||
|
|
||
| .. tabbed:: Splitting and Merging Datasets |
There was a problem hiding this comment.
May be a bit tricky going forward, merging ops are transformations and splitting ops are consumptions.
There was a problem hiding this comment.
Any concrete suggestions for how to structure this in this PR? (As a user I don't think I'd immediately go to Consuming Datasets if I were looking to split my dataset.
Yep this just got fixed in master yesterday! #27611 Will merge master to include this.
Agreed, do you have a preference? |
|
@matthewdeng How about a single mono-table at the top, ordered alphabetically, with just the method names instead of the |
Signed-off-by: Matthew Deng <matt@anyscale.com>
Signed-off-by: Matthew Deng <matt@anyscale.com>
|
@clarkzinzow updated the summary tables!
|
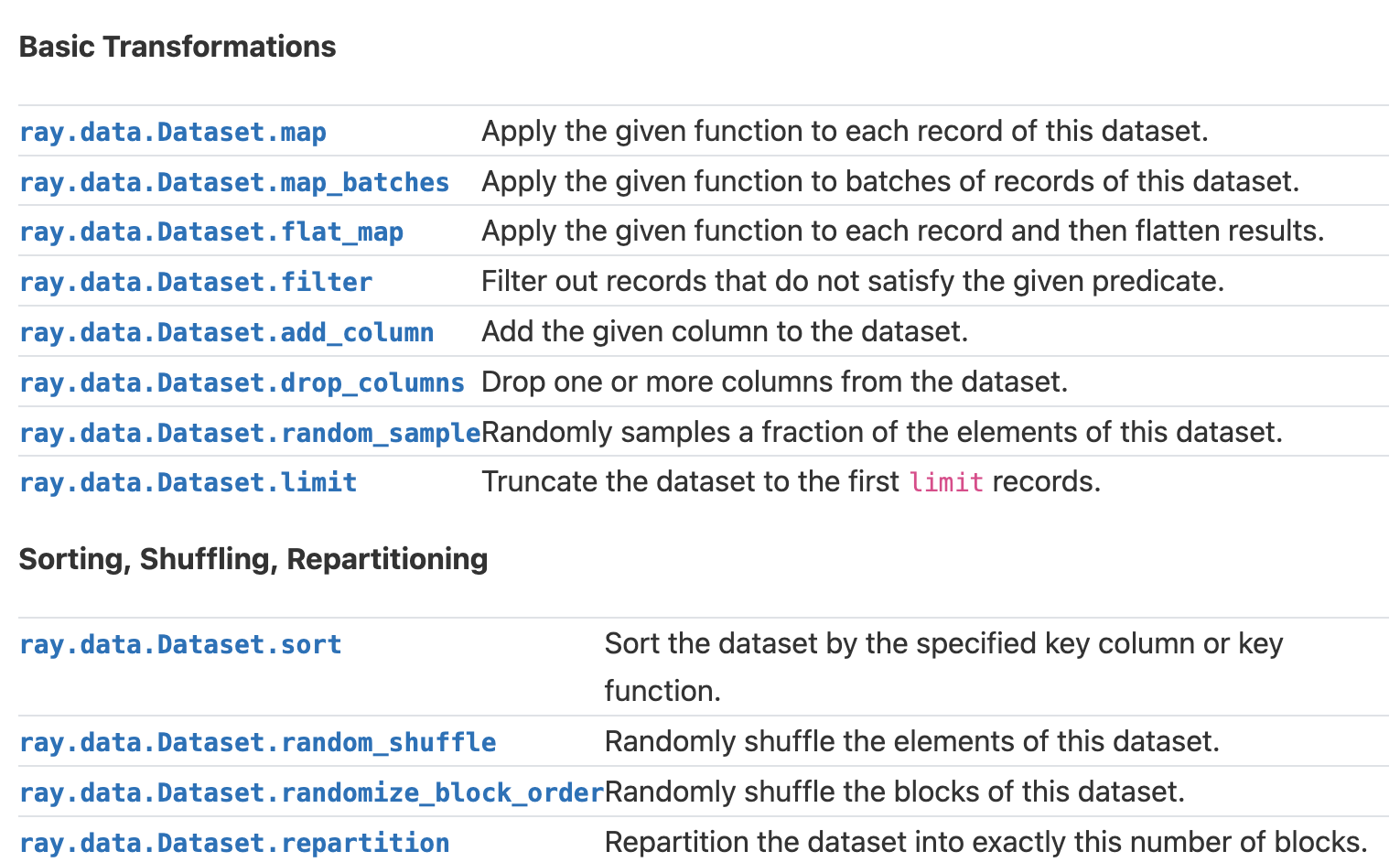
|
@matthewdeng Awesome, that's way better! I'll do a full review of this this morning. The table width still seems to be off (running under the right sidebar) but it looks like you already merged master. 🤔 Any idea what's going on there? |
|
@clarkzinzow yeah looks like the generated docs are from the commit before Let me try to trigger it again... |
|
|
||
| .. automethod:: ray.data.DatasetPipeline.stats | ||
|
|
||
| .. automethod:: ray.data.DatasetPipeline.sum No newline at end of file |
There was a problem hiding this comment.
Note: I wasn't sure where to put this one, seems kind of out of place but I also didn't want to create an entire Grouped and Global Aggregations section just for this.
 clarkzinzow
left a comment
clarkzinzow
left a comment
There was a problem hiding this comment.
