ARROW-10500: [Rust] Refactor bit slice, bit view iterator for array buffers #8598
Conversation
|
Test failure seems to be because the Was there a specific test failure on a big endian machine with the previous code? |
There was a problem hiding this comment.
I wasn't familiar with the term "bit slice" before reading this PR (It is mentioned in the docs of https://docs.rs/bitvec/0.19.4/bitvec/, where perhaps the term came from.
| /// Bit slice representation of buffer data | |
| /// Bit slice representation of buffer data. A bit slice is a | |
| /// view on top of a buffer of bytes which can be used to | |
| /// access each bit. |
There was a problem hiding this comment.
| /// Returns immutable view with the given offset in bits and length in bits. | |
| /// Returns a new bit slice relative to self, with the given offset in bits and length in bits. |
rust/arrow/src/buffer.rs
Outdated
There was a problem hiding this comment.
I don't fully understand why this doesn't need to refer to len_in_bits -- how do we know that len_in_bits covers the entire buffer? Maybe this should be self.slice(len_in_bits/8)?
There was a problem hiding this comment.
That is the idea, bit view doesn't cover the whole Buffer. If you give the whole buffer's length in bits and start offset as 0 then it will cover the whole buffer. Otherwise, we can use a partial bit view on the Buffer.
There was a problem hiding this comment.
If you give the whole buffer's length in bits and start offset as 0 then it will cover the whole buffer
Right, what I don't understand is how the test for len_in_bits % 8 == 0 is checking for the whole buffer length. It seems like it is checking that len_in_bits is a multiple of 8 (aka represents whole bytes)
Maybe there is some assumption here like self.len_in_bits < 8?
 alamb
left a comment
alamb
left a comment
There was a problem hiding this comment.
Thanks @vertexclique!
In your description, you mention that this PR does the following
Support native endianness
It wasn't obvious to me that this was the case (probably because I don't fully understand the issue) but I also didn't see any test cases
Fix problems related to bit operations
Could you possibly explain what problem you saw with native endianness (maybe even with a test case) as well as what problems with bit operations you were fixing?
Gives any primitive interpretation for an underlying bit field, doesn't force concrete u64. So different offset sizes in offset buffers are also reinterpretable.
I suggest adding test cases demonstrating using an offset size other than u64
rust/arrow/src/buffer.rs
Outdated
There was a problem hiding this comment.
Can you explain the rationale for this change? It seems to use more code to accomplish the same functionality without any performance improvement. I am likely missing something
There was a problem hiding this comment.
I have moved the remainder calculation here. The remainder calculation was at the end of this method. It looks like more code because now we explicitly know what is bit view and what is chunk iterator. It was quite a bit blurry before. Now you can have a bit view over the buffer while having chunks and remaining bits do their work. It is for readability and not consuming chunk iterator.
There was a problem hiding this comment.
It wasn't obvious to me that this was the case (probably because I don't fully understand the issue) but I also didn't see any test cases
Previous implementation forces use of little endianness in Buffer data. From the writer's point of view, this might be desired, like in ARMv7(or more likely mips). Where writers don't need to reverse every byte they needed to write into a buffer in little-endian format to make it work while reading too. It is a small consideration.
Could you possibly explain what problem you saw with native endianness (maybe even with a test case) as well as what problems with bit operations you were fixing?
Sure, problems were not about native endianness. It was about the previous implementation. In the production code, I see some problems with the current implementation like https://issues.apache.org/jira/browse/ARROW-10461 . So I wanted to prevent it once and for all and wanted to adapt the current code to also interpret data not only u64 but u32, u16, u8, and when LLVM allows us u1.
About the test cases, I am going to go under ARMv7 integration soon. I can write some MSB tests here too. But I think I will touch most code parts for that anyway. If wanted I can pour some msb tests here.
I suggest adding test cases demonstrating using an offset size other than u64
Sure, u32 interpretation, I can do that.
rust/arrow/src/buffer.rs
Outdated
There was a problem hiding this comment.
