GH-34322: [C++][Parquet] Encoding Microbench for ByteArray #34323
Conversation
|
|
|
/cc @rok |
|
@mapleFU Any benchmark data? |
|
I'll test it on my mac and PC tonight :) |
|
This looks pretty good. |
|
Spaced encoding would be added, by the way, I wonder if it's valuable to add benchmark for string with different lengths. By the way, I think it's trickey that, DELTA_LENGTH would be powerful when compression is enabled. However, currently we don't test compression during encoding benchmark |
|
You are currently test strings of length 0 - 1024 with uniform length distribution. Maybe longer ones could be interesting, or maybe a range from say 4 - 20 or just all the of length 8. Or maybe a mix of 95% uniform distribution of 0 - 10 and 5% uniform distribution of 500 - 1000. Perhaps you can try locally if you get interesting results and only include different benchmarks.
Maybe that's worth opening another issue? |
|
Okay, I'd like to add spaced test, and submit a report on different machines tonight. By the way, I'd like to test that #14293 (comment) would boost encoder performance. |
|
To be honest, I found that decoding DELTA_LENGTH_BYTE_ARRAY is much more slower than I expected... After some trivial optimization on Decoder, the speed between them are equal. The previous impl is too slow |
|
On my MacOs, Release ( O2) enabled, with default memory allocator: And after #34336 : |
|
After using |
| // Using arrow generator to generate random data. | ||
| int32_t max_length = state.range(0); | ||
| auto array = | ||
| rag.String(/* size */ 1024, /* min_length */ 0, /* max_length */ max_length, |
There was a problem hiding this comment.
Should the size (1024 here) be adjustable? Reasonable options may include 256, 512, 4096.
There was a problem hiding this comment.
I'd add different options only if there is nonlinear behavior (time complexity != O(n)).
There was a problem hiding this comment.
Sometimes we need to adaptively determine a best batch size in the compute engine. Providing different batch sizes may give us better visibility on the encoding side. I suspect it will demonstrate a linear behavior as it has barriers including the block size or encoding pattern. @rok
There was a problem hiding this comment.
But how many do we need to catch performance regressions?
 rok
left a comment
rok
left a comment
There was a problem hiding this comment.
I'll do another pass tomorrow, but except for the CI issue it looks pretty good.
|
Seems the batch size sometimes impact the performance a lot ... |
|
