Bug 1953798: Add apiserver burn rate SLO alerts#1126
Bug 1953798: Add apiserver burn rate SLO alerts#1126openshift-merge-robot merged 2 commits intoopenshift:masterfrom ihcsim:apiserver-errorbudgetburn-alert
Conversation
|
@ihcsim: This pull request references Bugzilla bug 1953798, which is valid. The bug has been moved to the POST state. The bug has been updated to refer to the pull request using the external bug tracker. 3 validation(s) were run on this bug
Requesting review from QA contact: DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
[APPROVALNOTIFIER] This PR is NOT APPROVED This pull-request has been approved by: ihcsim The full list of commands accepted by this bot can be found here. DetailsNeeds approval from an approver in each of these files:Approvers can indicate their approval by writing |
|
@ihcsim: This pull request references Bugzilla bug 1953798, which is valid. 3 validation(s) were run on this bug
Requesting review from QA contact: DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
@smarterclayton Per slack convo, I replaced the old recording rules with the ones defined in the BZ, and excluded the subresources from the resource-scoped calculation. The results of the new and old rules look comparable when tested on my dev cluster, which makes me think that we can replace the old rules entirely. The new burn-type groupings also make things easier to reason about. The trend of the aggregation rates looks almost identical at a lower time range. E.g. with
At a higher time range, even though the shape of the charts looks different (due to the groupings), the values still fall closely within the same range. E.g., with
|
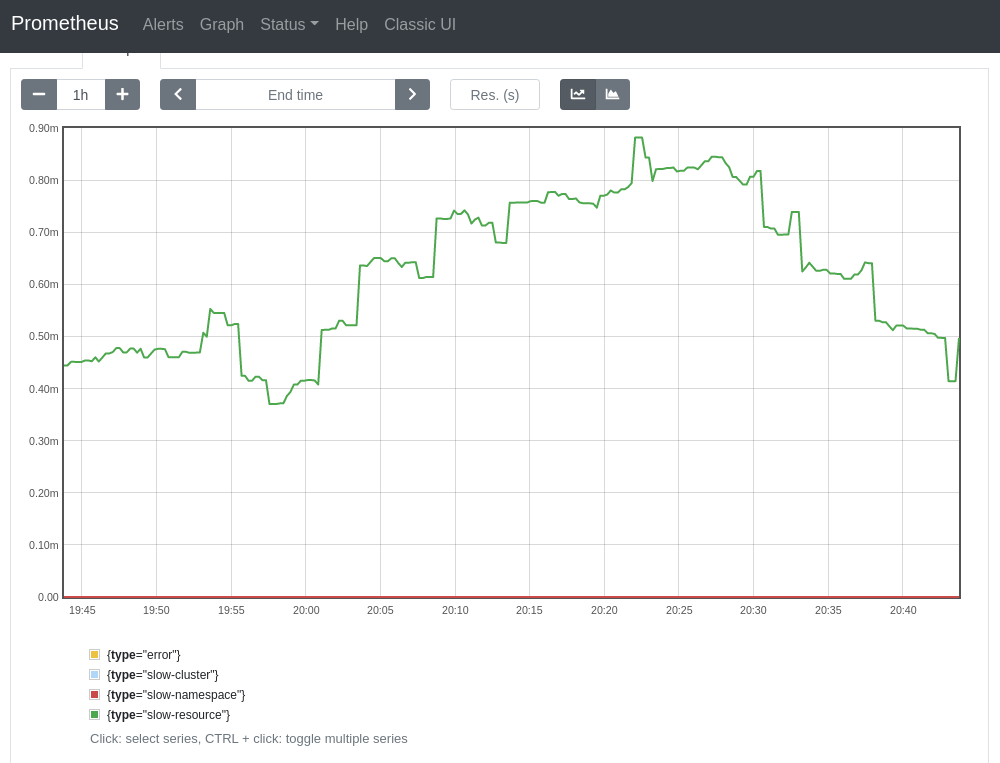
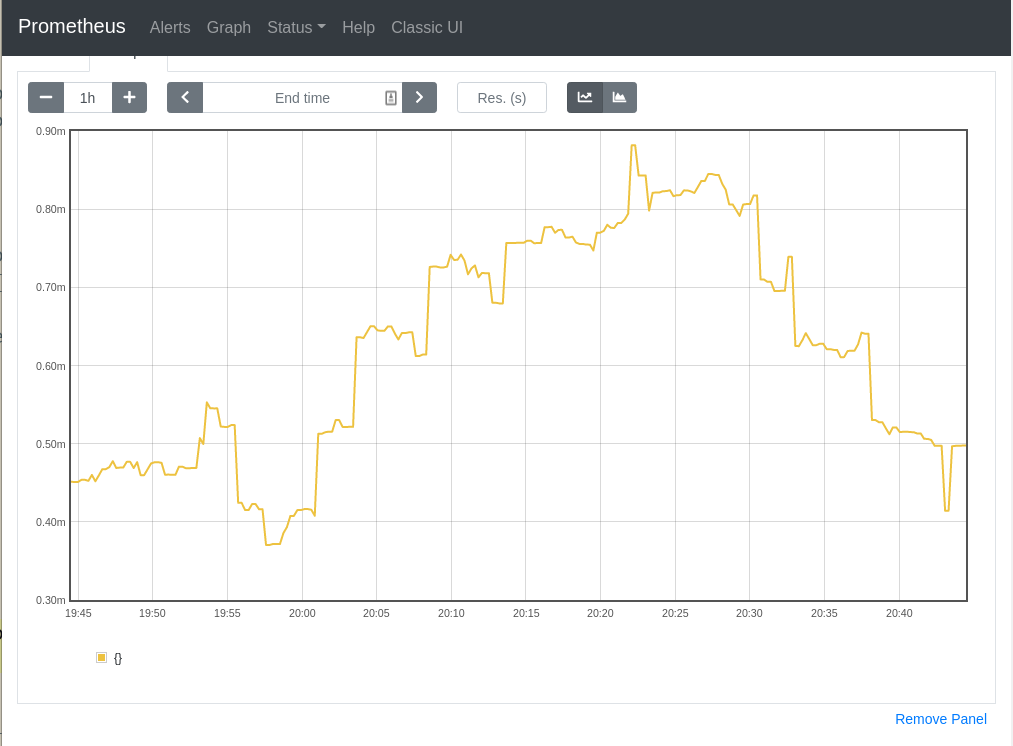
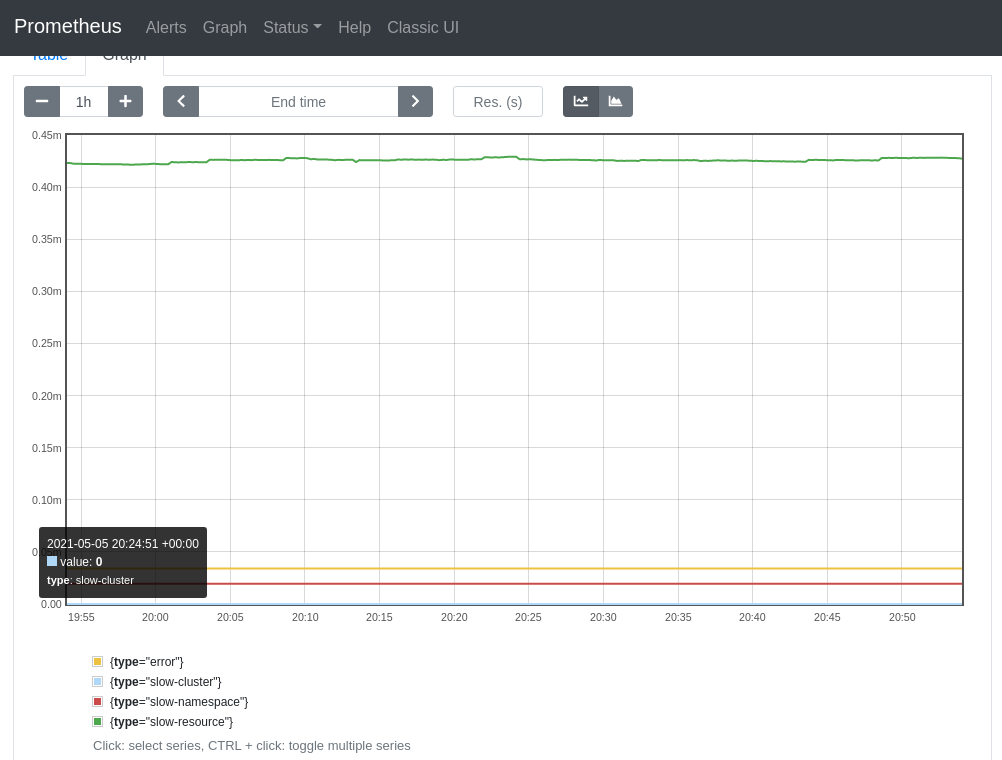
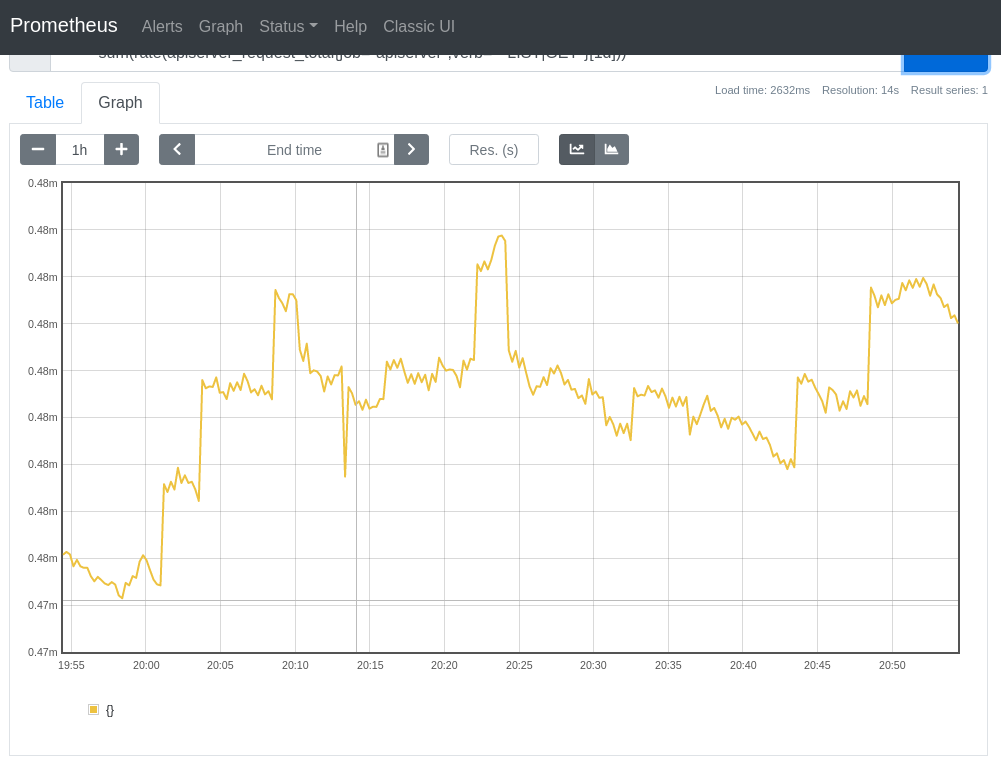
| rules: | ||
| - expr: | | ||