LGTM overall, mostly just a few nits
|
|
||
| Ray Datasets API | ||
| ================ | ||
| Input/Output |
There was a problem hiding this comment.
I see that you went with a flat list rather than grouping these APIs by data type, e.g. tabular, tensor, text, binary, etc. Looking at it now, I think that the flat list is better for quick discoverability, but we might want to reexamine such a grouping if we add support for a few more file formats to keep this section's size in the ToC manageable.
But yeah, the flat list looks good to me for now!
There was a problem hiding this comment.
Yeah, basically we can follow the headers in https://docs.ray.io/en/master/data/creating-datasets.html, let me know if you think it's worthwhile to add in this PR!
There was a problem hiding this comment.
I think the current flat list looks good to me!
| ray.data.DatasetPipeline.split | ||
| ray.data.DatasetPipeline.split_at_indices | ||
|
|
||
| **Creating DatasetPipelines** |
There was a problem hiding this comment.
I feel like there's a better name for this section, but I haven't been able to think of one.
|
|
||
| .. automethod:: ray.data.DatasetPipeline.add_column | ||
|
|
||
| .. automethod:: ray.data.DatasetPipeline.drop_columns |
There was a problem hiding this comment.
It would be great if these could pop up in the right sidebar, nested under the section title, while scrolling as is done for subsections, but unfortunately that doesn't appear to be possible either: sphinx-doc/sphinx#6316
Signed-off-by: Matthew Deng <matt@anyscale.com>
 c21
left a comment
c21
left a comment
There was a problem hiding this comment.
LGTM. Seeing a conflict with master needed to be resolved.
clarkzinzow
left a comment
There was a problem hiding this comment.
LGTM, awesome work! 🎉
| .. autosummary:: | ||
| :nosignatures: | ||
|
|
||
| ray.data.Dataset.map |
There was a problem hiding this comment.
A stretch request: add a ref to each API, so that we can pinpoint to individual API, which is useful. I think what's needed is adding something like ".. _dataset-map-ref:".
There was a problem hiding this comment.
This should already be natively supported!
:py:meth:`ray.data.Dataset.map`
There was a problem hiding this comment.
@jianoaix For the individual APIs, that should already be doable with cross-referencing via e.g. :meth:`ray.data.Dataset.map`
There was a problem hiding this comment.
OK, can it be linked with a url? e.g. https://docs.ray.io/en/master/data/package-ref.html#dataset-api, if we point a user to map(), can we give a ulr pointing to it?
There was a problem hiding this comment.
Found it: https://docs.ray.io/en/master/data/package-ref.html#ray.data.Dataset.map. I guess I was looking at the navigation list on the right-hand-side which doesn't show it.
| ray.data.Dataset.write_csv | ||
| ray.data.Dataset.write_numpy | ||
| ray.data.Dataset.write_datasource | ||
| ray.data.Dataset.to_torch |
There was a problem hiding this comment.
Should we actually deprecate these two in 2.0?
Refactor Datasets API docs for easier navigation: [Ray Datasets API](https://ray--27592.org.readthedocs.build/en/27592/data/api/api.html) 1. Create a new Datasets API base page. 2. Split existing APIs into separate pages. 3. Split `Dataset` and `DatasetPipeline` methods into separate sections. 1. Used `autosummary` to generate overview tables at the top of each of these pages. Open to other suggestions e.g. moving the summary to the top of each section instead. 2. **Note:** Every time we add a new method we need to explicitly add it here as well. 4. Add Input/Output APIs. 1. I chose to split these primarily by data format rather than type, since it's easier to navigate, and the existing [Creating Datasets](https://docs.ray.io/en/master/data/creating-datasets.html) User Guide already does the latter. 6. Add `Block` and `DataBatch` (should we add these aliases?) 7. Remove existing `package-ref`.
Refactor Datasets API docs for easier navigation: [Ray Datasets API](https://ray--27592.org.readthedocs.build/en/27592/data/api/api.html) ### Changes 1. Create a new Datasets API base page. 2. Split existing APIs into separate pages. 3. Split `Dataset` and `DatasetPipeline` methods into separate sections. 1. Used `autosummary` to generate overview tables at the top of each of these pages. Open to other suggestions e.g. moving the summary to the top of each section instead. 2. **Note:** Every time we add a new method we need to explicitly add it here as well. 4. Add Input/Output APIs. 1. I chose to split these primarily by data format rather than type, since it's easier to navigate, and the existing [Creating Datasets](https://docs.ray.io/en/master/data/creating-datasets.html) User Guide already does the latter. 6. Add `Block` and `DataBatch` (should we add these aliases?) 7. Remove existing `package-ref`. Signed-off-by: Stefan van der Kleij <s.vanderkleij@viroteq.com>
Signed-off-by: Matthew Deng matt@anyscale.com
Why are these changes needed?
Refactor Datasets API docs for easier navigation: Ray Datasets API
Changes
DatasetandDatasetPipelinemethods into separate sections.autosummaryto generate overview tables at the top of each of these pages. Open to other suggestions e.g. moving the summary to the top of each section instead.BlockandDataBatch(should we add these aliases?)package-ref.Related issue number
Checks
git commit -s) in this PR.scripts/format.shto lint the changes in this PR.