Support pos-delete in vectorized read. #3287
Conversation
|
Do we have some benchmark that could show the benefit? Since we will have actions to convert the equality deletes and rewrite the position delete, so just curious about the performance improvement. |
Will add benchmark soon. |
| return remainingRowsFilter.filter(records); | ||
| } | ||
|
|
||
| public Set<Long> posDeletedRowIds() { |
There was a problem hiding this comment.
This could be very problematic for big delete files.
Maybe an iterator like interface would be better.
What do you think?
There was a problem hiding this comment.
As far as I see, ColumnarBatchReader will be checking if a particular position has been deleted for every position by probing this set. Using anything other than the set will make the current implementation extremely slow.
Large deletes are a valid concern. I wonder whether we should not enable vectorization in such cases at all.
There was a problem hiding this comment.
Can we use a bitmap here? We just need to know whether a particular bit is set.
There was a problem hiding this comment.
Yeah, I think a bitmap of deleted positions would work fine here and we will be able to support vectorization in all cases.
There was a problem hiding this comment.
Thanks @pvary and @aokolnychyi. Will use bitmap in the next commit, so that we don't have to worry about the memory constraint, considering bitmap is super compacted comparing to Set<Long>.
There was a problem hiding this comment.
Java's BitSet has its limitations
- Its max length is the max value of an integer, but the row position is a
Long. - For a large file with a few rows deleted at the end the files, their positions are big number, which means we need a lot of memory to store these positions. The worst case is we need a Integer.Max/8 bytes(about 0.25G) memory to store a single position value at the end of the file.
We need a Sparse BitSet which can support set a Long position.
There was a problem hiding this comment.
The https://github.com/RoaringBitmap/RoaringBitmap is used in the new commit, which can support index to be a 64-bit integer(long) and is more memory efficient than Java's BitSet. It is used by Spark as well as bunch of other ASF projects.
|
Thank you, @flyrain! Let me start looking today. |
|
Not related to this PR but a quick question. Why do we do an extra call to read the footer again while computing the offset to start position map in Any ideas, @chenjunjiedada @flyrain? Edit: Why do we even need that map? It seems we only use it fill out the array of start row positions? |
|
Okay, I went through the vectorized reader path to refresh my memory. I'll take a look at the PR itself with fresh eyes tomorrow. |
|
|
Okay, I see we are using empty options in that call. I assume it is because of the range metadata filter we are setting. |
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/BaseBatchReader.java
Outdated
Show resolved
Hide resolved
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/VectorizedSparkParquetReaders.java
Outdated
Show resolved
Hide resolved
| idToConstant, ColumnarBatchReader::new, deleteFilter)); | ||
| } | ||
|
|
||
| private static class ReaderBuilder extends VectorizedReaderBuilder { |
There was a problem hiding this comment.
How common is the new functionality? Would it make sense to modify VectorizedReaderBuilder instead of extending it here?
There was a problem hiding this comment.
If needed, we can probably extend VectroizedReader with setDeleteFilter?
There was a problem hiding this comment.
I tried to modify VectorizedReaderBuilder, but to add DeleteFilter into VectorizedReaderBuilder, we need to add module iceberg-data to the dependency of iceberg-arrow.
I guess that's fine? Will make the change in build.gradle. Let me know if there is any concern.
There was a problem hiding this comment.
Oh, to extend VectroizedReader with setDeleteFilter, we need to let module iceberg-parquet depend on iceberg-data, which will form a cyclic dependency, since iceberg-data has depended on iceberg-parquet,
Line 241 in dbfa71e
I'd suggest to move interface
VectorizedReader to module api if we really want to do this.
Also, is it possible to merge the module data into core, so that we don't need to make module arrow depend on data.
This seems a big change, I'd suggest to have a separated PR for it.
There was a problem hiding this comment.
We could move DeleteFilter to core. But it's minor. Let's not worry about it now.
| return remainingRowsFilter.filter(records); | ||
| } | ||
|
|
||
| public Set<Long> posDeletedRowIds() { |
There was a problem hiding this comment.
As far as I see, ColumnarBatchReader will be checking if a particular position has been deleted for every position by probing this set. Using anything other than the set will make the current implementation extremely slow.
Large deletes are a valid concern. I wonder whether we should not enable vectorization in such cases at all.
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
| return remainingRowsFilter.filter(records); | ||
| } | ||
|
|
||
| public Set<Long> posDeletedRowIds() { |
There was a problem hiding this comment.
