Let each individual interpreter configure completionKey #1
Conversation
|
@Leemoonsoo I have a couple of questions:
|
I think
I have no good idea on this. Candidates i can think are
Do you have any other idea? |
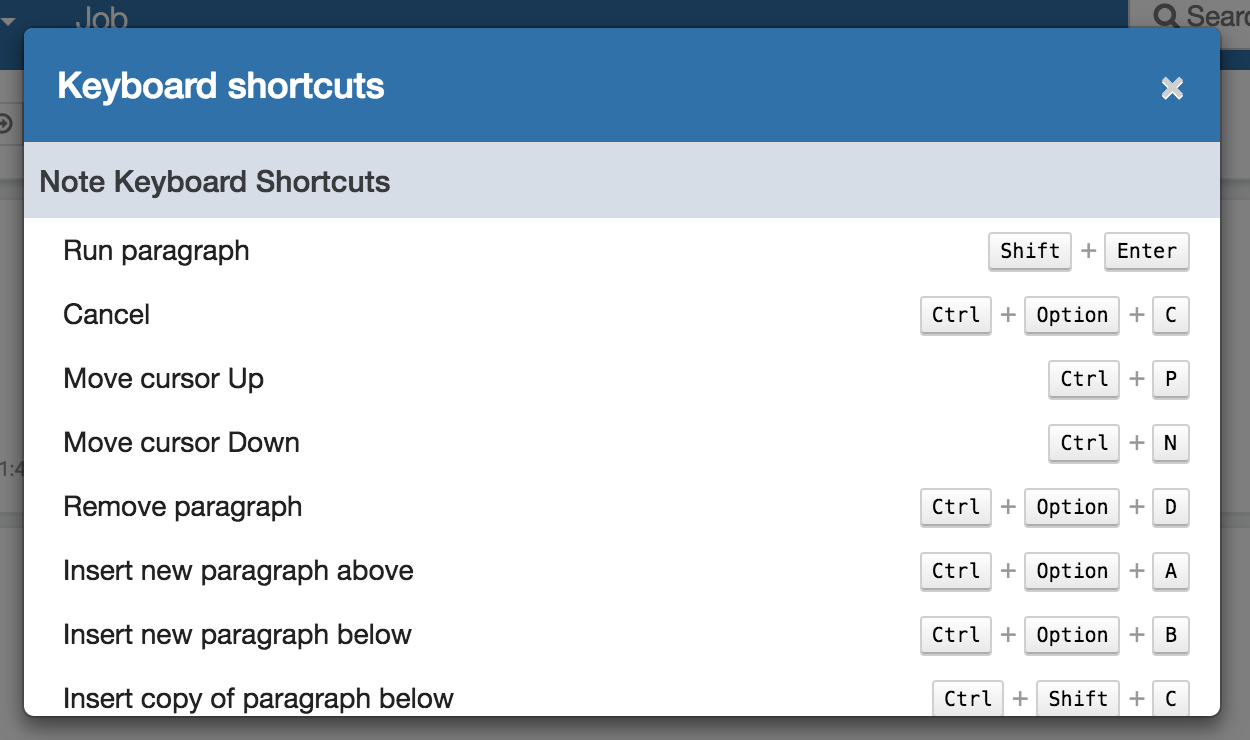
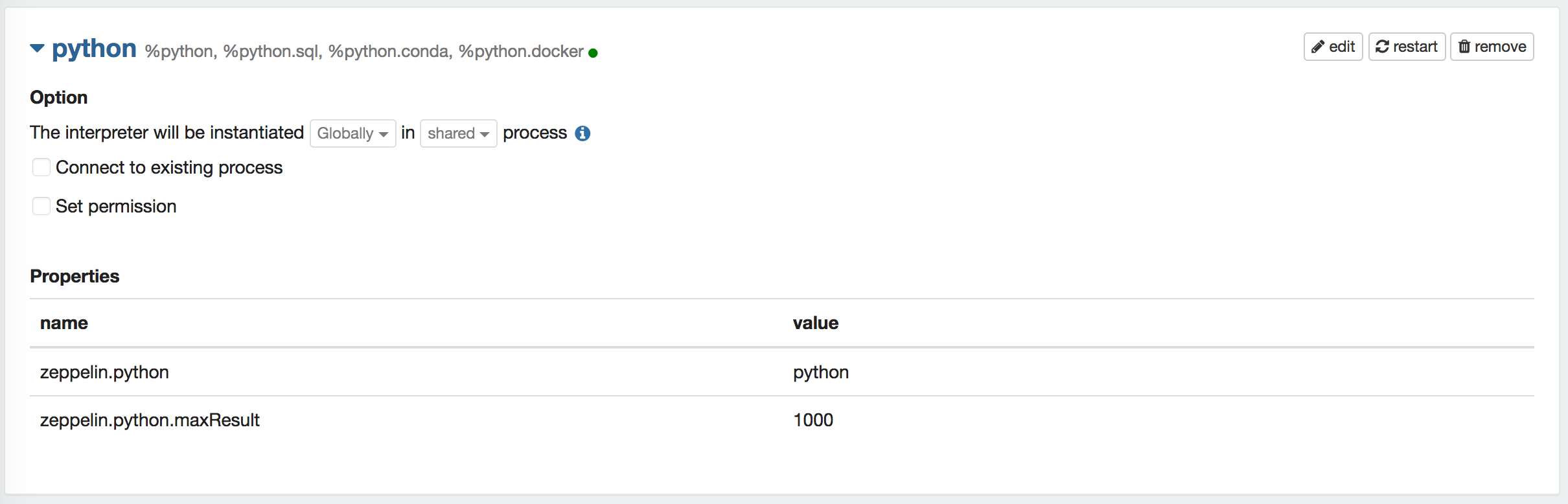
I think we should add a case to handle non-existent property so that, it can take care of this change even if the interpreter is old. What do you think?
I like the idea to add it as part of keyboard shortcuts rather than showing it in the interpreter settings so that user can see all the shortcuts from a single page instead of going through each interpreter. |
AFAIK, there's no good reason this property should be copied to conf/interpreter.json from Interpreter. We can just read the property from interpreter always. I filed an issue https://issues.apache.org/jira/browse/ZEPPELIN-2907 |
|
@Leemoonsoo I hit the interpreter.json upgrade issue when doing interpreter component refactoring, and I think I already fixed it. https://github.com/apache/zeppelin/blob/master/zeppelin-zengine/src/main/java/org/apache/zeppelin/interpreter/InterpreterSettingManager.java#L199 BTW, for the api stability/compatibility of zeppelin, there're 2 perspective IMO.
