PARQUET-1973: Support ZSTD JNI BufferPool #865
Conversation
 gszadovszky
left a comment
gszadovszky
left a comment
There was a problem hiding this comment.
What would be the pros/cons for a user to use or to not use the buffer pool in parquet-mr? I understand that you want to be on the safe side with this new configuration property but I am currently not sure if it is necessary. I would not extend the number of the existing configuration options if it is not required.
Anyway, if you think the configuration option is necessary, please, update the documentation in the README.md.
|
Hi, @gszadovszky . We observed this kind of issue on Java 11 environment. As I wrote in the PR description, |
|
Not only for the issues, but also there exists improvement. FYI, Apache Spark is using ZSTD JNI directly for shuffle IO and the followings are the corresponding update and benchmark PRs.
|
gszadovszky
left a comment
There was a problem hiding this comment.
Thanks for explaining. I've found a formatting issue in the readme. Otherwise it looks good to me.
parquet-hadoop/README.md
Outdated
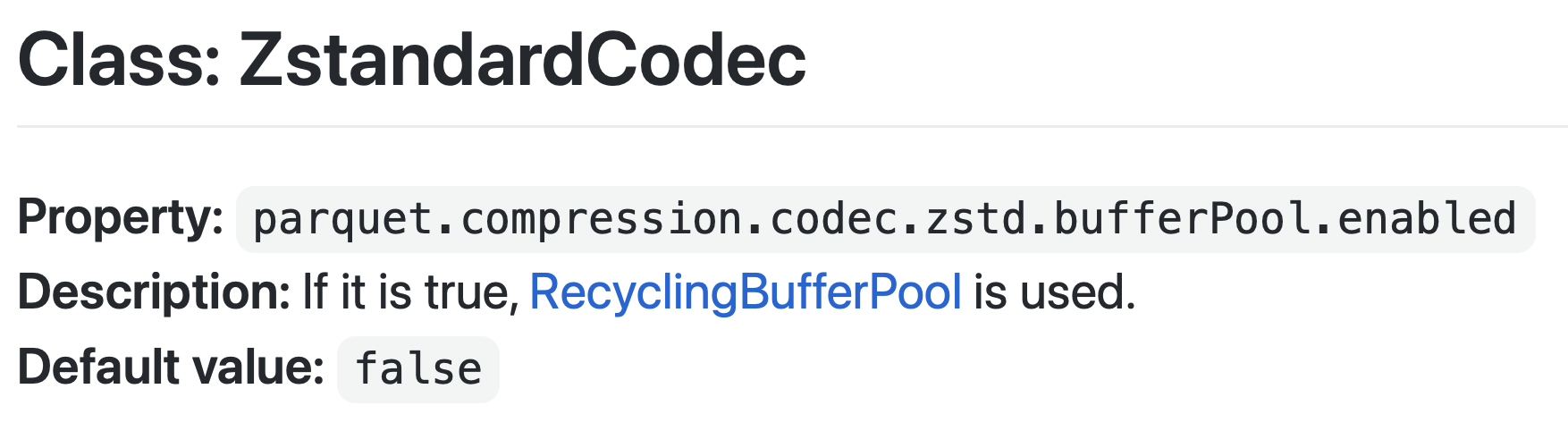
| **Property:** `parquet.compression.codec.zstd.bufferPool.enabled` | ||
| **Description:** If it is true, [RecyclingBufferPool](https://github.com/luben/zstd-jni/blob/master/src/main/java/com/github/luben/zstd/RecyclingBufferPool.java) is used. | ||
| **Default value:** `false` | ||
|
|
||
| --- | ||
|
|
There was a problem hiding this comment.
nit: please use double spaces at the end of the lines to enforce new-line. You can verify formatting by checking the page rendered by github: https://github.com/dongjoon-hyun/parquet-mr/tree/PARQUET-1973/parquet-hadoop#class-zstandardcodec
There was a problem hiding this comment.
Oh. Got it. Thanks!
|
Thank you, @gszadovszky . I added two ending spaces and checked the README. |
|
Thank you for approval, @gszadovszky . |
|
Thank you for merging, @gszadovszky ! |
| @Override | ||
| public CompressionOutputStream createOutputStream(OutputStream stream) throws IOException { | ||
| return new ZstdCompressorStream(stream, conf.getInt(PARQUET_COMPRESS_ZSTD_LEVEL, DEFAULT_PARQUET_COMPRESS_ZSTD_LEVEL), | ||
| BufferPool pool; |
There was a problem hiding this comment.
Thanks Dongjoon for working on this!
It is kind of late. Just a minor comment: if you can wrap the code into a method and call it in both CompressionInputStream() and CompressionOutputStream, it would avoid duplicating. Not a big deal though.
|
cc @vectorijk |
Jira
parquet.compression.codec.zstd.bufferPool.enabledto support ZSTD JNI's BufferPool feature.BufferPoolwas added and used it by defaultRecyclingBufferPoolwas added andBufferPoolbecame an interface to allow custom BufferPool implementationNoPoolis used by default and user should specify buffer pool explicitlyTests
Commits
Documentation