Can we use a bitmap here? We just need to know whether a particular bit is set.
spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnVectorWithFilter.java
Outdated
Show resolved
Hide resolved
| */ | ||
| public class IcebergSourceFlatParquetDataDeleteBenchmark extends IcebergSourceBenchmark { | ||
|
|
||
| private static final int NUM_FILES = 500; |
There was a problem hiding this comment.
I'd say we should focus on a smaller number of files with way larger number of records.
It would be great to see numbers for these use cases:
- Deletes vs no deletes (non-vectorized, 5%, 25% deleted records)
- Vectorized vs non-vectorized deletes (5%, 25%)
- Equality vs position delete performance (non-vectorized)
There was a problem hiding this comment.
Updated the benchmark per suggestion.
b359612 to
ce4b333
Compare
| implementation "com.fasterxml.jackson.core:jackson-databind" | ||
| implementation "com.fasterxml.jackson.core:jackson-core" | ||
| implementation "com.github.ben-manes.caffeine:caffeine" | ||
| implementation "org.roaringbitmap:RoaringBitmap" |
There was a problem hiding this comment.
The library seems to be widely adopted in the big data ecosystem. I am +1 on using it instead of the inefficient Java implementation.
|
|
||
| public static Roaring64Bitmap toPositionBitMap(CloseableIterable<Long> posDeletes) { | ||
| try (CloseableIterable<Long> deletes = posDeletes) { | ||
| Roaring64Bitmap bitmap = new Roaring64Bitmap(); |
There was a problem hiding this comment.
Any tips on how to use this bitmap implementation in the most efficient way? For example, is setting bit by bit the only way to init the state? I checked the API and did not find anything applicable. Just asking. Maybe, we can check how Spark uses it.
There was a problem hiding this comment.
Okay, I spent some time reading/thinking about it.
Using a set of positions is a simple solution and would work fine for a small number of deletes. If the number of deletes is substantial, we may want to consider a bitmap. However, we have to use a bitmap that handles sparse datasets. In that case, Java BitSet would be perform terribly, most likely worse than a hash set of positions. According to what I read about RoaringBitmap, it does handle sparse datasets much better than Java BitSet but it can still occupy more memory than a simple hash set if values are indeed sparse.
The question is whether we are optimizing too much here. I'd do a quick benchmark and see if RoaringBitmap needs a lot of memory for sparse datasets when we have a couple of deletes at the beginning and end of range. If it is not bad, I'd use it all the time as we know it will be beneficial if we have a substantial number of deletes.
Druid also uses RoaringBitmapWriter to construct a bitmap. It is supposed to be more efficient than setting bit by bit.
There was a problem hiding this comment.
Also, we should take into account that we are computing delete positions for a single file. So the expectation is that it is a reasonable number of them as the user runs compactions.
To sum up, I'd test RoaringBitmap for sparse deletes. If it performs well, use it as it will be more efficient if we have many deletes. If it occupies a lot of memory for that use case, let's just use Set<Long>.
There was a problem hiding this comment.
We could, of course, have 2 implementations and one common interface but I am not sure it is worth the complexity.
There was a problem hiding this comment.
Here is the benchmark I did. I generated random positions out of 1M rows, ranging from 10 positions to 500K positions(50% of the total num of rows). I used SerializedSizeInBytes to get the memory footprint of the bitmap. It's not perfect to show how much memory really used, but a good indicator. There'd be some extra index needed, which should be minor. To get better comparison, I also present the memory usage by using the set<Long>, to make it simple, I use the Cardinality * length of a long(8 Bytes), extra overhead is needed for a set<Long>, but it doesn't affect our comparison. The results look promising, especially with bigger cardinalities, but even it is less than 1k, like 10 or 100. It is still good, at least not bad, the 10-cardinality case is still OK considering these numbers are random across 0 to 1M. In conclusion, we can get much better memory efficient by using the RoaringBitmap, and don't have to be limited by the num of deleted rows.

