[SPARK-40175][CORE][SQL][MLLIB][DSTREAM][R] Optimize the performance of keys.zip(values).toMap code pattern
#37876
Conversation
keys.zip(values).toMapkeys.zip(values).toMap code pattern
| def ndcgAt(k: Int): Double = { | ||
| require(k > 0, "ranking position k should be positive") | ||
| rdd.map { case (pred, lab, rel) => | ||
| import org.apache.spark.util.collection.Utils |
There was a problem hiding this comment.
No big deal but why import here?
There was a problem hiding this comment.
This is a mistake, I will fix it.
| while (keyIter.hasNext && valueIter.hasNext) { | ||
| map.put(keyIter.next(), valueIter.next()) | ||
| } | ||
| map |
There was a problem hiding this comment.
Make this immutable ?
I believe the original code would have resulted in an immutable map ?
There was a problem hiding this comment.
this method return a Java Map, how to make it immutable...
There was a problem hiding this comment.
Wrap to Collections.unmodifiableMap?
There was a problem hiding this comment.
u are right, change to return Collections.unmodifiableMap(map)
| import scala.collection.JavaConverters._ | ||
| keys.zip(values).toMap.asJava | ||
| Utils.toJavaMap(keys, values) | ||
| } |
There was a problem hiding this comment.
Do we need this method anymore ? Why not replace with Utils.toJavaMap entirely (in JavaTypeInference) ? Any issues with that ?
There was a problem hiding this comment.
ArrayBasedMapData#toJavaMap is already a never used method, I think we can delete it, but need to confirm whether MiMa check can pass first
EDIT: ArrayBasedMapData#toJavaMap not unused method, it used by JavaTypeInference, sorry for missing what @mridulm said
There was a problem hiding this comment.
let me check this later
There was a problem hiding this comment.
ArrayBasedMapData is not a public API and shouldn't be tracked by mima.
There was a problem hiding this comment.
If
change to
StaticInvoke(
Utils.getClass,
ObjectType(classOf[JMap[_, _]]),
"toJavaMap",
keyData :: valueData :: Nil,
returnNullable = false)The signature to toJavaMap method in collection.Utils need change from
def toJavaMap[K, V](keys: Iterable[K], values: Iterable[V]): java.util.Map[K, V]
to
def toJavaMap[K, V](keys: Array[K], values: Array[V]): java.util.Map[K, V]
Otherwise, relevant tests will fail as due to
16:20:35.587 ERROR org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator: failed to compile: org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 375, Column 50: No applicable constructor/method found for actual parameters "java.lang.Object[], java.lang.Object[]"; candidates are: "public static java.util.Map org.apache.spark.util.collection.Utils.toJavaMap(scala.collection.Iterable, scala.collection.Iterable)"
org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 375, Column 50: No applicable constructor/method found for actual parameters "java.lang.Object[], java.lang.Object[]"; candidates are: "public static java.util.Map org.apache.spark.util.collection.Utils.toJavaMap(scala.collection.Iterable, scala.collection.Iterable)"
If the method signature is def toJavaMap[K, V](keys: Array[K], values: Array[V]): java.util.Map[K, V], it will limit the use scope of this method, so I prefer to retain the ArrayBasedMapData#toJavaMap method
There was a problem hiding this comment.
Is it acceptable to retain this method?