I have moved the remainder calculation here. The remainder calculation was at the end of this method. It looks like more code because now we explicitly know what is bit view and what is chunk iterator. It was quite a bit blurry before. Now you can have a bit view over the buffer while having chunks and remaining bits do their work. It is for readability and not consuming chunk iterator.
rust/arrow/src/buffer.rs
Outdated
There was a problem hiding this comment.
That is the idea, bit view doesn't cover the whole Buffer. If you give the whole buffer's length in bits and start offset as 0 then it will cover the whole buffer. Otherwise, we can use a partial bit view on the Buffer.
|
I am going to change the whole data fusion tests to take machine epsilon into consideration. Didn't see that coming. |
|
It seems like #8571 may conflict with this PR as well |
|
This PR solves that problem intrinsically. Yes, it is a conflict. |
|
So my feedback here is that it is not clear to me what this PR is trying to accomplish (aka answer the question of why make the changes in this PR) and thus it is not clear how to review / evaluate it. If the PR's aim is to add support for endianness, I would expect some demonstration that the new code can do something that the old code can't (aka tests) If the PR's aim is to fix bug, I would expect some explanation / demonstration / of something that fails without the changes in the PR and passes with changes in the PR. The bugs this PR's changes fixes are probably obvious to you, but sadly they are not to me :( If the PR's aim is to make the code easier to understand, I would expect some description of why the new code is easier to understand than the old (which will be a subjective judgement, for sure). Since this PR seems to have elements of all three goals, but is light on the explanation, I am struggling to evaluate it concisely |
alamb
left a comment
There was a problem hiding this comment.
I think with the tests this PR looks good. I still don't fully understand https://github.com/apache/arrow/pull/8598/files#r518733422, so I would appreciate some additional clarifications
rust/arrow/src/buffer.rs
Outdated
There was a problem hiding this comment.
If you give the whole buffer's length in bits and start offset as 0 then it will cover the whole buffer
Right, what I don't understand is how the test for len_in_bits % 8 == 0 is checking for the whole buffer length. It seems like it is checking that len_in_bits is a multiple of 8 (aka represents whole bytes)
Maybe there is some assumption here like self.len_in_bits < 8?
Here comes the explanation @alamb and team:
Here you can see mips (be) test results: Here you can see armv7 (le) test results:
I hope I have answered all your questions. |
|
fyi @jhorstmann this PR likely would cause conflicts with #8571 -- I wonder if you have any opinions on how to proceed |
Thank you! I think with the additional tests demonstrating bug fixes and features, this PR is a good step forward and I would be amenable to merging it |
There was a problem hiding this comment.
Can we move the remainder loop down again so that we are summing elements in the order that they are in the array?
There was a problem hiding this comment.
I'm wondering whether this is really correct, the way I understood it is that little/big endian only affect the layout of bytes in memory, not how individual bits are accessed in a number. In this testcase the least significant bit of the first byte is zero and would be considered the first value if this was a boolean array or null bitmap. Same for the 4th least significant bit, which is where the slice here should start. This means the least significant bit of the chunk should be zero.
Or am I missing something?
|
When I introduced this initially in ARROW-10040 one feedback was that big endian was not supported yet anyway so it would not be necessary to worry about that now. I think it could be made to work rather easily by calling Adding a dependency that already implements the chunking and remainder logic is nice. I would have expected that to reduce the code size though. The The sum aggregation kernel is another bigger user of the bit slice functions and also regressed a bit: Most benchmarks don't seem to be affected much, probably because there is some other overhead or they are not using the chunked functions. Cast kernels for example are implemented using iterators of optional values and so use a different code path. |
alamb
left a comment
There was a problem hiding this comment.
FYI This PR may also be related / partially conflict with #8541
I think we should address @jhorstmann 's measurements of performance regressions before this pR is merged.
|
I don't think that's needed at all. Optimizations were extremely premature. We should have thought about the future beforehand. I think we are prolonging the discussion without any good point in it. Performance can improve later when we have correct code first.
|
There was a problem hiding this comment.
