[SPARK-32492][SQL] Fulfill missing column meta information COLUMN_SIZE /DECIMAL_DIGITS/NUM_PREC_RADIX/ORDINAL_POSITION for thriftserver client tools #29303
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -17,12 +17,10 @@ | |
|
|
||
| package org.apache.spark.sql.hive.thriftserver | ||
|
|
||
| import java.util.regex.Pattern | ||
|
|
||
| import scala.collection.JavaConverters.seqAsJavaListConverter | ||
|
|
||
| import org.apache.hadoop.hive.ql.security.authorization.plugin.{HiveOperationType, HivePrivilegeObject} | ||
| import org.apache.hadoop.hive.ql.security.authorization.plugin.HivePrivilegeObject.HivePrivilegeObjectType | ||
| import org.apache.hive.service.cli._ | ||
|
|
@@ -34,7 +32,7 @@ import org.apache.spark.sql.SQLContext | |
| import org.apache.spark.sql.catalyst.TableIdentifier | ||
| import org.apache.spark.sql.catalyst.catalog.SessionCatalog | ||
| import org.apache.spark.sql.hive.thriftserver.ThriftserverShimUtils.toJavaSQLType | ||
| import org.apache.spark.sql.types._ | ||
|
|
||
| /** | ||
| * Spark's own SparkGetColumnsOperation | ||
|
|
@@ -126,12 +124,52 @@ private[hive] class SparkGetColumnsOperation( | |
| HiveThriftServer2.eventManager.onStatementFinish(statementId) | ||
| } | ||
|
|
||
| /** | ||
| * For boolean, numeric and datetime types, it returns the default size of its catalyst type | ||
| * For struct type, when its elements are fixed-size, the summation of all element sizes will be | ||
| * returned. | ||
| * For array, map, string, and binaries, the column size is variable, return null as unknown. | ||
| */ | ||
| private def getColumnSize(typ: DataType): Option[Int] = typ match { | ||
| case dt @ (BooleanType | _: NumericType | DateType | TimestampType) => Some(dt.defaultSize) | ||
| case StructType(fields) => | ||
| val sizeArr = fields.map(f => getColumnSize(f.dataType)) | ||
| if (sizeArr.contains(None)) { | ||
| None | ||
| } else { | ||
| Some(sizeArr.map(_.get).sum) | ||
| } | ||
| case other => None | ||
| } | ||
|
|
||
| /** | ||
| * The number of fractional digits for this type. | ||
| * Null is returned for data types where this is not applicable. | ||
| * For boolean and integrals, the decimal digits is 0 | ||
| * For floating types, we follow the IEEE Standard for Floating-Point Arithmetic (IEEE 754) | ||
| * For timestamp values, we support microseconds | ||
| * For decimals, it returns the scale | ||
| */ | ||
| private def getDecimalDigits(typ: DataType) = typ match { | ||
| case BooleanType | _: IntegerType => Some(0) | ||
| case FloatType => Some(7) | ||
| case DoubleType => Some(15) | ||
|
Contributor
There was a problem hiding this comment. how do we pick these numbers?
Member
Author
There was a problem hiding this comment. They are from hive's
Member
Author
There was a problem hiding this comment. the result is
Member
Author
There was a problem hiding this comment. It seems to follow
Contributor
There was a problem hiding this comment. Can we add a code comment to explain it? |
||
| case d: DecimalType => Some(d.scale) | ||
| case TimestampType => Some(6) | ||
| case _ => None | ||
| } | ||
|
|
||
| private def getNumPrecRadix(typ: DataType): Option[Int] = typ match { | ||
| case _: NumericType => Some(10) | ||
| case _ => None | ||
| } | ||
|
|
||
| private def addToRowSet( | ||
| columnPattern: Pattern, | ||
| dbName: String, | ||
| tableName: String, | ||
| schema: StructType): Unit = { | ||
| schema.zipWithIndex.foreach { case (column, pos) => | ||
| if (columnPattern != null && !columnPattern.matcher(column.name).matches()) { | ||
| } else { | ||
| val rowData = Array[AnyRef]( | ||
|
|
@@ -141,17 +179,17 @@ private[hive] class SparkGetColumnsOperation( | |
| column.name, // COLUMN_NAME | ||
| toJavaSQLType(column.dataType.sql).asInstanceOf[AnyRef], // DATA_TYPE | ||
| column.dataType.sql, // TYPE_NAME | ||
| getColumnSize(column.dataType).map(_.asInstanceOf[AnyRef]).orNull, // COLUMN_SIZE | ||
yaooqinn marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| null, // BUFFER_LENGTH, unused | ||
| getDecimalDigits(column.dataType).map(_.asInstanceOf[AnyRef]).orNull, // DECIMAL_DIGITS | ||
