![]()
README: English | Japanese (日本語)
Voice Activity Projection (VAP)のリアルタイム実装は、音声対話システムのターンテイキングなどへの応用を目的としています。VAP モデルは、ステレオ音声データ(対話参加者の 2 人分)を入力とし、直後の発話予測(p_now および p_future)を出力します。
VAP モデルに関する詳細は、以下のリポジトリでご確認ください。 https://github.com/ErikEkstedt/VoiceActivityProjection
このリポジトリでは、VAP モデルを CPU環境下でリアルタイムに動作させることができます。GPUを使用すると処理速度を高めることもできます。
このVAPプログラムは、TCP/IP接続を介して入力を受け取り、処理結果をTCP/IP接続で出力するプログラムとして動作します。したがって、あなた自身のプログラムは、TCP/IP経由でVAPプログラムに接続し、音声データを入力し、VAPの結果を受信することが典型的な使い方です。
デモ動画(YouTube) (https://www.youtube.com/watch?v=-uwB6yl2WtI)
- rvap
- vap_main - VAPメインディレクトリ
- vap_main - 相槌予測用VAPのメインディレクトリ
- common - 通信用のデータのエンコードとデコード方法など
- input - 入力用サンプルプログラム
- output - 出力用サンプルプログラム
- asset - VAPおよびCPC用のモデルファイル
- vap - VAPモデル
- cpc - 事前学習済みのCPCモデル
- Windows - WSLは対象外
- Mac -
output/gui.pyは対象外 - Linux
このソフトウェアにはPython環境(バージョン 3.9 以上)が必要です。
requirements.txt に記載されている必要なライブラリを参照してください。
以下のコマンドを使用して、ライブラリを直接インストールできます。
$ pip install -r requirements.txt
$ pip install -e .GPUを使用したい場合は requirements-gpu.txt を用いてください。
このシステムは3つのステップで使用できます。最初のステップはVAPモデルの主要部分であり、2番目と3番目のステップは入力と出力のためのオプションです。つまり、2番目と3番目のステップは自身で実装し、VAPに任意の音声データを入力し、VAPから処理結果を受け取ることができるように設計しています。
VAPプログラムを起動する際には、学習済みVAPモデルとCPCモデルの両方を指定します。入力と出力のTCP/IPのポート番号も指定できます。
使用するモデルのパラメータとして、vap_process_rate と context_len_sec を正しく設定する必要があります。
詳しくは、モデルの説明 を確認してください。
$ cd rvap/vap_main
$ python vap_main.py ^
--vap_model ../../asset/vap/vap_state_dict_jp_20hz_2500msec.pt ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--port_num_in 50007 ^
--port_num_out 50008 ^
--vap_process_rate 20 ^
--context_len_sec 2.5GPUを使用したい場合は、オプション --gpu を引数に追加してください。
次のようなメッセージが表示されます。
[IN] Waiting for connection of audio input...
サンプルデータのWavデータを入力するには、input/wav.pyを起動します。入力wavファイル名を指定できます。注意点として、このサンプル入力プログラムは、モデルの入力として個々のオーディオファイルと再生用の混合2チャンネルオーディオデータの両方を必要とします。また、VAPプログラムのTCP/IPのIPとポート番号も指定する必要があります。
$ cd input
$ python wav.py ^
--server_ip 127.0.0.1 ^
--port_num 50007 ^
--input_wav_left wav_sample/jpn_inoue_16k.wav ^
--input_wav_right wav_sample/jpn_sumida_16k.wav ^
--play_wav_stereo wav_sample/jpn_mix_16k.wavマイクからの入力オーディオをキャプチャするには、サンプルプログラムinput/mic.pyを参照してください。このプログラムは、デフォルトのマイクからのモノラルオーディオデータを取得し、それをVAPの入力形式に合わせてゼロデータと連結します。これは、一方の参加者が話している間にもう一方が沈黙していることを意味します。この方法は、音声対話システムにVAPモデルを実装するための1つの方法です。
$ cd input
$ python mic.py ^
--server_ip 127.0.0.1 ^
--port_num 50007VAPプログラムの処理結果をTCP/IP経由で取得できます。サンプルプログラムoutput/console.pyは、データを受信してコンソールに表示します。VAPプログラムのサーバーIPとポート番号を指定する必要があります。
$ cd output
$ python console.py ^
--server_ip 127.0.0.1 ^
--port_num 50008受信データを可視化するためのサンプルもoutput/gui.pyとして用意されています。このGUIプログラムはMac環境では動作しません。
$ cd output
$ python gui.py ^
--server_ip 127.0.0.1 ^
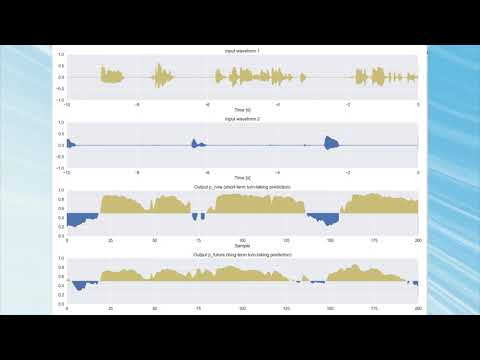
--port_num 50008次のようなGUIが表示されます。

このリポジトリのユーザーは、inputおよびoutputディレクトリにあるサンプルプログラムを参照して、各自の目的に応じた入力および出力プログラムを実装することを想定しています。
16,000 Hzの音声で、フレームサイズは160サンプルです。さらに2人分のデータを同時に送信してください。各サンプルは、リトルエンディアンの8バイト倍精度浮動小数点数で-1.0から+1.0の範囲で表現してください。
送信順序:
各サンプルは16バイトで、最初の8バイトは1人目の音声、後半の8倍とは2人目の音声をそれぞれ表します。
データフレームの構成:
各データフレームのサイズは2,560バイトです。
| バイトオフセット | データ型 | 説明 |
|---|---|---|
| 0 - 7 | Double | 音声データ (1人目) - サンプル 1 |
| 8 - 15 | Double | 音声データ (2人目) - サンプル 1 |
| 16 - 23 | Double | 音声データ (1人目) - サンプル 2 |
| 24 - 31 | Double | 音声データ (2人目) - サンプル 2 |
| ... | ... | ... |
| 2544 - 2551 | Double | 音声データ (1人目) - サンプル 160 |
| 2552 - 2559 | Double | 音声データ (2人目) - サンプル 160 |
