[Feature] Truncate based on the sign of advantage after clipping #340
Conversation
Summary of ChangesHello @Qwtdgh, I'm Gemini Code Assist1! I'm currently reviewing this pull request and will post my feedback shortly. In the meantime, here's a summary to help you and other reviewers quickly get up to speed! This pull request introduces the Dual-Clip Proximal Policy Optimization (PPO) algorithm, an advanced variant of PPO designed to enhance policy stability, particularly when dealing with negative advantages. The core change involves a new policy loss function that applies an additional clipping mechanism, controlled by Highlights
Using Gemini Code AssistThe full guide for Gemini Code Assist can be found on our documentation page, here are some quick tips. Invoking Gemini You can request assistance from Gemini at any point by creating a comment using either
Customization To customize Gemini Code Assist for GitHub experience, repository maintainers can create a configuration file and/or provide a custom code review style guide (such as PEP-8 for Python) by creating and adding files to a Limitations & Feedback Gemini Code Assist may make mistakes. Please leave feedback on any instances where its feedback is incorrect or counter productive. You can react with 👍 and 👎 on @gemini-code-assist comments. If you're interested in giving your feedback about your experience with Gemini Code Assist for Github and other Google products, sign up here. You can also get AI-powered code generation, chat, as well as code reviews directly in the IDE at no cost with the Gemini Code Assist IDE Extension. Footnotes
|
There was a problem hiding this comment.
Code Review
This pull request introduces the Dual-Clip PPO policy loss function, a variant of PPO designed to improve stability when advantages are negative. The implementation correctly follows the logic described in the paper and the PR description. A corresponding unit test is also added. My review includes suggestions to refactor the __init__ method for better readability and type safety, which in turn allows for the removal of several type: ignore comments. I've also pointed out minor issues like a debug print statement in tests and stylistic improvements.
|
Hi, thank you for your contribution! I noticed a typo in the PR description formula; it should be Also, I think the functionality of this PR overlaps with #334. The implementations should be equivalent when setting Specifically:
When Should we consider consolidating these two PRs? |
|
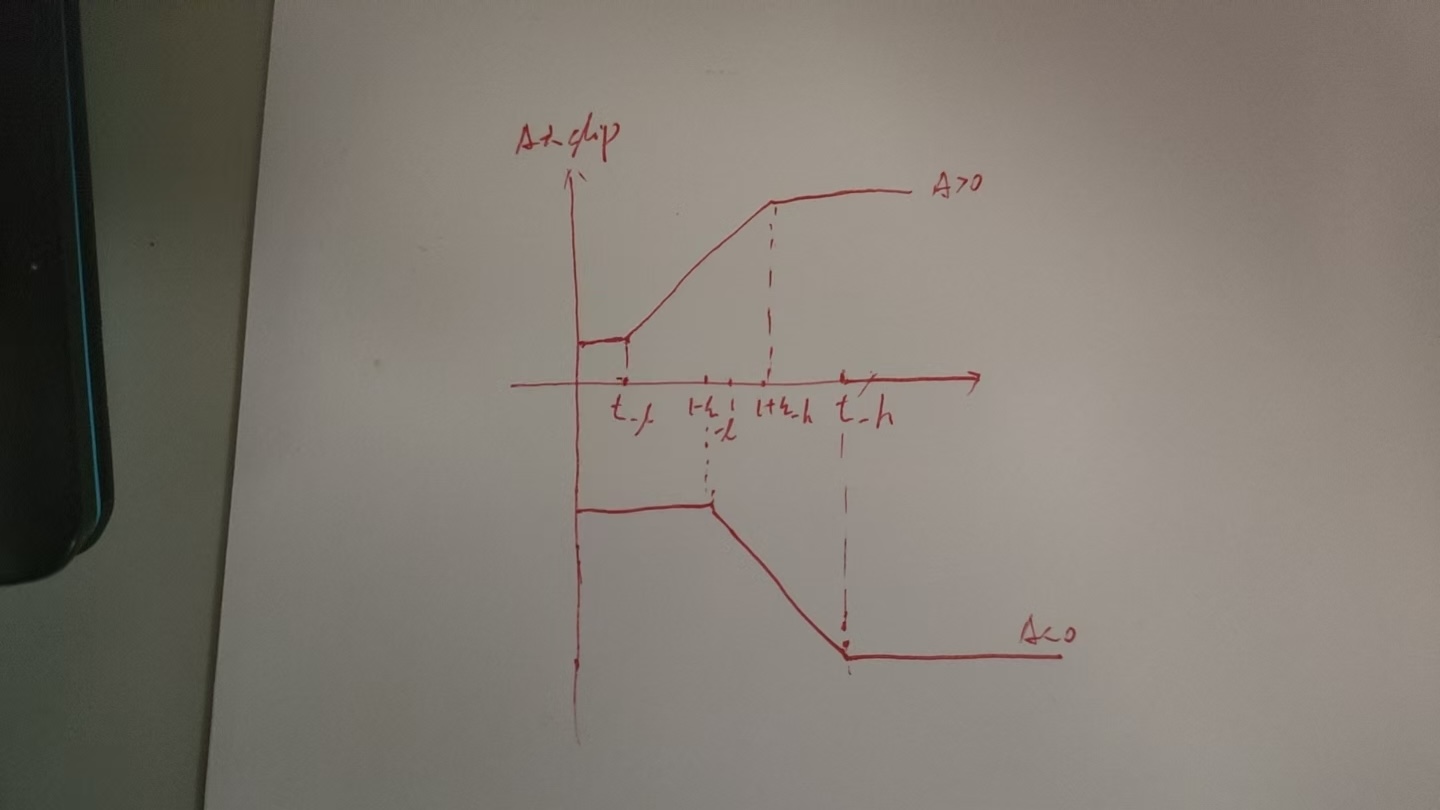