keys.zip(values).toMap code patternkeys.zip(values).toMap code pattern
|
thanks, merging to master! |
…of `keys.zip(values).toMap` code pattern This pr introduce two new `toMap` method to `o.a.spark.util.collection.Utils`, use `while loop manually` style to optimize the performance of `keys.zip(values).toMap` code pattern in Spark. Performance improvement No Pass GitHub Actions Closes apache#37876 from LuciferYang/SPARK-40175. Authored-by: yangjie01 <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
….zipWithIndex.toMap` code pattern ### What changes were proposed in this pull request? Similar as #37876, this pr introduce a new `toMapWithIndex` method to `o.a.spark.util.collection.Utils`, use `while loop manually style` to optimize the performance of `keys.zipWithIndex.toMap` code pattern in Spark. ### Why are the changes needed? Performance improvement ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #37940 from LuciferYang/SPARK-40494. Authored-by: yangjie01 <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
|
I tested it using a real job and the bottleneck seems to be still in |
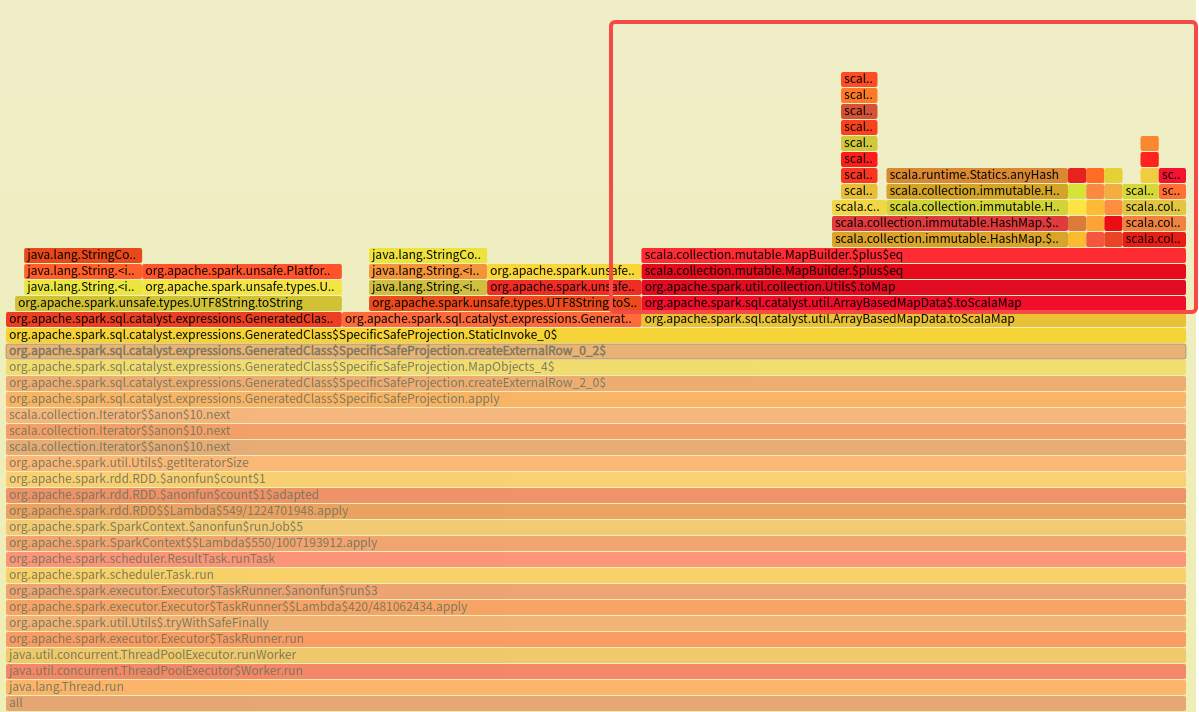
|
my testing code: |
|
|
@caican00 Yes, it was also clear before that when the collection size is greater than 500, there will be no significant performance improvement. In fact, according to the test results from GA, when the collection size is between 100 and 500, the revenue is about 10%, and this is only a partial tuning. I don't think it will significantly improve the overall situation, but this performance is similar to |