具体的な実装例については、input/wav.pyやinput/mic.pyなどのサンプルプログラムを参照してください。
出力データには、入力オーディオデータとVAP出力(p_nowおよびp_future)が含まれます。VAP処理のフレームレートは入力オーディオとは異なることに注意してください。例えば、20HzのVAPモデルでは、VAPにおけるオーディオデータのフレームサイズは800です。また、すべてのデータはリトルエンディアン形式です。
データフレームの構成:
上記の条件下では、各出力データのサイズは12,860バイトとなります。このデータは、各VAPフレームの処理後に送信されます。
| バイトオフセット | データ型 | 説明 |
|---|---|---|
| 0 - 3 | Int | 送信データ長 (12,860) |
| 4 - 11 | Double | Unix タイムスタンプ |
| 12 - 15 | Int | 音声データ (1人目) のデータ長 (800) |
| 16 - 23 | Double | 音声データ (1人目) - サンプル 1 |
| 24 - 31 | Double | 音声データ (1人目) - サンプル 2 |
| ... | ... | ... |
| 6408 - 6415 | Double | 音声データ (1人目) - サンプル 800 |
| 6416 - 6419 | Int | 音声データ (2人目) のデータ長 (800) |
| 6420 - 6427 | Double | 音声データ (2人目) - サンプル 1 |
| 6428 - 6435 | Double | 音声データ (2人目) - サンプル 2 |
| ... | ... | ... |
| 12812 - 12819 | Double | 音声データ (2人目) - サンプル 800 |
| 12820 - 12823 | Int | p_now のデータ長 (2) |
| 12824 - 12831 | Double | p_now (1人目) |
| 12832 - 12839 | Double | p_now (2人目) |
| 12840 - 12843 | Int | p_future のデータ長 (2) |
| 12844 - 12851 | Double | p_future (1人目) |
| 12852 - 12859 | Double | p_future (2人目) |
rvap/vap_main/vap_offline.py を使用して、録音済みの wav ファイルをバッチ処理することもできます。
$ cd rvap/vap_main
$ python vap_offline.py ^
--vap_model '../../asset/vap/vap_state_dict_20hz_jpn.pt' ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--input_wav_left ../../input/wav_sample/jpn_inoue_16k.wav ^
--input_wav_right ../../input/wav_sample/jpn_sumida_16k.wav ^
--filename_output 'output_offline.txt'出力データは output_offline.txt に保存されます。各行には、wavファイルにおけるタイムスタンプ(秒単位)、p_now(2 つの浮動小数点値)と p_future(2 つの浮動小数点値)がカンマで区切られて含まれます。
time_sec,p_now(0=left),p_now(1=right),p_future(0=left),p_future(1=right)
0.07,0.29654383659362793,0.7034487724304199,0.3714706599712372,0.6285228729248047
0.12,0.6943456530570984,0.30564749240875244,0.5658637881278992,0.4341297447681427
0.17,0.8920691013336182,0.10792573541402817,0.7332779169082642,0.26671621203422546
0.22,0.8698683977127075,0.13012604415416718,0.6923539042472839,0.3076401650905609
0.27,0.870344340801239,0.12964950501918793,0.730902373790741,0.26909157633781433
0.32,0.9062888622283936,0.09370578080415726,0.7462385892868042,0.2537555992603302
0.37,0.8965250849723816,0.10346963256597519,0.6949127912521362,0.30508118867874146
0.42,0.9331467151641846,0.06684830039739609,0.7633994221687317,0.2365950644016266
0.47,0.9440065026283264,0.05598851293325424,0.7653886675834656,0.2346058338880539
可視化ツールを使って、オフライン予測結果を音声と共に閲覧することができます。
python output/offline_prediction_visualizer/main.py --left_audio input/wav_sample/jpn_inoue_16k.wav --right_audio input/wav_sample/jpn_sumida_16k.wav --prediction rvap/vap_main/output_offline.txt相槌予測(生成)用にファインチューニングされたモデルもあります。 以下のメインプログラムを使用してください。
$ cd rvap/vap_bc
$ python vap_bc_main.py ^
--vap_model ../../asset/vap_bc/vap-bc_state_dict_erica_20hz_5000msec.pt ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--port_num_in 50007 ^
--port_num_out 50008 ^
--vap_process_rate 20 ^
--context_len_sec 5入出力のフォーマットは同じで、出力のp_nowとp_futureがそれぞれp_bc_reactとp_bc_emoに置き換わります。
p_bc_reactは応答系(「うん」など)、p_bc_emoは感情表出系(「へー」など)の相槌の生起確率を表します。
このモデルは500ミリ秒後の相槌の生起確率を予測するものです。
また、モデルの入力は2チャンネルの音声ですが、1チャンネル目の話者の相槌を予測する、つまり2チャンネル目がユーザの音声に対応することに注意してください。
可視化のサンプルプログラムはoutput/console_bc.pyやoutput/gui_bc.pyです。
このリポジトリには、VAPとCPCのモデルがいくつか含まれています。これらのモデルを使用する場合は、ライセンスに従ってください。
モデルのパラメータには、vap_process_rate と context_len_sec があります。
前者は VAP モデルで処理される1秒あたりのサンプル数、後者はVAPモデルに入力されるコンテキストの長さ(秒)に対応します。
