[SPARK-32083][SQL] Apply CoalesceShufflePartitions when input RDD has 0 partitions with AQE #28954
Conversation
… 0 partitions with AQE
| } | ||
| } | ||
|
|
||
| if (validMetrics.isEmpty) { |
There was a problem hiding this comment.
if a query stage has multiple leaf shuffles, and only one of them has 0-partition input RDD. What shall we do?
There was a problem hiding this comment.
I think it's like coalescing one less shuffles and handled by the nonEmpty codes.
| } | ||
|
|
||
| if (validMetrics.isEmpty) { | ||
| updatePlan(Nil) |
There was a problem hiding this comment.
Can you add a comment for the case of 0-partition?
|
Test build #124648 has finished for PR 28954 at commit
|
|
After more thoughts, maybe a better way is to add a new rule in This is not really "coalesce partitions" and we'd better not do it in |
|
@manuzhang I run the The related code is : |

|
@JkSelf Try changing |
|
@manuzhang It seems still only one stage and no unnecessary task for empty partitions. related code: |

|
@JkSelf Could you check the |
|
@manuzhang Here is the |
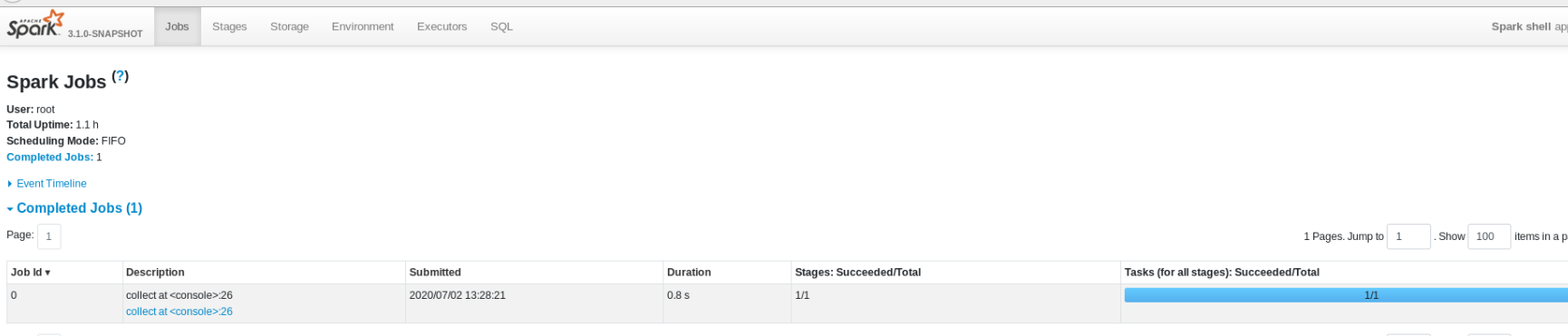
|
When input RDD has 0 partitions, even |
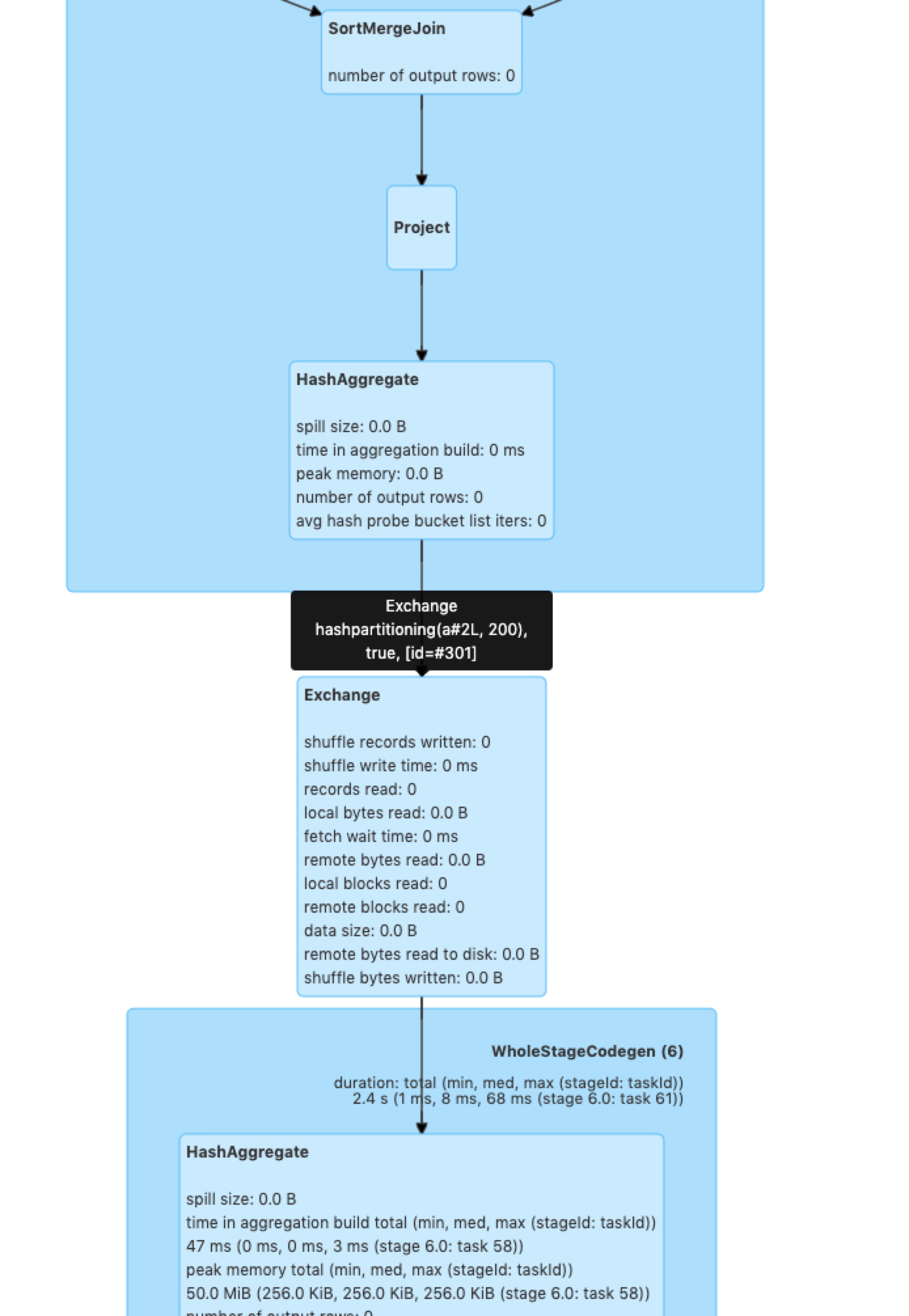
|
@JkSelf val df1 = spark.range(0, 10, 1, 1).withColumn("a", 'id)
val df2 = spark.range(0, 10, 1, 1).withColumn("b", 'id)
val testDf = df1.where('a > 10).join(df2.where('b > 10), "id").groupBy('a).count()