Cloud you provide a test case that is easier to test in Spark project? |
|
Yes. EDIT: keys.size > 500 Previous test results |
|
@caican00 I'm not sure whether it would be better change o use |
|
@caican00 Or if you can provide a micro-bench that can be run with GA, I am happy to continue to solve your issue together |
Data collection is hard to build, and i'm sorry that it's hard to provide cases that are easy to test in Spark project |
Hmm... Could you try this one? |
yep. i would change to use |
Okay. I'll tell you the testing result in a soon. |
|
Thanks ~ @caican00 waiting for your feedback :) |
@LuciferYang ~~
|
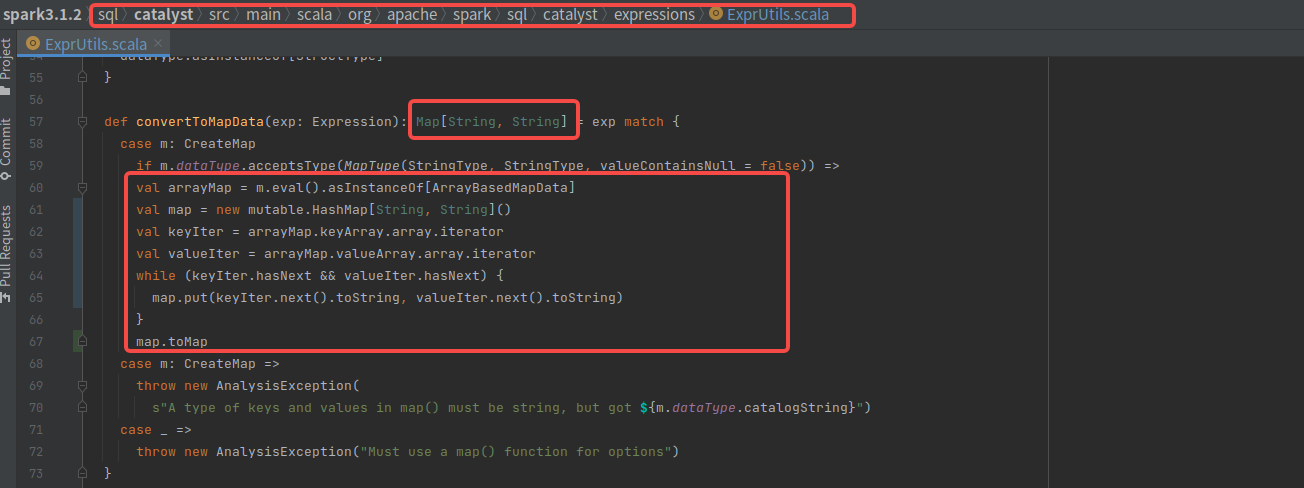

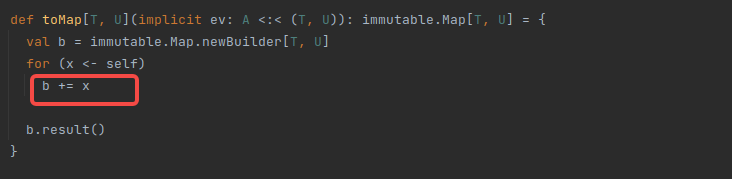
|
using |
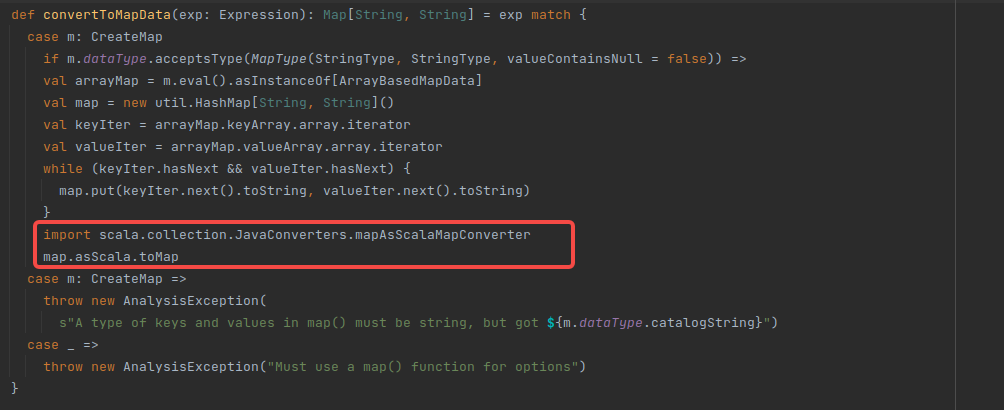
any way to convert |
|
I haven't thought of a better way yet |
Thanks. I'll share it with you if I can think of a better way |
@LuciferYang test code: test result: |
cc @cloud-fan |
|
@caican00 For the performance gap between |
What changes were proposed in this pull request?
This pr introduce two new
toMapmethod too.a.spark.util.collection.Utils, usewhile loop manuallystyle to optimize the performance ofkeys.zip(values).toMapcode pattern in Spark.Why are the changes needed?
Performance improvement
Does this PR introduce any user-facing change?
No
How was this patch tested?
Pass GitHub Actions