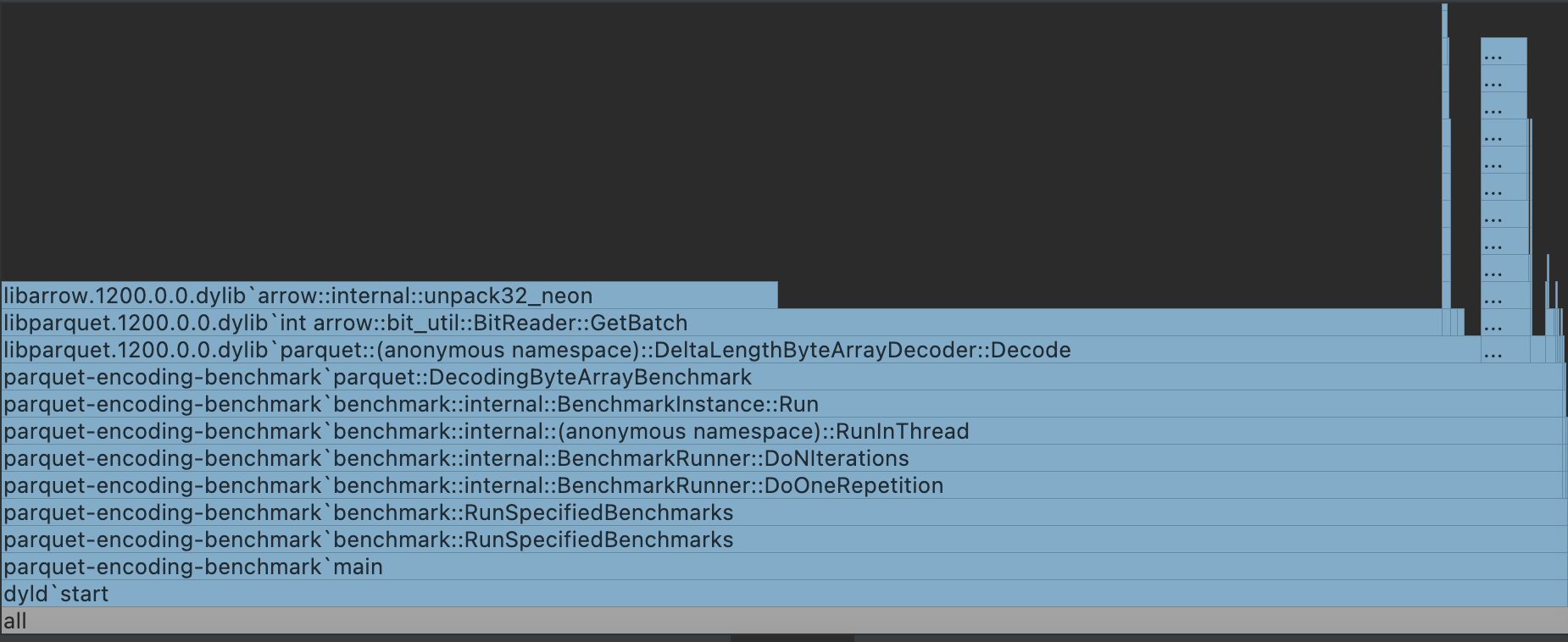
I guess that's expected, after applying #34336 . They runs much more faster. Let me upload a flamegraph |
|
It Spend lots of time on unpack, because it use So it's still expected |
|
IMHO,
static constexpr uint32_t kValuesPerBlock = 128;
static constexpr uint32_t kMiniBlocksPerBlock = 4;
|
|
I've test it here: #34323 (comment) Let us do it patch by patch and make this benchmark merged first. |
|
Optimizations would be great but let's track them in separate issues and use ursabot commands (listed here https://ursalabs.org/blog/announcing-conbench/). |
Good to know we have the command in hand! |
|
Waiting for pitrou see and merge it |
|
Ping @pitrou :) |
|
@wjones127 @rok Seems @pitrou doesn't have spare time? Should I wait for him or wait others to take a look at this patch? |
|
On my MacOS, after change item processed to data + offset: |
|
Benchmark runs are scheduled for baseline = bd80051 and contender = 22f2980. 22f2980 is a master commit associated with this PR. Results will be available as each benchmark for each run completes. |
|
['Python', 'R'] benchmarks have high level of regressions. |
…34955) ### Rationale for this change According to #34323 . DELTA_LENGTH_BYTE_ARRAY is much more slower. So do some optimizations. ### What changes are included in this PR? Some tiny changes ### Are these changes tested? ### Are there any user-facing changes? * Closes: #34335 Authored-by: mwish <[email protected]> Signed-off-by: Will Jones <[email protected]>
…RAY (apache#34955) ### Rationale for this change According to apache#34323 . DELTA_LENGTH_BYTE_ARRAY is much more slower. So do some optimizations. ### What changes are included in this PR? Some tiny changes ### Are these changes tested? ### Are there any user-facing changes? * Closes: apache#34335 Authored-by: mwish <[email protected]> Signed-off-by: Will Jones <[email protected]>
…RAY (apache#34955) ### Rationale for this change According to apache#34323 . DELTA_LENGTH_BYTE_ARRAY is much more slower. So do some optimizations. ### What changes are included in this PR? Some tiny changes ### Are these changes tested? ### Are there any user-facing changes? * Closes: apache#34335 Authored-by: mwish <[email protected]> Signed-off-by: Will Jones <[email protected]>
Rationale for this change
After #14293 . We have
DELTA_BYTE_LENTHfor encoding ByteArray. So, I'd like to have encoding benchmark for them.What changes are included in this PR?
Benchmark add some cases.
Are these changes tested?
No
Are there any user-facing changes?
No