@vertexclique , thanks a lot for this, and specially for bringing the bitvec lib.
I went through this PR and I believe that the idea is good, specially the parts where we replace unsafe code, that we use a dependency to solve this problem for us, and that we do not limit to a single chunk size.
Furthermore, I am also of the opinion that correct code is better than fast code.
As @alamb and @jhorstmann , I am a bit concerned with the performance regression that this entails. 8x on buffer_bit_ops is a significant, IMO, and a 25% on an horizontal aggregation also seems significant for me.
@vertexclique , no one is trying to block this PR per se, I think that folks are just a bit concerned over the performance regression. Do you have any idea of where this performance hit could have come from?
For example, I would be fine with it if reason is that we now perform checks to guarantee no undefined behavior (UB), because in that case the comparison is not really fair.
One thing that I think would help this PR get merged would be to separate it into two: one where we refactor the code using bitvec, and another where we go through the endianess.
IMO the endianess is a feature sufficiently large that justifies a discussion on the mailing list: we need to understand if the maintainers are willing to take it. We would also need to setup the CI, understand which tests we need to generalize to be run on the two platforms, etc.
|
A few weeks/months ago when I was trying to work on bit slicing, I'm going to look at what the reason for the perf regressions is, during the week in my evenings. I haven't been able to profile criterion benchmarks with the tool that I use (https://superluminal.eu/), so I'll write some small application(s) so I can get the perf profiles for this. @vertexclique @jorgecarleitao there's been work on Java and C++ to support big-endian architectures; so maybe we can check in on previous mailing list discussions for guidance. I think CI might be the main concern (incl for arm-v7 support). I'd also prefer if we separate the big-endian functionality, and work on it as a separate PR. |
|
I have created: https://issues.apache.org/jira/browse/ARROW-10535 I can only move tests to another PR because it is a generic code and without the generic code won't compile. I can remove the big-endian tests and after merging this PR I can create yet another PR from master containing big-endian tests. |
