[SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map #37609
Conversation
|
gently ping @cloud-fan @srowen |
|
Nice try! Do we have some perf numbers? |
|
Can one of the admins verify this patch? |
@cloud-fan Thanks for your reply. I don't have any perf numbers right now but I'm going to do some performance tests to provide some perf numbers. |
|
breakOut was removed or something in scala 2.13, I think? https://www.scala-lang.org/blog/2017/02/28/collections-rework.html |
Yes, Scala 2.13 already build failed seems as follows:
|
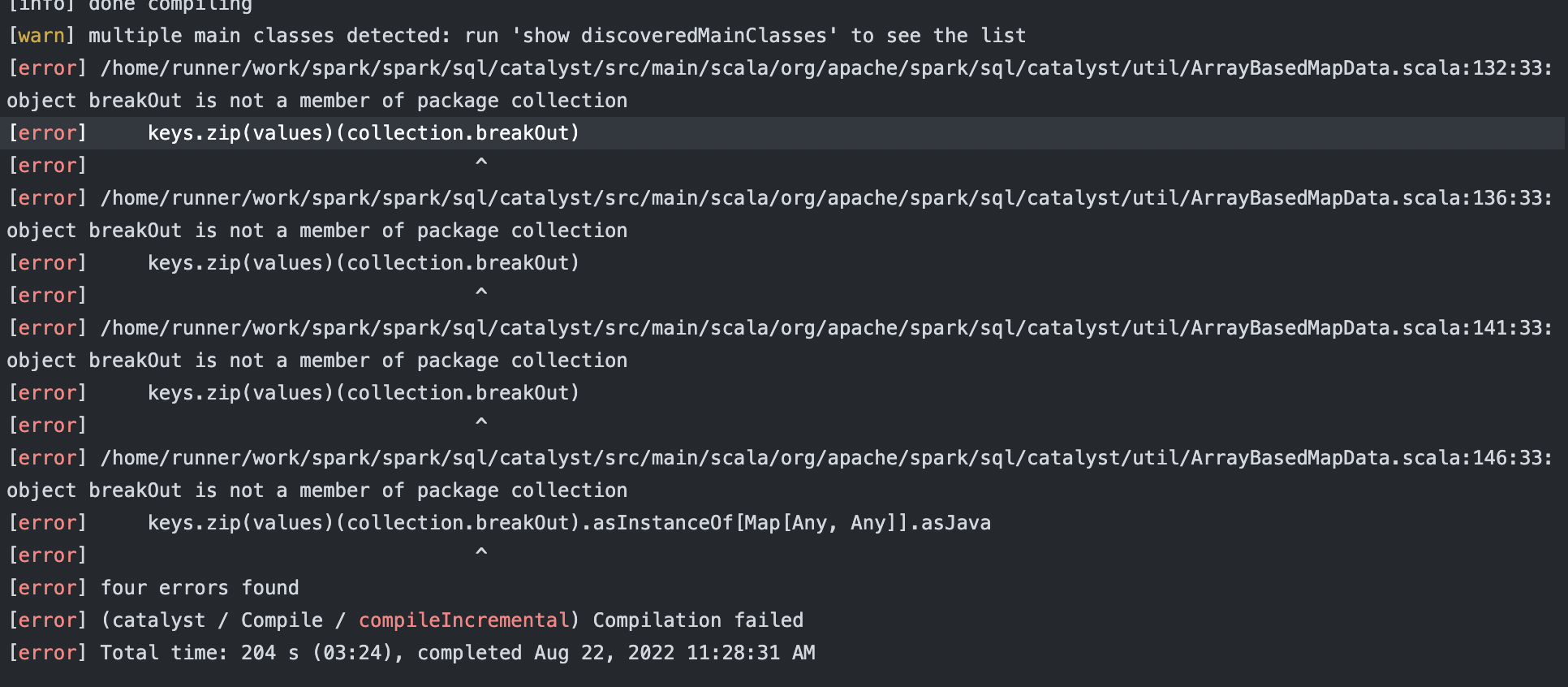
|
The idea is still valid: we can write a while loop manually to build the map, instead of |
|
I think we can test the performance of this api in Scala 2.13 to check if there is targeted optimization in Scala 2.13 |
Checked, Scala 2.13 has the same problem. @caican00 Does |
31 file has |
|
Are you still interested in this pr @caican00 |
@cloud-fan Do you mean like follows? private def zipToMapUseMapBuilder[A, B, K, V](keys: Seq[A], values: Seq[B]): Map[K, V] = {
import scala.collection.immutable
val builder = immutable.Map.newBuilder[K, V]
val keyIter = keys.iterator
val valueIter = values.iterator
while (keyIter.hasNext && valueIter.hasNext) {
builder += (keyIter.next(), valueIter.next()).asInstanceOf[(K, V)]
}
builder.result()
}
private def zipToMapUseMap[A, B, K, V](keys: Seq[A], values: Seq[B]): Map[K, V] = {
var elems: Map[K, V] = Map.empty[K, V]
val keyIter = keys.iterator
val valueIter = values.iterator
while (keyIter.hasNext && valueIter.hasNext) {
elems += (keyIter.next().asInstanceOf[K] -> valueIter.next().asInstanceOf[V])
}
elems
}I write a microben to compare From the results, the performance of |
|
interesting, we need to understand why |
|
I seem to know the reason, |
|
To check |
Add results of input size 150, 200, 300, 400. @cloud-fan , from bench results:
|
|
Great! Seems we can always do |
Yes, there should be many similar case and I think this should be a valuable optimization However, before I doing something, I still want to ask @caican00 , will you continue this optimization? |
|
start this work : #37876 |
|
OK to continue the work here after a rebase? #37876 is merged |
What changes were proposed in this pull request?
