[HUDI-5341] IncrementalCleaning consider later clustering #7401
Conversation
|
Somehow i got the point why the data set duplication occurs, it is not because of the out of order execution of clustering, but because the fs view with clustering instants relies on the replace commit metadata to composite the file snapshots with replaced file handles, if we archive a clustering instant that has not been cleaned yet, the replace commit metadata is gone and the duplicates happens. One gold rule for the clustering archiving is: we can only archive the commit only when we make sure it's replaced instant has been cleaned successfully, while this should be very hard i guess because one clustering commit may replace multiple normal commits. A better way is to look up the archive timeline when there are clustering instants on the timeline. WDYT, @nsivabalan :) |
How abourt add a check before archive, require every instant to archive completed time must earlier than the latest cleaning instant start clean time |
Change Logs
In some scenes, such as offline clustering or online sync clustering(Parallel), later plans could completed before previous plans. If later plan belong to the next partation, and cleaning speed catch up with it,Incremental Cleaning mode for getPartitionPathsForIncrementalCleaning would ignore previous plans ,eventually lead to duplicate data.
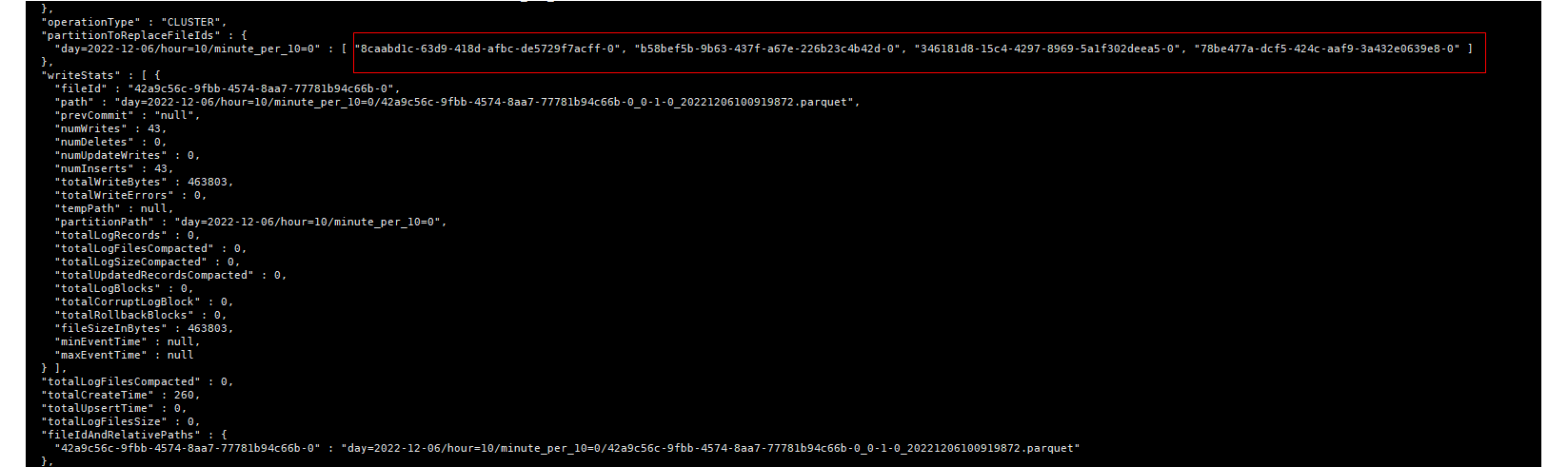
partation : day=2022-12-06/hour=10/minute_per_10=0 , day=2022-12-06/hour=10/minute_per_10=1

cleaning catch up with clustering belong to partation day=2022-12-06/hour=10/minute_per_10=1


log:
instant:
the file in previous clustering plan belong to partation 2022-12-06/hour=10/minute_per_10=0 won't clean forever. and it will cause duplicate data when the instants archived.
Impact
Describe any public API or user-facing feature change or any performance impact.
Risk level (write none, low medium or high below)
If medium or high, explain what verification was done to mitigate the risks.
Documentation Update
Describe any necessary documentation update if there is any new feature, config, or user-facing change
ticket number here and follow the instruction to make
changes to the website.
Contributor's checklist