In the 0.8.0 (or at least before 1.0), I plan to make them stable |
…y '.' can not be found in docker environment ### What is this PR for? shell interpreter complained that working directory '.' can not be found in docker environment. I add a line of code to set current working directory to USER`s home, and it works. ### What type of PR is it? Bug Fix ### Todos * tests ### What is the Jira issue? https://issues.apache.org/jira/browse/ZEPPELIN-2841 ### How should this be tested? run shell interpreter`s test units ### Screenshots (if appropriate) ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No Author: Shu Jiaming <[email protected]> Author: 束佳明 <[email protected]> Closes apache#2521 from vistep/master and squashes the following commits: 34a0049 [Shu Jiaming] ZEPPELIN-2841 fix a bug where shell interpreter complained that working directory '.' can not be found while zeppelin was running in docker enviroment. d02104a [束佳明] Merge pull request #1 from apache/master
###What is this PR for? in save-as.service.js, if we use URI Data scheme, we could only contain 2MB data in chrome. using the createObjectURL and File API's blob feature, i managed to upgrade the capacity to about 900MB. plus this update is better in debugging too. if we exceed the 2MB limit in URI data scheme, the download just failed with no accurate console log originally, so it was kinda hard to know why this happens. But using this technique, if it exceeds the 900MB limit, the console log points directly about what the problem is. like this : Uncaught RangeError: Failed to construct 'Blob': Array length exceeds supported limit. https://github.com/apache/zeppelin/blob/master/zeppelin-web/src/app/notebook/save-as/save-as.service.js ###What type of PR is it? Improvement ###Todos nothing more i guess ###What is the Jira issue? https://issues.apache.org/jira/browse/ZEPPELIN-2850 ###How should this be tested? open zeppelin using chrome. make a table by select, then download it by csv or tsv. the table should be BIG, like really big, (but not that big for companies, which is my case) to test. in the original version if the whole data exceeds 2MB, you could see that the download fails. but using my script, it doesn't fail until it reaches about 900MB~1GB, which is a tremendous improvement. ###Screenshots (if appropriate) i'll post it later if you really need it. but i'm pretty sure you guys know what i'm talking about :) ###Questions: Does the licenses files need update? no (i guess) Is there breaking changes for older versions? no Does this needs documentation? maybe? Author: imnotkind <[email protected]> Closes apache#2532 from imnotkind/master and squashes the following commits: 075c4ec [imnotkind] Update save-as.service.js db778b1 [imnotkind] Merge pull request #1 from imnotkind/imnotkind-patch-1 e9ad52e [imnotkind] Update save-as.service.js
### What is this PR for? This PR will add tab as auto complete invoker if paragraph is non-md and user has not pressed the tab as a first character in the line ### What type of PR is it? [Improvement] ### What is the Jira issue? * https://issues.apache.org/jira/browse/ZEPPELIN-277 * https://issues.apache.org/jira/browse/ZEPPELIN-2736 ### How should this be tested? - Build: mvn clean package -Denforcer.skip -DskipTests -Drat.skip - Open a paragraph - Press tab with following options: first character, after space ### Questions: * Does the licenses files need an update? no * Is there breaking changes for older versions? no * Does this needs documentation? no Author: Malay Majithia <[email protected]> Author: Lee moon soo <[email protected]> Closes apache#2542 from malayhm/ZEPPELIN-277 and squashes the following commits: 436f22d [Malay Majithia] Added Tab auto completion flag for python sql and r b37e084 [Malay Majithia] Fixed lint error 18fc814 [Malay Majithia] Merge branch 'master' into ZEPPELIN-277 b09730e [Malay Majithia] Merge branch 'master' into ZEPPELIN-277 63d69e1 [Malay Majithia] Merge branch 'ZEPPELIN-277' of github.com:malayhm/zeppelin into ZEPPELIN-277 a75f0fe [Malay Majithia] Improved the first character check logic 2ec879d [Malay Majithia] Merge pull request #1 from Leemoonsoo/ZEPPELIN-277-completion-key 77afdba [Lee moon soo] fix style 77b47b6 [Malay Majithia] If all the previous line characters are tab, don't show autocomplete on tab 46f612a [Malay Majithia] ZEPPELIN-277 Add Tab as Autocomplete for Notebook non-md paragraphs 865c0a6 [Lee moon soo] Set python and spark interpreter