| getNumPrecRadix(column.dataType).map(_.asInstanceOf[AnyRef]).orNull, // NUM_PREC_RADIX | ||
| (if (column.nullable) 1 else 0).asInstanceOf[AnyRef], // NULLABLE | ||
| column.getComment().getOrElse(""), // REMARKS | ||
| null, // COLUMN_DEF | ||
| null, // SQL_DATA_TYPE | ||
| null, // SQL_DATETIME_SUB | ||
| null, // CHAR_OCTET_LENGTH | ||
| pos.asInstanceOf[AnyRef], // ORDINAL_POSITION | ||
| "YES", // IS_NULLABLE | ||
|
Contributor
There was a problem hiding this comment. Should this respect
Member
Author
There was a problem hiding this comment. IS_NULLABLE is related to PK, "YES" here is more specific as we don't have such thing implemented |
||
| null, // SCOPE_CATALOG | ||
| null, // SCOPE_SCHEMA | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -19,9 +19,12 @@ package org.apache.spark.sql.hive.thriftserver | |
|
|
||
| import java.sql.SQLException | ||
|
|
||
| import scala.collection.JavaConverters._ | ||
|
|
||
| import org.apache.hive.service.cli.HiveSQLException | ||
|
|
||
| import org.apache.spark.sql.hive.HiveUtils | ||
| import org.apache.spark.sql.types._ | ||
|
|
||
| trait ThriftServerWithSparkContextSuite extends SharedThriftServer { | ||
|
|
||
|
|
@@ -101,6 +104,135 @@ trait ThriftServerWithSparkContextSuite extends SharedThriftServer { | |
| } | ||
| } | ||
| } | ||
|
|
||
| test("check results from get columns operation from thrift server") { | ||
| val schemaName = "default" | ||
| val tableName = "spark_get_col_operation" | ||
| val schema = new StructType() | ||
| .add("c0", "boolean", nullable = false, "0") | ||
| .add("c1", "tinyint", nullable = true, "1") | ||
| .add("c2", "smallint", nullable = false, "2") | ||
| .add("c3", "int", nullable = true, "3") | ||
| .add("c4", "long", nullable = false, "4") | ||
| .add("c5", "float", nullable = true, "5") | ||
| .add("c6", "double", nullable = false, "6") | ||
| .add("c7", "decimal(38, 20)", nullable = true, "7") | ||
| .add("c8", "decimal(10, 2)", nullable = false, "8") | ||
| .add("c9", "string", nullable = true, "9") | ||
| .add("c10", "array<long>", nullable = false, "10") | ||
| .add("c11", "array<string>", nullable = true, "11") | ||
| .add("c12", "map<smallint, tinyint>", nullable = false, "12") | ||
| .add("c13", "date", nullable = true, "13") | ||
| .add("c14", "timestamp", nullable = false, "14") | ||
| .add("c15", "struct<X: bigint,Y: double>", nullable = true, "15") | ||
| .add("c16", "binary", nullable = false, "16") | ||
|
|
||
| val ddl = | ||
| s""" | ||
| |CREATE TABLE $schemaName.$tableName ( | ||
| | ${schema.toDDL} | ||
| |) | ||
| |using parquet""".stripMargin | ||
|
|
||
| withCLIServiceClient { client => | ||
| val sessionHandle = client.openSession(user, "") | ||
| val confOverlay = new java.util.HashMap[java.lang.String, java.lang.String] | ||
| val opHandle = client.executeStatement(sessionHandle, ddl, confOverlay) | ||
| var status = client.getOperationStatus(opHandle) | ||
| while (!status.getState.isTerminal) { | ||
| Thread.sleep(10) | ||
| status = client.getOperationStatus(opHandle) | ||
| } | ||
| val getCol = client.getColumns(sessionHandle, "", schemaName, tableName, null) | ||
|
Member
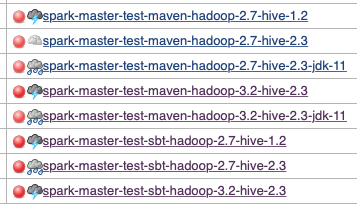
There was a problem hiding this comment. Hi, @yaooqinn and @cloud-fan . I'm not sure but this new test case seems to break all Jenkins From the screenshot, please ignore SBT failures.
Member
There was a problem hiding this comment. Let's revert if it takes a while to fix.
Member
Author
There was a problem hiding this comment. Looks like something related to another version of Hive which belong to another job(maybe failed) not being cleaned up.
Contributor
There was a problem hiding this comment. Not all maven builds are broken: Let's wait a little bit and see if it's an env issue.
Member
There was a problem hiding this comment. Ya. It seems that Hive 2.3 is affected. And, JDK11 maven seems not running those test suite.
Member
There was a problem hiding this comment. BTW, this is not a flaky failure. This broke some profiles consistently.
