[SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE #28916
Conversation
| def createPartitionSpec(last: Boolean = false): Unit = { | ||
| // Skip empty inputs, as it is a waste to launch an empty task | ||
| // unless all inputs are empty | ||
| if (coalescedSize > 0 || (last && partitionSpecs.isEmpty)) { |
There was a problem hiding this comment.
so you want to create at least one partition? This doesn't match the PR description.
There was a problem hiding this comment.
Yes, one partition if all partitions are empty. This creates one partition spec at last when no partition specs have been created.
|
Test build #124473 has finished for PR 28916 at commit
|
Why no partition would cause this? |
|
IIUC, stages after coalescing will be submitted in a separate job with default number of partitions when the input is 0 |
|
Retest this please. |
|
Test build #124588 has finished for PR 28916 at commit
|
|
Retest this please |
|
Same question. When |
|
Test build #124607 has finished for PR 28916 at commit
|
|
It's because |
|
Ideally we should launch no task for empty partitions. Launching one task is still not the best solution. |
When The shuffle is changed by AQE and |
|
@manuzhang can you check the Spark web UI and make sure AQE does launch tasks for empty partitions? |
|
@cloud-fan Yes, also from the UT log before this change (I enabled the lineage log) |
|
@manuzhang can you check the web UI as well? |
|
@cloud-fan here it is |
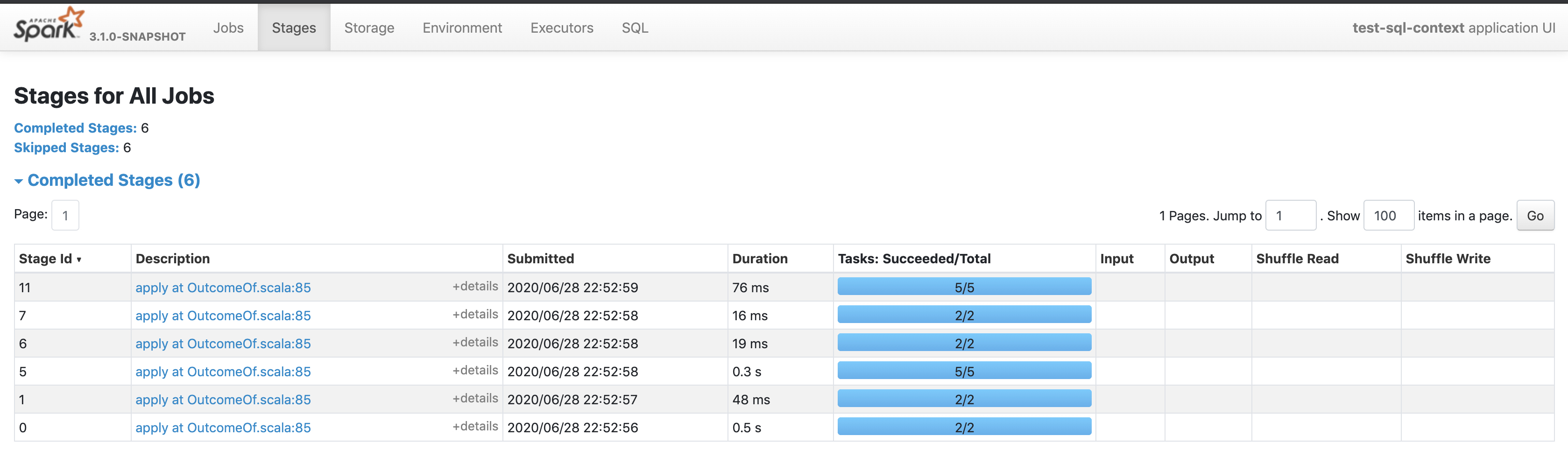
|
I checked the related code and came up with the same conclusion as @viirya . Can you elaborate more about how this happens? |
|
The above log is from this UT. df1.where('a > 10).join(df2.where('b > 10), "id").groupBy('a).count()I was not saying that tasks were launched for the stage of coalesced empty partition but the stage consuming the output of the empty partition, which I believe is the execution of |
|
@viirya @cloud-fan |
|
I think the key problem is we skip |
|
Thanks for pointing that out. Let me try with a new PR. |
|
@cloud-fan @viirya Please help review the new PR #28954. |
### What changes were proposed in this pull request? This PR updates the AQE framework to at least return one partition during coalescing. This PR also updates `ShuffleExchangeExec.canChangeNumPartitions` to not coalesce for `SinglePartition`. ### Why are the changes needed? It's a bit risky to return 0 partitions, as sometimes it's different from empty data. For example, global aggregate will return one result row even if the input table is empty. If there is 0 partition, no task will be run and no result will be returned. More specifically, the global aggregate requires `AllTuples` and we can't coalesce to 0 partitions. This is not a real bug for now. The global aggregate will be planned as partial and final physical agg nodes. The partial agg will return at least one row, so that the shuffle still have data. But it's better to fix this issue to avoid potential bugs in the future. According to #28916, this change also fix some perf problems. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated test. Closes #29307 from cloud-fan/aqe. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
This PR updates the AQE framework to at least return one partition during coalescing. This PR also updates `ShuffleExchangeExec.canChangeNumPartitions` to not coalesce for `SinglePartition`. It's a bit risky to return 0 partitions, as sometimes it's different from empty data. For example, global aggregate will return one result row even if the input table is empty. If there is 0 partition, no task will be run and no result will be returned. More specifically, the global aggregate requires `AllTuples` and we can't coalesce to 0 partitions. This is not a real bug for now. The global aggregate will be planned as partial and final physical agg nodes. The partial agg will return at least one row, so that the shuffle still have data. But it's better to fix this issue to avoid potential bugs in the future. According to apache#28916, this change also fix some perf problems. no updated test. Closes apache#29307 from cloud-fan/aqe. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? This PR updates the AQE framework to at least return one partition during coalescing. This PR also updates `ShuffleExchangeExec.canChangeNumPartitions` to not coalesce for `SinglePartition`. ### Why are the changes needed? It's a bit risky to return 0 partitions, as sometimes it's different from empty data. For example, global aggregate will return one result row even if the input table is empty. If there is 0 partition, no task will be run and no result will be returned. More specifically, the global aggregate requires `AllTuples` and we can't coalesce to 0 partitions. This is not a real bug for now. The global aggregate will be planned as partial and final physical agg nodes. The partial agg will return at least one row, so that the shuffle still have data. But it's better to fix this issue to avoid potential bugs in the future. According to apache/spark#28916, this change also fix some perf problems. ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? updated test. Closes #29307 from cloud-fan/aqe. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
This PR updates the AQE framework to at least return one partition during coalescing. This PR also updates `ShuffleExchangeExec.canChangeNumPartitions` to not coalesce for `SinglePartition`. It's a bit risky to return 0 partitions, as sometimes it's different from empty data. For example, global aggregate will return one result row even if the input table is empty. If there is 0 partition, no task will be run and no result will be returned. More specifically, the global aggregate requires `AllTuples` and we can't coalesce to 0 partitions. This is not a real bug for now. The global aggregate will be planned as partial and final physical agg nodes. The partial agg will return at least one row, so that the shuffle still have data. But it's better to fix this issue to avoid potential bugs in the future. According to apache#28916, this change also fix some perf problems. no updated test. Closes apache#29307 from cloud-fan/aqe. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
What changes were proposed in this pull request?
This PR creates one partition spec in
ShufflePartitionsUtilif all inputs are empty, which avoids launching as many unnecessary tasks as the number of shuffle partitions for following stages.Why are the changes needed?
For SQL like
when all ids of t1 are smaller than 10. No tasks are launched for join since empty input is coalesced to 0 partition. However, many unnecessary tasks could be launched for the following aggregate execution. Hence, I'm proposing coalescing to one partition when all partitions are empty.
Before
After
Does this PR introduce any user-facing change?
No.
How was this patch tested?
updated tests.