completionKey 05d5860 [Lee moon soo] Update doc 973068b [Lee moon soo] apply tab completion based on editor.completionKey 5f4d81c [Malay Majithia] If all the previous line characters are tab, don't show autocomplete on tab 655ba88 [Malay Majithia] ZEPPELIN-277 Add Tab as Autocomplete for Notebook non-md paragraphs
### What is this PR for? This PR fixes the issue of newlines and tabs breaking results in the SQL interpreter in Livy. The Livy interpreter will return incorrect results if a row contains \n or \t characters. In the case of the newline, the result will be: Line is missing from results if the \n appears anywhere but the end of a cell `String index out of range: 17` if it appears at the end of a cell In the case of the tab, the result will be misaligned columns if the tab appears in the middle of a cell The output showing these error is attached to the Jira. I have changed the parsing and any newline or tab characters will be escaped ### What type of PR is it? Bug Fix ### What is the Jira issue? https://issues.apache.org/jira/browse/ZEPPELIN-3098 ### How should this be tested? Unittests have been added ### Screenshots (if appropriate) ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No Author: Alex Bush <[email protected]> Author: Alex Bush <[email protected]> Closes apache#2701 from bushnoh/zeppelin-3098 and squashes the following commits: 9f2f6e3 [Alex Bush] Merge pull request apache#3 from apache/master 14e120d [Alex Bush] Merge pull request apache#2 from apache/master 46981fd [Alex Bush] Merge pull request #1 from apache/master ee5a41b [Alex Bush] Merge remote-tracking branch 'upstream/master' 67a93b5 [Alex Bush] Merge branch 'master' of https://github.com/bushnoh/zeppelin 31cdbdc [Alex Bush] Added another comment explaining the regexp change d054af0 [Alex Bush] Force a dummy change for Travis 64a42be [Alex Bush] Fix for newline and tab in data
### What is this PR for? Spark 2.4 changed it's Scala version from 2.11.8 to 2.11.12 (see SPARK-24418). There are two problems for this upgrade at Zeppelin side: 1.. Some methods that are used in private by reflection, for instance, `loopPostInit` became inaccessible. See: - https://github.com/scala/scala/blob/v2.11.8/src/repl/scala/tools/nsc/interpreter/ILoop.scala - https://github.com/scala/scala/blob/v2.11.12/src/repl/scala/tools/nsc/interpreter/ILoop.scala To work around this, I manually ported `loopPostInit` at 2.11.8 to retain the behaviour. Some functions that are commonly existing at both Scala 2.11.8 and Scala 2.11.12 are used inside of the new `loopPostInit` by reflection. 2.. Upgrade from 2.11.8 to 2.11.12 requires `jline.version` upgrade. Otherwise, we will hit: ``` Caused by: java.lang.NoSuchMethodError: jline.console.completer.CandidateListCompletionHandler.setPrintSpaceAfterFullCompletion(Z)V at scala.tools.nsc.interpreter.jline.JLineConsoleReader.initCompletion(JLineReader.scala:139) ``` To work around this, I tweaked this by upgrading jline from `2.12.1` to `2.14.3`. ### What type of PR is it? [Improvement] ### Todos * [x] - Wait until Spark 2.4.0 is officially released. ### What is the Jira issue? * https://issues.apache.org/jira/browse/ZEPPELIN-3810 ### How should this be tested? Verified manually against Spark 2.4.0 RC3 ### Questions: * Does the licenses files need update? Yes * Is there breaking changes for older versions? No * Does this needs documentation? No Author: hyukjinkwon <[email protected]> Author: Hyukjin Kwon <[email protected]> Author: Jeff Zhang <[email protected]> Closes apache#3206 from HyukjinKwon/ZEPPELIN-3810 and squashes the following commits: c2456c9 [Hyukjin Kwon] Py4J 0.10.6 to 0.10.7 573f07d [Jeff Zhang] add test for spark 2.4 (#1) 9ac1797 [hyukjinkwon] Support Spark 2.4
This patch makes each interpreter choose completion key.
Tab completion key is applied to %python, %spark, %spark.sql, %spark.pyspark, %spark.dep interpreters.
One limitation is, interpreter setting pre-exists this patch does not apply tab completion.
New interpreter setting after this patch will work with tab completion.
Reason is, Zeppelin write editor configuration under conf/interpreter.json on interpreterSetting creation and read it. So even if an interpreter is upgraded and includes new editor configuration, zeppelin still reads old information from conf/interpreter.json unless user recreates it.
This is I think wrong behavior need to be addressed in a separate issue.
Please @malayhm take a look this patch and merge if you're okay.