[SPARK-32138] Drop Python 2.7, 3.4 and 3.5 #28957
Conversation
|
I'm supporting @HyukjinKwon 's idea, but cc @gatorsmile and @marmbrus since they wanted to keep the deprecated features forever if there is no big burden. We had better get confirmations from them. |
|
Also, cc @rxin |
|
Test build #124645 has finished for PR 28957 at commit
|
There was a problem hiding this comment.
I'm in favor of dropping Python <3.6 as it would simplify the code. This also allows us to use type hinting to make pyspark easier too use.
I think, we need to update the classifiers as well:
Lines 214 to 226 in 3efa521
Also, I would recommend setting python_requires to >=3.6 so people get a notification if they install it using <=3.5.
|
Thanks for working on this! @Fokko do we have a rough idea what % of general users are running Python 3.6+? |
|
My pleasure @holdenk I ran a query against the public dataset of Google. They have a dataset that contains all the public pypi downloads: SELECT
EXTRACT(YEAR FROM timestamp) AS year,
EXTRACT(MONTH FROM timestamp) AS month,
SAFE.SUBSTR(details.python, 0, 3) AS python_version,
COUNT(*) AS num_downloads
FROM `the-psf.pypi.downloads*`
WHERE file.project = 'pyspark'
AND SAFE.SUBSTR(details.python, 0, 3) IS NOT NULL
GROUP BY
EXTRACT(YEAR FROM timestamp),
EXTRACT(MONTH FROM timestamp),
SAFE.SUBSTR(details.python, 0, 3)This gives us the following per month: We can see that the majority uses 3.7 and 3.6. However, there is still a share of 3.5 and 2.7. If we look at the proportional share of people who'm using a compatible version: SELECT
EXTRACT(YEAR FROM timestamp) AS year,