これらはトレーニング中に固定されるため、これらのパラメータを変更したい場合は、モデルを再トレーニングする必要があります。
日本語モデル (旅行代理店対話 (Inaba 2022) の Zoom 会議の対話を用いて学習された日本語モデル)
| 配置場所 | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_jp_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_jp_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_jp_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_jp_5hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_jp_5hz_3000msec.pt |
5 | 3 |
英語モデル (Switchboard corpus を使用してトレーニングされた英語モデル)
| 配置場所 | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_eng_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_eng_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_eng_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_eng_5hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_eng_5hz_3000msec.pt |
5 | 3 |
マルチリンガルモデル ([Switchboard corpus](https://catalog.ldc.upenn.edu/LDC97S 62)、HKUST Mandarin Telephone Speech、Travel agency dialogue (Inaba 2022)を使用してトレーニングされた、英語、中国語、日本語のマルチリンガルモデル)
| 配置場所 | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_tri_ecj_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_tri_ecj_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_tri_ecj_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_tri_ecj_10hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_tri_ecj_10hz_3000msec.pt |
5 | 3 |
日本語相槌モデル (ERICAの傾聴対話データ(WoZ)でファインチューニングされた相槌予測モデル)
| 配置場所 | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap-bc/vap-bc_state_dict_erica_20hz_5000msec.pt |
20 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_20hz_3000msec.pt |
20 | 3 |
asset/vap-bc/vap-bc_state_dict_erica_10hz_5000msec.pt |
10 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_10hz_3000msec.pt |
10 | 3 |
asset/vap-bc/vap-bc_state_dict_erica_5hz_5000msec.pt |
5 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_5hz_3000msec.pt |
5 | 3 |
| 種類 | 配置場所 | 説明 |
|---|---|---|
| オリジナルCPC | asset/cpc/60k_epoch4-d0f474de.pt |
オリジナルCPCモデルは、Libri-lightの60k時間の音声データで学習 |
このリポジトリを利用した成果に関して論文などを発表した場合は、以下の論文を引用してください。
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection
International Workshop on Spoken Dialogue Systems Technology (IWSDS), 2024
https://arxiv.org/abs/2401.04868
@inproceedings{inoue2024iwsds,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection},
booktitle = {International Workshop on Spoken Dialogue Systems Technology (IWSDS)},
year = {2024},
url = {https://arxiv.org/abs/2401.04868},
}
マルチリンガルVAPモデルを使用する場合は、以下の論文も引用してください。
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Multilingual Turn-taking Prediction Using Voice Activity Projection
Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pages 11873-11883, 2024
https://aclanthology.org/2024.lrec-main.1036/
@inproceedings{inoue2024lreccoling,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Multilingual Turn-taking Prediction Using Voice Activity Projection},
booktitle = {Proceedings of the Joint International Conference on Computational Linguistics and Language Resources and Evaluation (LREC-COLING)},
pages = {11873--11883},
year = {2024},
url = {https://aclanthology.org/2024.lrec-main.1036/},
}
このリポジトリ内のソースコードは MITライセンスです。 assetディレクトリにある学習済みモデルは、学術目的のみに使用可能です。
asset/cpc/60k_epoch4-d0f474de.pt に置かれている事前学習済み CPC モデルは、オリジナルの CPC プロジェクトからダウンロードしたものであり、そのライセンスに従ってください。
詳細は、https://github.com/facebookresearch/CPC_audio のオリジナルリポジトリを参照してください。