[SPARK-26416] [SQL] Refactor ColumnPruning from Optimizer.scala to ColumnPruning.scala
#23359
Conversation
| */ | ||
| private def removeProjectBeforeFilter(plan: LogicalPlan): LogicalPlan = plan transformUp { | ||
| case p1 @ Project(_, f @ Filter(_, p2 @ Project(_, child))) | ||
| if p2.outputSet.subsetOf(child.outputSet) => |
There was a problem hiding this comment.
I can see that this is a clean refactoring and this line is the additional style fix.
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
+1, LGTM (pening Jenkins)
|
@gatorsmile . Spark 3.0 is a good chance to make this more flexible for the future. |
|
It is hard for us to do the review in the future. Normally, we check the change history when doing the review. The change history is very important for us to do the review. |
|
? It's only about 100 line. Keeping each rule in a single file have more benefits. Historically, at 2.0.0, we did a lot of refactoring already. And, this is for 3.0. Technically, all history is in branch-2.4 and we can see it easily in GitHub. |
|
Discussed it with @dongjoon-hyun offline. There are various bug fixes in the code history. The change history is very valuable for us [especially for new contributors] to understand the code. Previously, we did the split, but it makes us much harder to find out the original PRs who introduced the changes. For example, the following screenshot can clearly show all the PRs that changed this column pruning rule. The change history is very useful for reviewers and new learners.
|
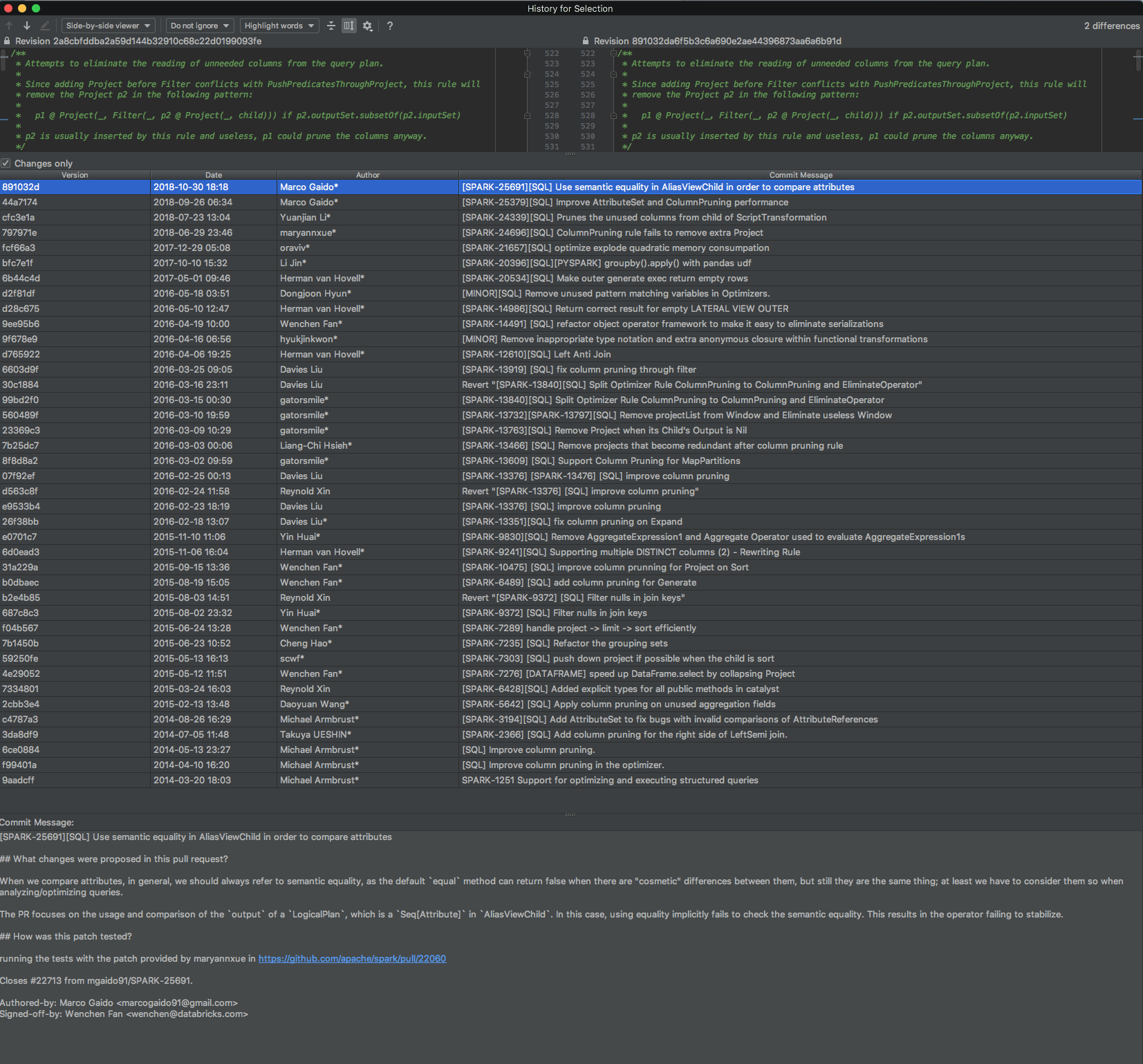
|
Maybe not all of you know this trick. You can get the history by selection in IntelliJ. See the screen shot.
|
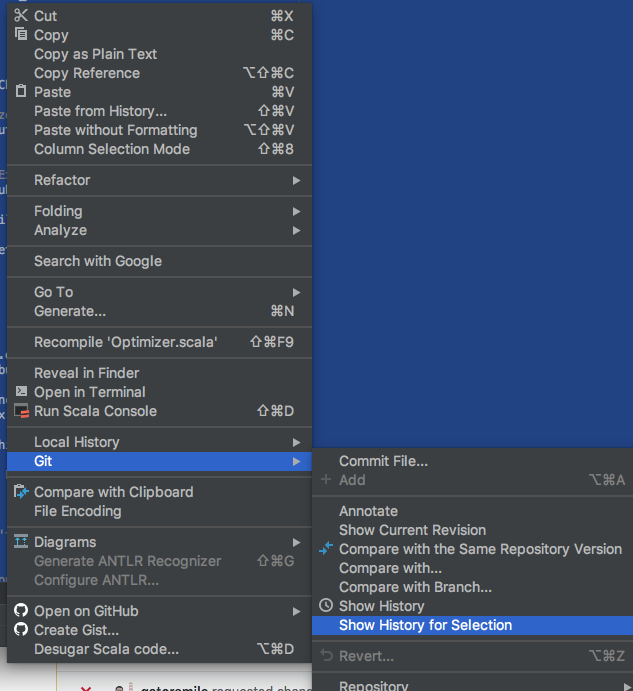
|
Test build #100351 has finished for PR 23359 at commit
|
|
Yep. I agree with @gatorsmile now. |
|
All the above is great conversation. I'm closing this PR. Thanks. |
What changes were proposed in this pull request?
As
Optimizer.scalabecomes bigger and bigger, it's hard to add new rules and maintain them. We are refactoring outColumnPruningfromOptimizer.scalatoColumnPruning.scalaso it's easier to add new logics inColumnPruning.How was this patch tested?
Existing tests.