| # error | ||
| label_replace( |
There was a problem hiding this comment.
I'm wondering whether I recommended a bad factoring here - it's possible that the rules with / and label matching this doesn't compose like it would in normal math rules.
There was a problem hiding this comment.
Ok, I I think I figured out what the confusion was (your code is right). I was looking for the highest rate of slowest request query which roughly looks like:
sum without (instance) (rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET",scope=~"resource|"}[30m]))
- (
sum without (instance,le) (rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30m]))
or
vector(0)
)
The graph of this shows "biggest contribution to slow resource requests"
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="apiserver.openshift.io", job="apiserver", namespace="default", resource="apirequestcounts", scope="resource", service="kubernetes", verb="GET", version="v1"} | 3.1326662908397314
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="serviceaccounts", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.9384180790960457
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="pods", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.7807909604519772
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="configmaps", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.7785310734463291
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="secrets", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.507344632768362
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="namespaces", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.4881355932203384
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="pods", scope="resource", service="kubernetes", subresource="log", verb="GET", version="v1"} | 0.42126925907526447
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="rbac.authorization.k8s.io", job="apiserver", namespace="default", resource="clusterrolebindings", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.40677966101694807
{apiserver="kube-apiserver", endpoint="https", job="apiserver", namespace="default", service="kubernetes", subresource="/readyz", verb="GET"} | 0.3903954802259868
{apiserver="kube-apiserver", component="apiserver", endpoint="https", job="apiserver", namespace="default", resource="services", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.17457627118644137
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="apps", job="apiserver", namespace="default", resource="deployments", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.17344632768361556
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="rbac.authorization.k8s.io", job="apiserver", namespace="default", resource="rolebindings", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.167796610169491
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="apiextensions.k8s.io", job="apiserver", namespace="default", resource="customresourcedefinitions", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.15932203389830524
{apiserver="kube-apiserver", component="apiserver", endpoint="https", group="rbac.authorization.k8s.io", job="apiserver", namespace="default", resource="clusterroles", scope="resource", service="kubernetes", verb="GET", version="v1"} | 0.12655367231638337
So it looks like apirequestcounts is the biggest contributor
| sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|log|exec",scope=~"resource|"}[5m])) | ||
| - | ||
| (sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|log|exec",scope=~"resource|",le="0.1"}[5m])) or vector(0)) | ||
| ) / scalar(sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|log|exec"}[5m]))) |
There was a problem hiding this comment.