Yes @garyzhang99 . Besides, this PR decomposes the truncation of The #334 does truncating and clipping in the following order:
However, based on the implement of ppo loss in verl/core_algos.py as follows, we can find it first clips the
negative_approx_kl = log_prob - old_log_prob
# Clamp negative_approx_kl for stability
negative_approx_kl = torch.clamp(negative_approx_kl, min=-20.0, max=20.0)
ratio = torch.exp(negative_approx_kl)
ppo_kl = verl_F.masked_mean(-negative_approx_kl, response_mask)
#######################################
# 1. Clip the -A * ratio
pg_losses1 = -advantages * ratio
if cliprange_low is None:
cliprange_low = cliprange
if cliprange_high is None:
cliprange_high = cliprange
pg_losses2 = -advantages * torch.clamp(
ratio, 1 - cliprange_low, 1 + cliprange_high
) # - clip(ratio, 1-cliprange, 1+cliprange) * A
clip_pg_losses1 = torch.maximum(
pg_losses1, pg_losses2
) # max(-ratio * A, -clip(ratio, 1-cliprange, 1+cliprange) * A)
pg_clipfrac = verl_F.masked_mean(torch.gt(pg_losses2, pg_losses1).float(), response_mask)
#######################################
# 2. Truncate the -A * ratio
pg_losses3 = -advantages * clip_ratio_c
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1)
pg_clipfrac_lower = verl_F.masked_mean(
torch.gt(clip_pg_losses1, pg_losses3) * (advantages < 0).float(), response_mask
)
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)
pg_loss = agg_loss(loss_mat=pg_losses, loss_mask=response_mask, loss_agg_mode=loss_agg_mode)Since, to imporve the readability of code implement and decompose with different signs of advantage, I convert the #334 into clipping followed by truncating. Notably, the formular of #334 is: Convert it to clipping followed by truncating. It is intuitive that The above formula is equivalent to the following formula, which first clips Since, the loss in #334 only depends on To further decompose on the advantage dimension, we need to the following two arguments to replace the
Since, when we set For example: I have rebased #344 into this PR. The main implement of # First clipping by clip_range, and calculate pg_clipfrac
pg_losses1 = -advantages * ratio
pg_losses2 = -advantages * torch.clamp(
ratio, 1.0 - self.clip_range_low, 1.0 + self.clip_range_high # type: ignore
)
pg_losses_clip = torch.maximum(pg_losses1, pg_losses2)
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses1).float(), action_mask)
# Add IS truncation for positive advantages
if self.truncate_adv_pos_is:
pg_losses_pos_trunc = -advantages * self.truncate_is_range_low
pg_truncfrac_pos = masked_mean(