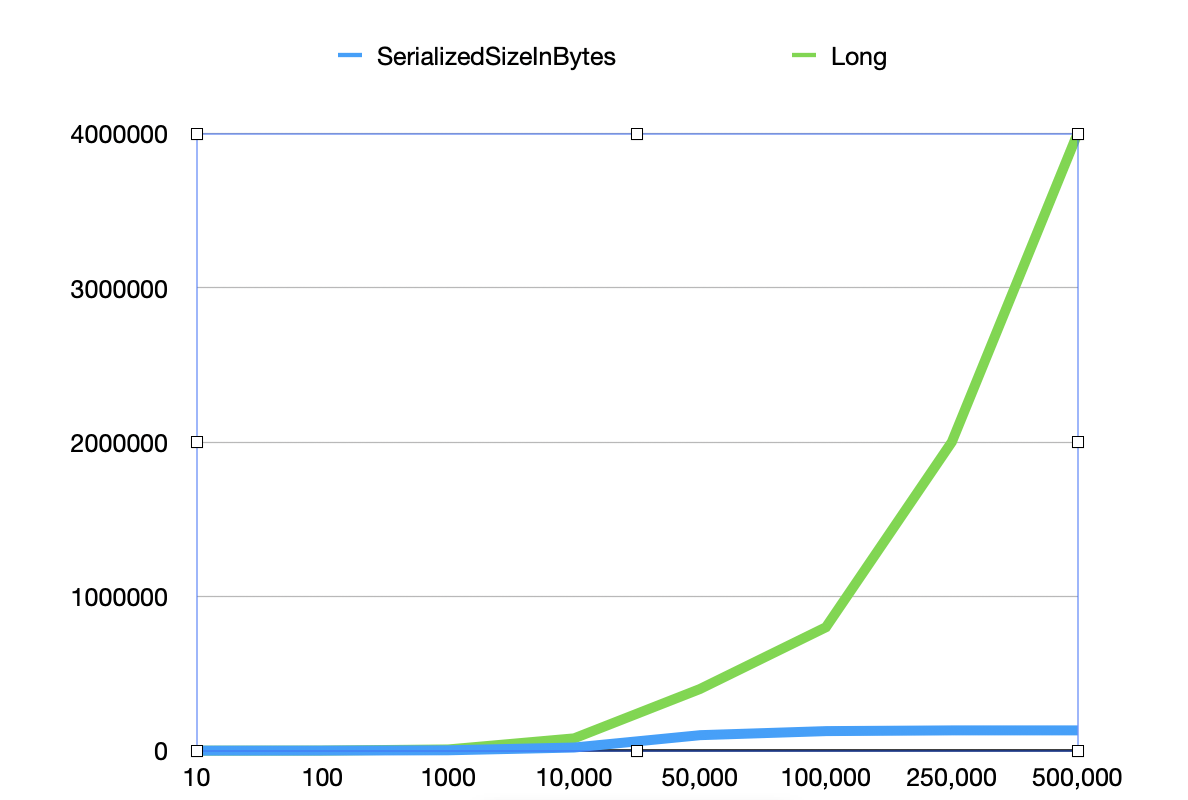
There was a problem hiding this comment.
Thanks for benchmarking! It seems safer to use the bitmap then. It will be just slightly worse for smaller numbers of deletes but we won't have to worry about larger numbers of deletes.
There was a problem hiding this comment.
How is the memory usage with an uncompressed bitmap? My thought here would be that the actual number of rows in a file is probably never actually that huge relatively, not a big deal though
There was a problem hiding this comment.
The uncompressed bitmap like Java's BitSet uses significant more memory in case of small cardinality. BitSet uses a continuous memory to record a bit, for example, if you want to set delete position which is at 1M, then BitSet needs 1M bit to only store this one bit.
There was a problem hiding this comment.
Another reason, we cannot use BitSet is that it doesn't support set a long, only integers.
....0/spark3/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnVectorWithFilter.java
Outdated
Show resolved
Hide resolved
|
|
||
| public static ColumnVector forHolder(VectorHolder holder, int[] rowIdMapping, int numRows) { | ||
| return holder.isDummy() ? | ||
| new ConstantColumnVector(Types.IntegerType.get(), numRows, ((ConstantVectorHolder) holder).getConstant()) : |
There was a problem hiding this comment.
Do we have a test where we project a constant while applying deletes?
There was a problem hiding this comment.
Added test testReadRowNumbersWithDelete for this.
8be80ce to
c8e2c54
Compare
|
Thanks for the great work, @flyrain! Thanks everyone for reviewing! |
|
Thanks a lot for the review, @aokolnychyi @RussellSpitzer @pvary @chenjunjiedada! |
Why do we need this PR?
As #3141 mentioned, vectorized reader does NOT support row-level delete currently. This PR adds the support for pos-delete. This implementation supports
both Spark 2 andSpark 3.2.Tests added
I parameterized TestSparkReaderDeletes, so that all tests under class TestSparkReaderDeletes now support both vectorized read and non-vectorized read. The ones with eq-delete still fall back to non-vectorized read at this moment.
Future work
I will add the equality-delete support in a follow-up PR.
Benchmark
#3287 (comment)
cc @rdblue, @aokolnychyi, @RussellSpitzer, @karuppayya, @szehon-ho @jackye1995