Member
There was a problem hiding this comment. BTW, it's up to you, @cloud-fan . I'll not revert this by myself since PRBuilder is still working. |
||
| val rowSet = client.fetchResults(getCol) | ||
| val columns = rowSet.toTRowSet.getColumns | ||
|
|
||
| val catalogs = columns.get(0).getStringVal.getValues.asScala | ||
| assert(catalogs.forall(_.isEmpty), "catalog name mismatches") | ||
|
|
||
| val schemas = columns.get(1).getStringVal.getValues.asScala | ||
| assert(schemas.forall(_ == schemaName), "schema name mismatches") | ||
|
|
||
| val tableNames = columns.get(2).getStringVal.getValues.asScala | ||
| assert(tableNames.forall(_ == tableName), "table name mismatches") | ||
|
|
||
| val columnNames = columns.get(3).getStringVal.getValues.asScala | ||
| columnNames.zipWithIndex.foreach { | ||
| case (v, i) => assert(v === "c" + i, "column name mismatches") | ||
| } | ||
|
|
||
| val javaTypes = columns.get(4).getI32Val.getValues | ||
| import java.sql.Types._ | ||
| assert(javaTypes.get(0).intValue() === BOOLEAN) | ||
| assert(javaTypes.get(1).intValue() === TINYINT) | ||
| assert(javaTypes.get(2).intValue() === SMALLINT) | ||
| assert(javaTypes.get(3).intValue() === INTEGER) | ||
| assert(javaTypes.get(4).intValue() === BIGINT) | ||
| assert(javaTypes.get(5).intValue() === FLOAT) | ||
| assert(javaTypes.get(6).intValue() === DOUBLE) | ||
| assert(javaTypes.get(7).intValue() === DECIMAL) | ||
| assert(javaTypes.get(8).intValue() === DECIMAL) | ||
| assert(javaTypes.get(9).intValue() === VARCHAR) | ||
| assert(javaTypes.get(10).intValue() === ARRAY) | ||
| assert(javaTypes.get(11).intValue() === ARRAY) | ||
| assert(javaTypes.get(12).intValue() === JAVA_OBJECT) | ||
| assert(javaTypes.get(13).intValue() === DATE) | ||
| assert(javaTypes.get(14).intValue() === TIMESTAMP) | ||
| assert(javaTypes.get(15).intValue() === STRUCT) | ||
| assert(javaTypes.get(16).intValue() === BINARY) | ||
|
|
||
| val typeNames = columns.get(5).getStringVal.getValues.asScala | ||
| typeNames.zip(schema).foreach { case (tName, f) => | ||
| assert(tName === f.dataType.sql) | ||
| } | ||
|
|
||
| val colSize = columns.get(6).getI32Val.getValues.asScala | ||
|
|
||
| colSize.zip(schema).foreach { case (size, f) => | ||
| f.dataType match { | ||
| case StringType | BinaryType | _: ArrayType | _: MapType => assert(size === 0) | ||
| case o => assert(size === o.defaultSize) | ||
| } | ||
| } | ||
|
|
||
| val decimalDigits = columns.get(8).getI32Val.getValues.asScala | ||
| decimalDigits.zip(schema).foreach { case (dd, f) => | ||
| f.dataType match { | ||
| case BooleanType | _: IntegerType => assert(dd === 0) | ||
| case d: DecimalType => assert(dd === d.scale) | ||
| case FloatType => assert(dd === 7) | ||
| case DoubleType => assert(dd === 15) | ||
| case TimestampType => assert(dd === 6) | ||
| case _ => assert(dd === 0) // nulls | ||
| } | ||
| } | ||
|
|
||
| val radixes = columns.get(9).getI32Val.getValues.asScala | ||
| radixes.zip(schema).foreach { case (radix, f) => | ||
| f.dataType match { | ||
| case _: NumericType => assert(radix === 10) | ||
| case _ => assert(radix === 0) // nulls | ||
| } | ||
| } | ||
|
|
||
| val nullables = columns.get(10).getI32Val.getValues.asScala | ||
| assert(nullables.forall(_ === 1)) | ||
|
|
||
| val comments = columns.get(11).getStringVal.getValues.asScala | ||
| comments.zip(schema).foreach { case (c, f) => assert(c === f.getComment().get) } | ||
|
|
||
| val positions = columns.get(16).getI32Val.getValues.asScala | ||
| positions.zipWithIndex.foreach { case (pos, idx) => | ||
| assert(pos === idx, "the client columns disorder") | ||
| } | ||
|
|
||
| val isNullables = columns.get(17).getStringVal.getValues.asScala | ||
| assert(isNullables.forall(_ === "YES")) | ||
|
|
||
| val autoIncs = columns.get(22).getStringVal.getValues.asScala | ||
| assert(autoIncs.forall(_ === "NO")) | ||
| } | ||
| } | ||
| } | ||
|
|
||
|
|
||
|
|
||

There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Hive returns the almost same values for column size?
https://github.com/apache/hive/blob/3e5e99eae154ceb8f9aa4e4ec71e6b05310e98e4/service/src/java/org/apache/hive/service/cli/operation/GetColumnsOperation.java#L187-L211
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Hive does not return same result for each type