torch.lt(pg_losses_pos_trunc, pg_losses_trunc) * (advantages > 0).float(),
action_mask,
)
pg_losses_pos = torch.minimum(pg_losses_trunc, pg_losses_pos_trunc)
pg_losses_trunc = torch.where(advantages > 0, pg_losses_pos, pg_losses_trunc)
# Add IS truncation for negative advantages
if self.truncate_adv_neg_is:
pg_losses_neg_trunc = -advantages * self.truncate_is_range_high
pg_truncfrac_neg = masked_mean(
torch.lt(pg_losses_neg_trunc, pg_losses_trunc) * (advantages < 0).float(),
action_mask,
)
pg_losses_neg = torch.minimum(pg_losses_trunc, pg_losses_neg_trunc)
pg_losses_trunc = torch.where(advantages < 0, pg_losses_neg, pg_losses_trunc) |
{kind=link}
|
/unittest-module-algorithm |
Summary
Tests
Github Test Reporter by CTRF 💚 |
| assert ( | ||
| self.truncate_is_range_low >= 0.0 | ||
| ), "truncate_is_range_low must be non-negative." | ||
| assert (self.truncate_is_range_low < 1.0-self.clip_range_low |
There was a problem hiding this comment.
| assert (self.truncate_is_range_low < 1.0-self.clip_range_low | |
| assert (self.truncate_is_range_low < 1.0 - self.clip_range_low |
| self.truncate_is_range_high is not None | ||
| ), "truncate_is_range_high must be specified." | ||
| assert ( | ||
| self.truncate_is_range_high > 1.0+self.clip_range_high |
There was a problem hiding this comment.
| self.truncate_is_range_high > 1.0+self.clip_range_high | |
| self.truncate_is_range_high > 1.0 + self.clip_range_high |
| if self.truncate_adv_pos_is: | ||
| pg_losses_pos_trunc = -advantages * self.truncate_is_range_low | ||
| pg_truncfrac_pos = masked_mean( | ||
| torch.lt(pg_losses_pos_trunc, pg_losses_trunc) * (advantages > 0).float(), |
There was a problem hiding this comment.
| torch.lt(pg_losses_pos_trunc, pg_losses_trunc) * (advantages > 0).float(), | |
| torch.lt(pg_losses_pos_trunc, pg_losses_trunc).float() * (advantages > 0), |
| if self.truncate_adv_neg_is: | ||
| pg_losses_neg_trunc = -advantages * self.truncate_is_range_high | ||
| pg_truncfrac_neg = masked_mean( | ||
| torch.lt(pg_losses_neg_trunc, pg_losses_trunc) * (advantages < 0).float(), |
There was a problem hiding this comment.
| torch.lt(pg_losses_neg_trunc, pg_losses_trunc) * (advantages < 0).float(), | |
| torch.lt(pg_losses_neg_trunc, pg_losses_trunc).float() * (advantages < 0), |
|
Thanks for contributing @lehaoqu! Just want to say that we might need to take this PR slow and make sure everything is perfect, since |
Add Dual-Clip PPO, which utilizes the
clip_ratio_cto clip the ratio when the advantage is negative.The Loss formular of Dual-Clip PPO is following: