[SPARK-29600][SQL] ArrayContains function may return incorrect result for DecimalType #26811
Conversation
| case (_, NullType) => Seq.empty | ||
| case (ArrayType(e1, hasNull), e2) => | ||
| TypeCoercion.findTightestCommonType(e1, e2) match { | ||
| TypeCoercion.findWiderTypeForTwo(e1, e2) match { |
There was a problem hiding this comment.
This kind of things need a justification and migration guide update with tests. Which JIRA caused this issue?
There was a problem hiding this comment.
PR #22408 which is to prevent implicit downcasting of right expression.
It doesn't handle the case of decimal type upcasting.
There was a problem hiding this comment.
I will update migration guide.
| assert(e2.message.contains(errorMsg2)) | ||
| checkAnswer( | ||
| OneRowRelation().selectExpr("array_contains(array(1), 'foo')"), | ||
| Seq(Row(false)) |
There was a problem hiding this comment.
After PR, for queries like SELECT array_contains(array(1), 'xyz'); left expression will be upcasted to array<string>. So instead of throwing an exception, it will result false.
|
Hm, I can't tell if the new behavior is intentional or an unintended side effect. WDYT @dilipbiswal @cloud-fan @maropu ? |
|
I think this kind of implicit type casts can easily cause unexpected output in complicated queries... Even in pgsql, an array contain operator If users want to process this kind of queries, using explicit casts looks better. |
|
It sounds like we want an error in this case, and it currently generates an error? then I don't think we want to undo the previous change a bit like this. |
|
@srowen Yea, I think so. cc: @gatorsmile |
|
ok to test |
|
@amanomer do you know which PR causes the compatibility issue? We need to see if it's intentional or not. If it's intentional, there should be a migration guide. |
|
Test build #115143 has finished for PR 26811 at commit
|
I think this PR #22408 which uses |
I don't see this case(decimal types with different precision) in migration guide. Snap from migration guide is attached |
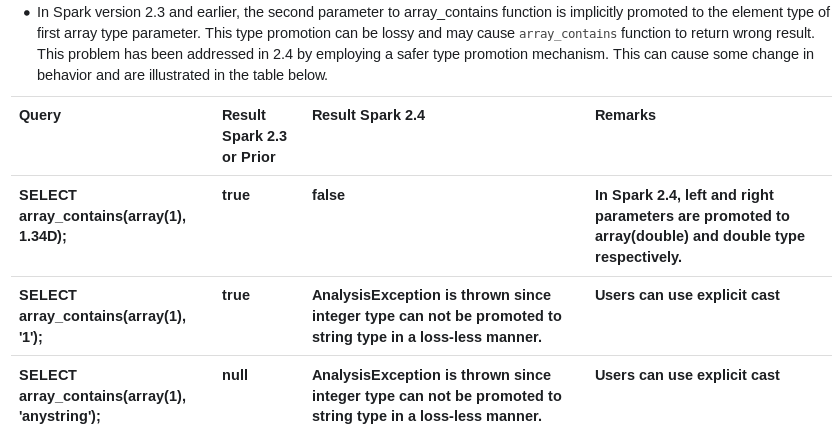
|
There was a similar issue for IN subquery expression which was addressed by #26485. |
|
cc @cloud-fan |
|
#26485 is accepted because it just makes the type coercion consistent between In and InSubquery. I think it's a wrong design that, we have many type coercion rules for different operators, and have a For In the future, we should really refactor this part. We should either separate type coercion rules by operators, or implement type coercion inside operators. |
|
(I'd follow whatever @cloud-fan recommends) |
|
me, too. |
|
@cloud-fan could you please review this PR and start tests |
|
let me make my review comment clear: I don't think we should simply call After taking a look at Now we can have a simple fix: replace |
docs/sql-migration-guide.md
Outdated
|
|
||
| - Since Spark 3.0, the unary arithmetic operator plus(`+`) only accepts string, numeric and interval type values as inputs. Besides, `+` with a integral string representation will be coerced to double value, e.g. `+'1'` results `1.0`. In Spark version 2.4 and earlier, this operator is ignored. There is no type checking for it, thus, all type values with a `+` prefix are valid, e.g. `+ array(1, 2)` is valid and results `[1, 2]`. Besides, there is no type coercion for it at all, e.g. in Spark 2.4, the result of `+'1'` is string `1`. | ||
|
|
||
| - Since Spark 3.0, the parameter(first or second) to array_contains function is implicitly promoted to the wider type parameter. |
There was a problem hiding this comment.
Ah, I see. The current latest fix looks reasonable. This fix is not a behaviour change but a bug fix.
There was a problem hiding this comment.
Thanks @cloud-fan @maropu
I will revert these changes from migration guide.
|
Test build #115234 has finished for PR 26811 at commit
|
|
Test build #115239 has finished for PR 26811 at commit
|
| """.stripMargin.replace("\n", " ").trim() | ||
| assert(e2.message.contains(errorMsg2)) | ||
|
|
||
| checkAnswer( |
There was a problem hiding this comment.
Since this is a bug, can you split these three tests into a separate test unit and add a test title with the jira ID(SPARK-29600)?
There was a problem hiding this comment.
Also, can you update the title, too?
|
Retest this please |
| s""" | ||
| |Input to function array_contains should have been array followed by a | ||
| |value with same element type, but it's [array<int>, decimal(29,29)]. | ||
| |value with same element type, but it's [array<int>, decimal(38,29)]. |
There was a problem hiding this comment.
why precision becomes 38 in this case?
There was a problem hiding this comment.
For query
array_contains(array(1), .01234567890123456790123456780)e.inputTypes will return Seq(Array(Decimal(38,29)), Decimal(38,29)) and above code will cast .01234567890123456790123456780 as Decimal(38,29).Previously, when we were using
findWiderTypeForTwo, decimal types were not getting upcasted but findWiderTypeWithoutStringPromotionForTwo will successfully upcast DecimalType
There was a problem hiding this comment.
Previously, when we were using findWiderTypeForTwo
Before this PR, we were using findTightestCommonType. Why do we add cast but still can't resolve ArrayContains?
There was a problem hiding this comment.
Do you mean why in above test case query, ArrayContains is throwing AnalysisException instead of casting integer to Decimal?
An integer cannot be casted to decimal with scale > 28.
decimalWith28Zeroes = 1.0000000000000000000000000000
SELECT array_contains(array(1), decimalWith28Zeroes);
Result =>> true
decimalWith29Zeroes = 1.00000000000000000000000000000
SELECT array_contains(array(1), decimalWith29Zeroes);
Result =>> AnalysisException
There was a problem hiding this comment.
There was a problem hiding this comment.
Yea I get that we can't do cast here. My question is: since we can't do cast, we should leave the expression un-touched. But now we add cast to one side and leave the expression unresolved. Where do we add that useless cast?
There was a problem hiding this comment.
This code is to cast left and right expression one by one. Here,
e.childernisSeq( array<int>, decimal(29,29)), ande.inputTypeswill returnSeq(array<decimal(38,29)>, decimal(38,29))
impicitCast(array<int>, array<decimal(38,29)>) will return None, since int can't be casted to decimal(38,29).
There was a problem hiding this comment.
Above code is creating new expression by updating only right child.
There was a problem hiding this comment.
ah thanks for finding this out!
|
Test build #115302 has finished for PR 26811 at commit
|
|
Test have passed. Kindly review this PR. |
|
thanks, merging to master! |
|
@amanomer can you leave a comment in the JIRA ticket, so that I can assign it to you? |
What changes were proposed in this pull request?
Use
TypeCoercion.findWiderTypeForTwo()instead ofTypeCoercion.findTightestCommonType()while preprocessinginputTypesinArrayContains.Why are the changes needed?
TypeCoercion.findWiderTypeForTwo()also handles cases for DecimalType.Does this PR introduce any user-facing change?
No
How was this patch tested?
Test cases to be added.