Traversable.toMapchanged tocollections.breakOut, that eliminates intermediate tuple collection creation.I optimized it with reference to this pr:#18693
An introduction to
Collections. BreakOutcan be found at Stack Overflow article.Why are the changes needed?
When
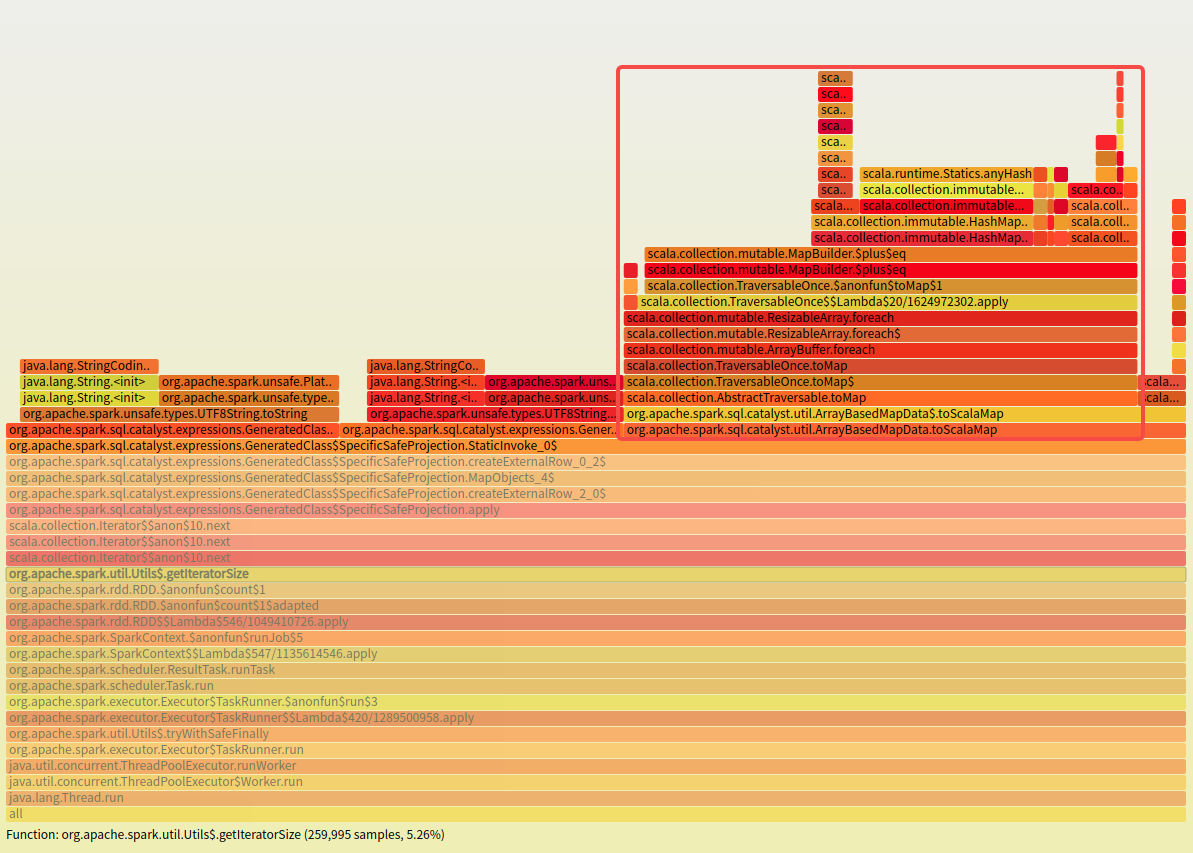

DeserializeToObjectis executed, converting Tuple2 to Scala Map via. ToMaptakes a lot of cpu time.How was this patch tested?
Unit tests run.
No performance tests performed yet.