Data: delete compaction optimization by bloom filter #5100
Conversation
optimize the performance of delete compaction by bloom filter, just for parquet format in this PR.
close parquet reader
|
@rdblue can you give a review? thank you. |
|
|
||
| // load bloomfilter readers from data file | ||
| if (filePath.endsWith(".parquet")) { | ||
| parquetReader = ParquetUtil.openFile(getInputFile(filePath)); |
There was a problem hiding this comment.
Can we use try-with-resource here?
There was a problem hiding this comment.
Maybe it's a big change , I want to keep this reader open during the iteration of delete files, and considering orc format, the delete iteration need to be encapsulated in a new function, any advise for this change?
|
|
||
| Schema deleteSchema = TypeUtil.select(requiredSchema, ids); | ||
|
|
||
| if (filePath.endsWith(".parquet") && parquetReader != null) { |
There was a problem hiding this comment.
I think we can change the ctor parameter from String to DataFile and then here we can check file.format().
There was a problem hiding this comment.
yes, you are right, but dataFile is not passed into DeleteFilter as parameter, it was changed to filePath in #4381
There was a problem hiding this comment.
I see, any concern if we change it to DataFile?
There was a problem hiding this comment.
the change for constructor parameters is only for Trino supporting mor,Trino wrapped a dummy fileScanTask for data file currently, the author wants to remove fileScanTask implemented in Trino, and use the filePath parameter. If we change it to dataFile, compatibility is a problem.
| } | ||
|
|
||
| // load bloomfilter readers from data file | ||
| if (filePath.endsWith(".parquet")) { |
There was a problem hiding this comment.
Do we want to check whether the bloom filter is turned on to avoid reading the footer if it is not?
There was a problem hiding this comment.
You mean we check the bloom filter by table properties, right? but the bloom filter properties may be updated, the bloom filter in current file is unmatched with table properties.
|
We also encountered the same problem |
|
This pull request has been marked as stale due to 30 days of inactivity. It will be closed in 1 week if no further activity occurs. If you think that’s incorrect or this pull request requires a review, please simply write any comment. If closed, you can revive the PR at any time and @mention a reviewer or discuss it on the [email protected] list. Thank you for your contributions. |
|
This pull request has been closed due to lack of activity. This is not a judgement on the merit of the PR in any way. It is just a way of keeping the PR queue manageable. If you think that is incorrect, or the pull request requires review, you can revive the PR at any time. |
Purpose
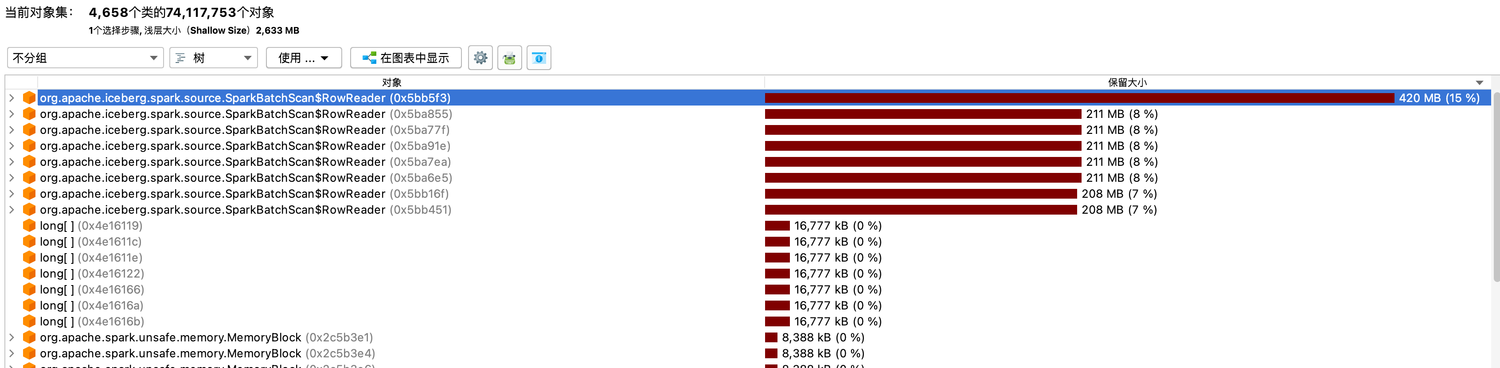
V2 table support equality deletes for row level delete, delete rows are loaded into memory when rewrite or query job is running, but this will cause OOM with too many delete rows in a real scenario, especially in flink upsert mode. As issue #4312 mentioned, flink rewrite jobs caused out of memory exception which also happen with spark or other engine support v2 table.
delete rows in hash set occupy most of the heap memory.
Goal
Reduce delete rows loaded in memory, optimize the performance of delete compaction by bloom filter, just for parquet format in this PR, thanks for the pull request of @huaxingao about the parquet bloom filter support #4831, and we are working on orc format.