EXTRACT(MONTH FROM timestamp) AS month,
if(SAFE.SUBSTR(details.python, 0, 3) >= '3.6', 'ok', 'not_ok') as OK,
COUNT(*) AS num_downloads
FROM `the-psf.pypi.downloads*`
WHERE file.project = 'pyspark'
AND SAFE.SUBSTR(details.python, 0, 3) IS NOT NULL
GROUP BY
EXTRACT(YEAR FROM timestamp),
EXTRACT(MONTH FROM timestamp),
if(SAFE.SUBSTR(details.python, 0, 3) >= '3.6', 'ok', 'not_ok')Then the majority is ok: The next question would be if Python <3.6 users are on 3.0 or on 2.x. My guess would be the latter, so we're (mostly) safe deprecating the old versions of Python. |
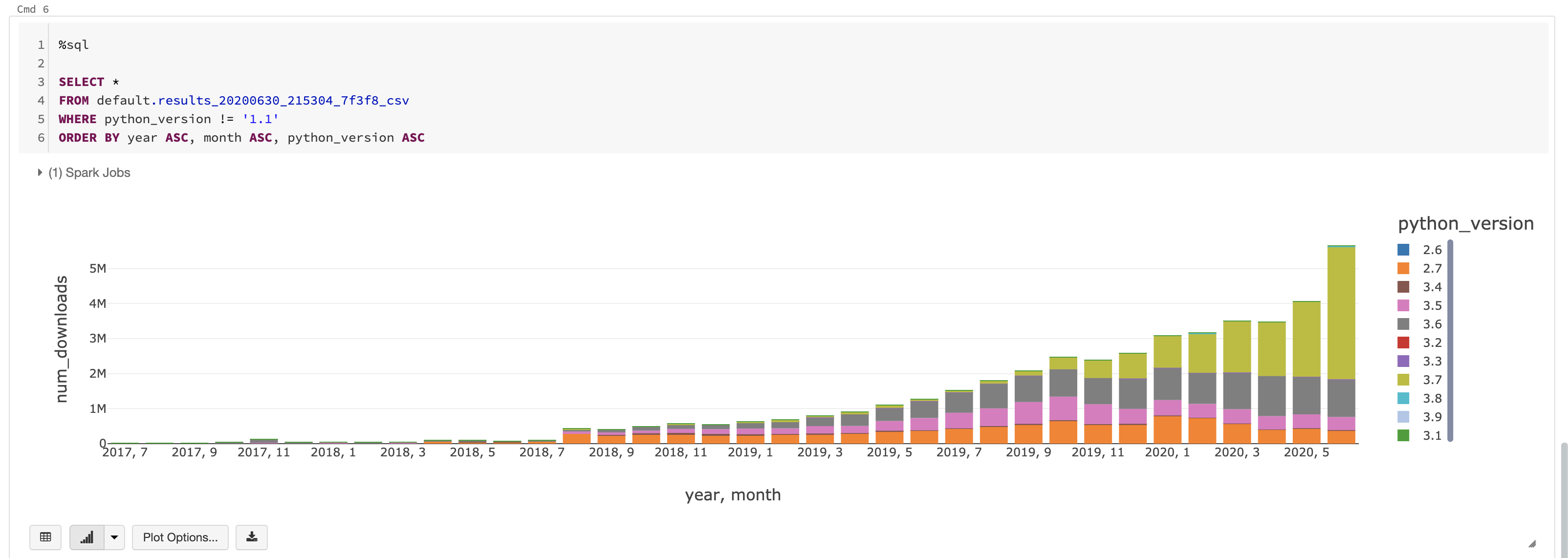
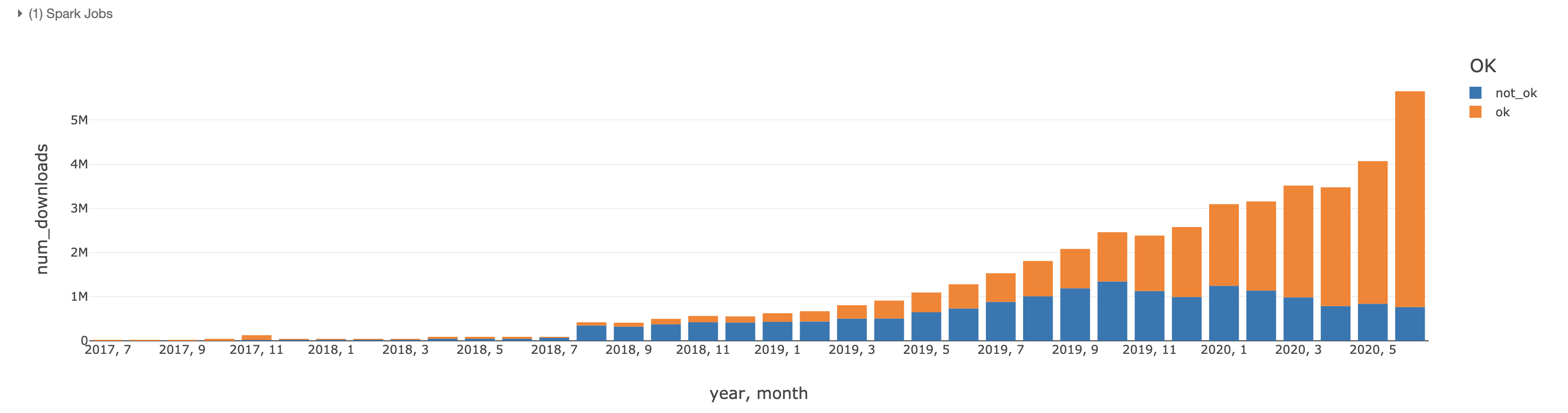
|
Thanks @Fokko for the investigation here. |
|
Wow, nice investigation, @Fokko ! Thanks. |
|
Test build #124750 has finished for PR 28957 at commit
|
|
@HyukjinKwon . Did you get a chance to get a feedback from @marmbrus and @gatorsmile ? |
|
Nope, I am waiting for more feedback - I usually share anything up in OSS side. I was just assuming it's good enough to go given @Fokko's investigation at #28957 (comment). |
|
I will send an email to dev list to confirm. I think that's faster. |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
I'll merge GitHub actions one first, and fix the conflicts here. I need https://github.com/apache/spark/pull/29057/files#diff-0590ca852e0e565bc489272aee36167fR729 change, and remove Python 2 specific codes at #29057 here. |
|
I merged GitHub Action PR. Please rebase this to the master. Thanks, @HyukjinKwon . |
|
Sure, thanks @dongjoon-hyun |
 BryanCutler
left a comment
BryanCutler
left a comment
There was a problem hiding this comment.