One problem here is that if anyone ever adds a new scope this would be off. I think it's ok for now (because scope covers all the possible values), but we'd need to be aware of that.
|
@ihcsim: This pull request references Bugzilla bug 1953798, which is valid. 3 validation(s) were run on this bug
Requesting review from QA contact: DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
| ( | ||
| ( | ||
| # too slow | ||
| sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h])) |
There was a problem hiding this comment.
Doesn't exclude imageimport? I guess we can handle this separately later.
There was a problem hiding this comment.
Yeah, I added these write rules as-is from upstream. Do we foresee image resources contribute to significant burns? Don't image imports get auto-pruned anyway?
|
The read metrics look ok. We can defer improving the write ones to later since they look correct today. |
|
Can you link the PR to remove the old alerts here? |
|
@ihcsim: This pull request references Bugzilla bug 1953798, which is valid. 3 validation(s) were run on this bug
Requesting review from QA contact: DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
The PR to remove the same alerts from CMO is at openshift/cluster-monitoring-operator#1164. |
|
/retest |
|
/approve |
|
/test all This is looking good - while we've talked about removing the alert, I'm tempted to say the current alert is sufficient to merge and then we can remove prior to 4.8. |
|
/retest |
These alerts and recording rules are transferred from the monitoring stack to CKAO for easier management. See openshift/cluster-monitoring-operator#1164 Signed-off-by: Ivan Sim <isim@redhat.com>
The new recording rules exclude long-running requests to subresources from the resource-scoped and namespace-scoped requests. They also break down slow request distributions by scopes. Signed-off-by: Ivan Sim <isim@redhat.com>
|
@sttts Per slack convo, I separated the PR into two commits, to make future tracking easier. The first commit has the original alerts and rules, and the second has the new rules. |
|
Factoring looks good. With @smarterclayton's lgtm #1126 (comment) for the actual alert expressions. /lgtm |
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: ihcsim, smarterclayton, sttts The full list of commands accepted by this bot can be found here. The pull request process is described here DetailsNeeds approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
/retest |
|
/retest Please review the full test history for this PR and help us cut down flakes. |
|
@ihcsim: The following tests failed, say
Full PR test history. Your PR dashboard. DetailsInstructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. I understand the commands that are listed here. |
|
/retest |
|
/retest Please review the full test history for this PR and help us cut down flakes. |
|
@ihcsim: All pull requests linked via external trackers have merged:
Bugzilla bug 1953798 has been moved to the MODIFIED state. DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
This PR copies the upstream
KubeAPIErrorBudgetBurnalerts and its recordingrules to CKAO. It updates the rules to:
proxy,logs,execetc.,from the error budget calculation. As described in
https://bugzilla.redhat.com/show_bug.cgi?id=1953798#c1, these long-running
GET,LISTrequests are causing flakiness in the e2e parallel and upgradejobs, due to slow resource reads.
scope(i.e.resource,namespace,cluster).Subsequent PRs to fix other parts of the e2e test suites will follow, if the changes
in this PR don't fully eliminate the flakiness.
As part of the work to complete 1953798, a separate PR will also be submitted toCMO to remove (disable, mask etc.) the same alerts.The PR to remove the same alerts from CMO is at
openshift/cluster-monitoring-operator#1164.
Signed-off-by: Ivan Sim isim@redhat.com