How
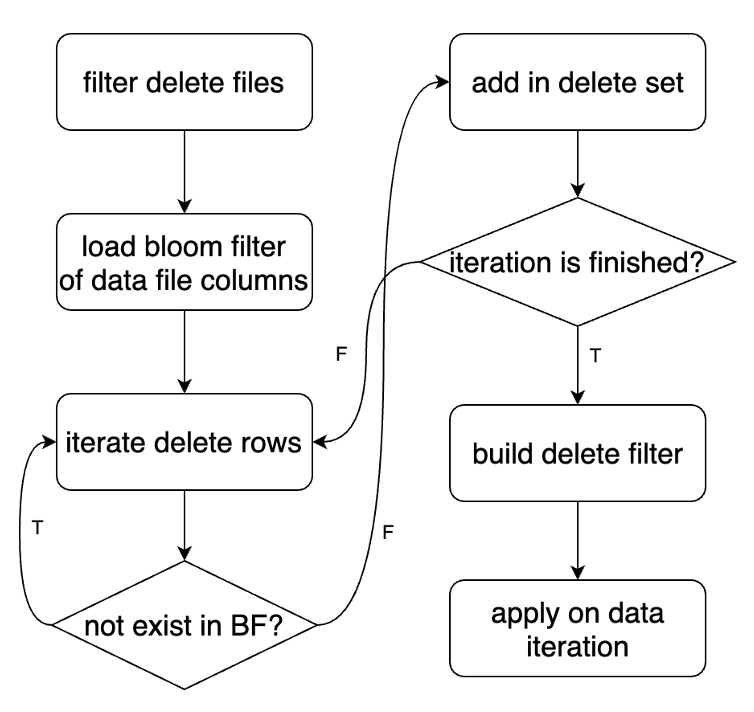
Before reading the equality delete data, load the bloom filter of current data file, then filter delete rows not in this data file.
Verification
We verified the performance improvement by a test case.
Environment:
Job: spark rewrite job with 300 million data rows and 30 million delete rows
executor num:2
executor memory:2G
executor core:8
Before optimization:
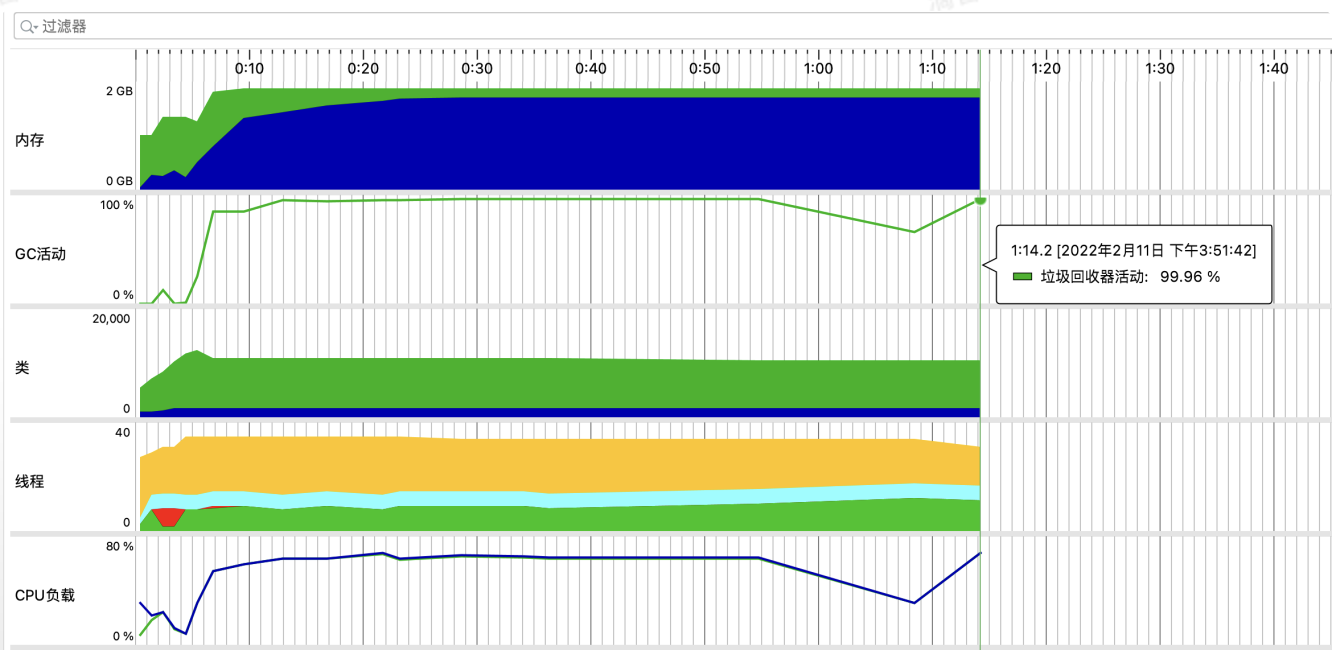
JVM did full gc frequently,this job failed in the end.
After optimization:

Obviously, the memory pressure reduced, and the job finished successfully.