LGTM, lot's of cleanup here thanks for doing it. This is great!
python/pyspark/sql/types.py
Outdated
There was a problem hiding this comment.
Yup, this looks good. I noticed you already fixed up the test cases that if affects, so that's great!
| arrs_names = [(pa.array([], type=field.type), field.name) for field in t] | ||
| # Assign result columns by schema name if user labeled with strings | ||
| elif self._assign_cols_by_name and any(isinstance(name, basestring) | ||
| elif self._assign_cols_by_name and any(isinstance(name, str) |
There was a problem hiding this comment.
We might want to think about removing this as an option as a followup. It was mostly added because dataframe constructed with python < 3.6 could not guarantee the order of columns, but now it should match the given schema.
There was a problem hiding this comment.
Ah, right. sounds good!
There was a problem hiding this comment.
and yes, maybe it should better be in a separate PR.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
retest this please |
|
Test build #125774 has finished for PR 28957 at commit
|
|
retest this please |
|
Test build #125786 has finished for PR 28957 at commit
|
|
I am merging it to master. Thank you guys for reviewing this. |
|
Merged to master. |
|
Thanks for doing this, awesome work :) |
|
Cool stuff, thanks for the work @HyukjinKwon |
|
Great! Thank you always for leading PySpark part (in addition to all the other Spark module), @HyukjinKwon ! |
…on 2 and work with Python 3 ### What changes were proposed in this pull request? This PR proposes to make the scripts working by: - Recovering credit related scripts that were broken from #29563 `raw_input` does not exist in `releaseutils` but only in Python 2 - Dropping Python 2 in these scripts because we dropped Python 2 in #28957 - Making these scripts workin with Python 3 ### Why are the changes needed? To unblock the release. ### Does this PR introduce _any_ user-facing change? No, it's dev-only change. ### How was this patch tested? I manually tested against Spark 3.1.1 RC3. Closes #31660 from HyukjinKwon/SPARK-34551. Authored-by: HyukjinKwon <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> (cherry picked from commit 5b92531) Signed-off-by: HyukjinKwon <[email protected]>
…on 2 and work with Python 3 ### What changes were proposed in this pull request? This PR proposes to make the scripts working by: - Recovering credit related scripts that were broken from #29563 `raw_input` does not exist in `releaseutils` but only in Python 2 - Dropping Python 2 in these scripts because we dropped Python 2 in #28957 - Making these scripts workin with Python 3 ### Why are the changes needed? To unblock the release. ### Does this PR introduce _any_ user-facing change? No, it's dev-only change. ### How was this patch tested? I manually tested against Spark 3.1.1 RC3. Closes #31660 from HyukjinKwon/SPARK-34551. Authored-by: HyukjinKwon <[email protected]> Signed-off-by: HyukjinKwon <[email protected]>
What changes were proposed in this pull request?
This PR aims to drop Python 2.7, 3.4 and 3.5.
Roughly speaking, it removes all the widely known Python 2 compatibility workarounds such as
sys.versioncomparison,__future__. Also, it removes the Python 2 dedicated codes such asArrayConstructorin Spark.Why are the changes needed?
Does this PR introduce any user-facing change?
Yes, users cannot use Python 2.7, 3.4 and 3.5 in the upcoming Spark version.
How was this patch tested?
Manually tested and also tested in Jenkins.