801ca15 to
d3c6305
Compare
4f5e1cf to
7ca1bc5
Compare
|
So, I have fixed all unreproducible benchmarks that we are running in #8635. Also open-sourced a benchmark utility https://github.com/vertexclique/zor to create always the same baseline for all people who runs Running master with reproducible benches and doing the same for this PR gives these results:
I measured the performance. 🙃 It is in the PR description.
Would be nice! I have used the perf counters, and disasm so far and didn't see anything except bounds checks and proper alignment checks. Attached left is the master's code right is this pr. Mind that left doesn't jump to remainder checks because it is erased by const prop in remainder bits that I have applied with 7696b89#diff-4eec3bf3d3993d5a6a7fa0b6a0b057dc5b517b7737eb47e00a887e7a3dcb1c37R65
Definitely, I will start a thread tomorrow. Also opened: #8634 |
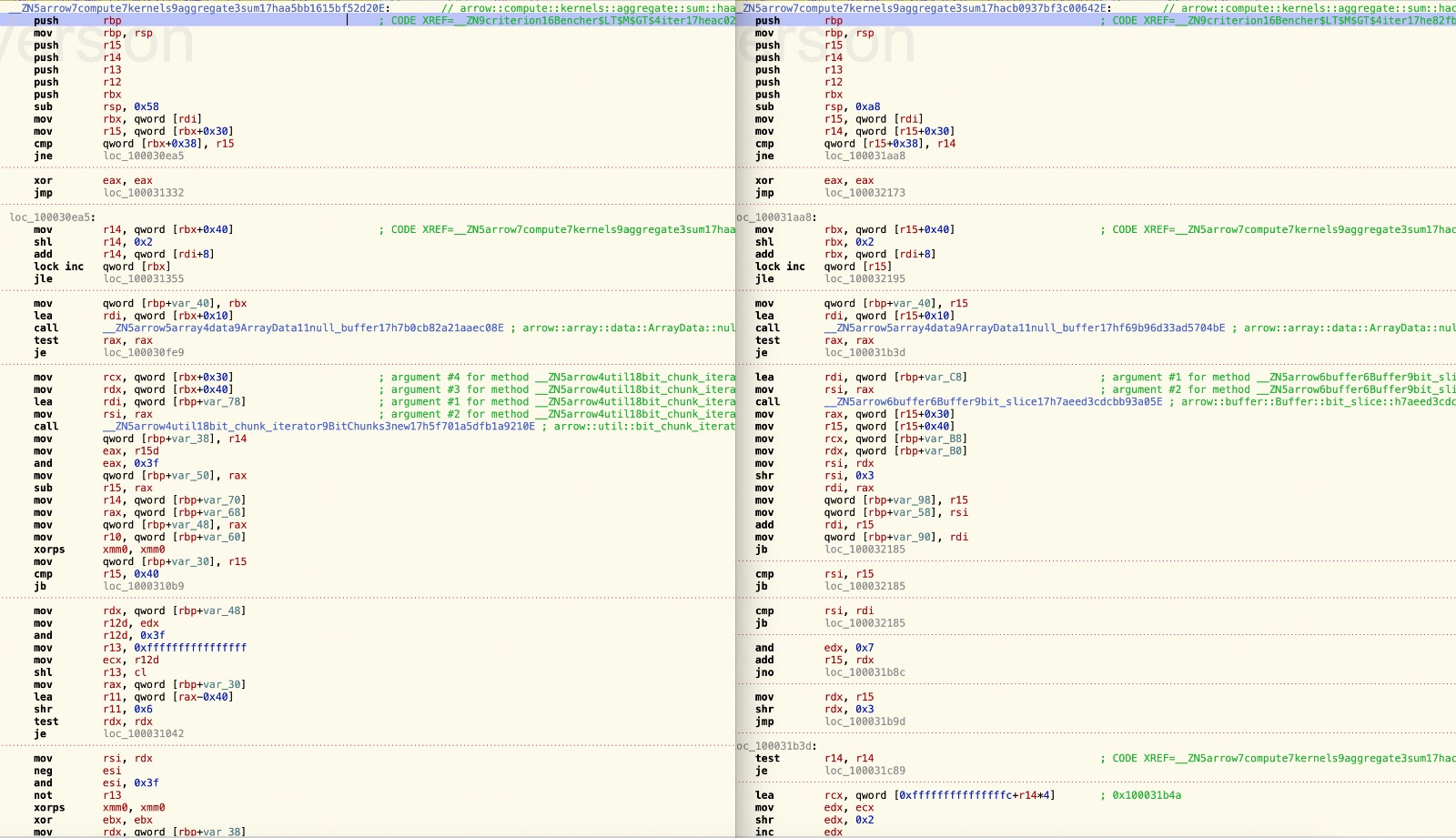
That's exactly where I took the benchmark results from. But yes, the regression in I had one other comment about the separate testcases for big-endian architectures, or restricting tests to little-endian, that was not yet addressed:
Consider the following buffer of u8, used as bit-packed data, with the indices of bytes and bits written below To get the value of the 12th bit we would check bit (12%8) of byte (12/8). Viewing this as a larger type (u16 for simplification): To check the same bit we would need to check bit (12%16) of word (12/16). So the value as u16 would be 4096 and this should be independent of the machine-endianness. Endianness only influences how the u16 would be stored in memory, but our underlying data consists of u8 in memory. |
|
Some additional data: I ran the tests under valgrind (as described in #8645 (comment)) on this branch after rebasing against master. This branch appears to have the same errors as reported on master (It did not introduce anything new, but neither does it fix the issue that #8645 appears to do): I did: Which then reported: |
|
Yes, it won't until that method rewritten using the bit-slice iterator :) written here: #8645 (comment) |
82171cc to
54c7056
Compare
|
Closing in favor of ARROW-10588 at #8664 |
Currently, bit slice, bit view, and operations looking blurry.
Benchmarks are here.