testDf.collect()Compare the execution plan with above. |
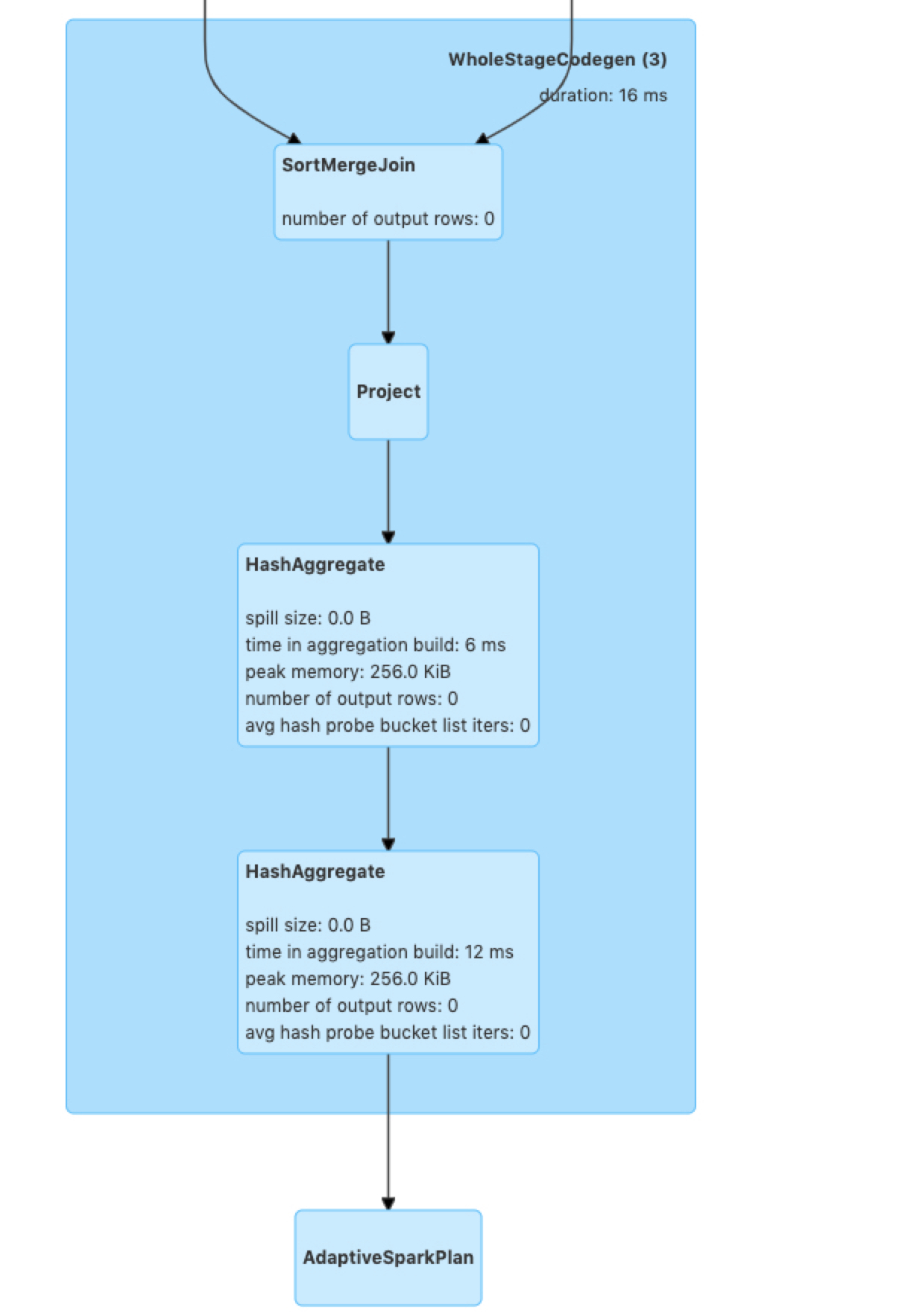
|
@cloud-fan I find an issue with updating metrics if I convert a The missing key is from the metrics of a |
What changes were proposed in this pull request?
As suggested by @cloud-fan in #28916 (comment), apply
CoalesceShufflePartitionswith partitionSpecs ofNilwhenShuffleQueryStageExec#mapStatsis None.Why are the changes needed?
For SQL like
when all ids of t1 are smaller than 10. Many unnecessary tasks are launched for the final shuffle stage because
CoalesceShufflePartitionsis skipped when input RDD has 0 partitions.Before
After
Does this PR introduce any user-facing change?
No
How was this patch tested?
Updated tests.