ARROW-9235: [R] Support for connection class when reading and writing files
#12323
Conversation
|
|
|
Without having looked closely at the code, I suspect you're right about threading. IIUC R's memory allocation is not thread safe, so we can't call R functions that allocate in R with multithreading. In the conversion code, @romainfrancois did something clever to distinguish the things that could run in parallel from the things that could not. Another option to explore here, perhaps to confirm the issue, would be to do all of the things to disable multithreading (thread pools to 1, arrow.use_threads = FALSE) and see if that makes the crash go away. |
|
The Parquet error was, fortunately, not a concurrency issue, but an assumption that the input would be a # remotes::install_github("paleolimbot/arrow/r@r-connections")
library(arrow, warn.conflicts = FALSE)
addr <- "https://github.com/apache/arrow/raw/master/r/inst/v0.7.1.parquet"
read_parquet(addr)
#> Error: file must be a "RandomAccessFile"I've also removed references to the R_ext/Connections.h header that was causing the CMD check issue...no need to poke that bear yet. Tomorrow I'll implement |
a36cb73 to
5fbe59e
Compare
|
OK, I think this is ready for review. There is a threading issue that cause In general, all writers work and any readers work that don't call the stream's Reprex: # remotes::install_github("paleolimbot/arrow/r@r-connections")
library(arrow, warn.conflicts = FALSE)
tbl <- tibble::tibble(x = 1:5)
# all the writers I know about just work
tf_parquet <- tempfile()
write_parquet(tbl, file(tf_parquet))
tf_ipc <- tempfile()
write_ipc_stream(tbl, file(tf_ipc))
tf_feather <- tempfile()
write_feather(tbl, file(tf_feather))
tf_csv <- tempfile()
write_csv_arrow(tbl, file(tf_csv))
# some readers work...
read_parquet(file(tf_parquet))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
read_ipc_stream(file(tf_ipc))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
# ...except the ones that read from other threads
read_feather(file(tf_feather))
#> Error: IOError: Attempt to call into R from a non-R thread
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/io/interfaces.cc:157 Seek(position)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/reader.cc:1233 ReadFooter()
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/reader.cc:1720 result->Open(file, footer_offset, options)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/feather.cc:713 RecordBatchFileReader::Open(source_, options_)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/feather.cc:793 result->Open(source, options)
read_csv_arrow(file(tf_parquet))
#> Error in `handle_csv_read_error()` at r/R/csv.R:198:6:
#> ! IOError: Attempt to call into R from a non-R thread
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/io/interfaces.cc:86 stream_->Read(block_size_)
# ...even with use_threads = FALSE
options(arrow.use_threads = FALSE)
read_feather(file(tf_feather))
#> Error: IOError: Attempt to call into R from a non-R thread
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/io/interfaces.cc:157 Seek(position)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/reader.cc:1233 ReadFooter()
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/reader.cc:1720 result->Open(file, footer_offset, options)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/feather.cc:713 RecordBatchFileReader::Open(source_, options_)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/ipc/feather.cc:793 result->Open(source, options)
read_csv_arrow(file(tf_parquet))
#> Error in `handle_csv_read_error()` at r/R/csv.R:198:6:
#> ! IOError: Attempt to call into R from a non-R thread
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/io/interfaces.cc:86 stream_->Read(block_size_)
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/util/iterator.h:270 it_.Next()
#> /Users/deweydunnington/Desktop/rscratch/arrow/cpp/src/arrow/csv/reader.cc:996 buffer_iterator_.Next()Created on 2022-02-15 by the reprex package (v2.0.1) |
|
@westonpace can you take a look at this threading issue? I believe the constraint is that we can't call any R function that will allocate memory from other threads, so it would not surprise me that the Read methods would have to be called single-threaded. But surely that's something we should have the ability to control. cc @romainfrancois since I know you've fought with this in the past. |
|
Just leaving a ping here since I'm back from vacation an am ready to pick this up with some feedback on whether or not what I've done here is a reasonable approach to the concurrency limitations in Arrow (or whether or not anything can be done about the concurrency limitations from the Arrow end of things). |
|
TL;DR: We can solve this, we probably want to solve this, but it will involve some C++ effort. Sorry for the delay in looking at this. We certainly have some options here. This is a great chance to start putting some scaffolding we've laid down to good use. The fact that the parquet reader works here is actually a fluke that we will someday fix (:laughing:) with ARROW-14974. There are two thread pools in Arrow. The CPU thread pool and the I/O thread pool. The CPU thread pool has one thread per core and these threads are expected to do lots of heavy CPU work. The I/O thread pool may have few threads (e.g. if using a hard disk) or it may have many threads (e.g. if using S3) and these threads are expected to spend most of their time in the waiting state. CPU threads should generally not block for long periods of time. So when they have to do something slow (like read from disk) they put the task on the I/O thread pool and add a callback on the CPU thread pool to deal with the result. When use_threads is false we typically interpret that as "don't use up a bunch of CPU for this task" and we limit the CPU thread pool. Ideally we limit it to the calling thread. In some cases (e.g. execution engine) we limit it to one CPU thread and the calling thread (though I'm working on that as we speak). What we don't usually do is limit the I/O thread pool in any way. We have the tooling to do this (basically the queue that you mentioned) but will need to do some work to wire everything up. We can probably come up with a "limit all CPU and I/O tasks to the R thread" solution more easily than a "use the CPU thread pool for CPU tasks but limit all I/O tasks to the R thread" but the latter should probably be possible. It will also be easier to support the whole-table readers & writers initially and then later add support for streaming APIs. Also, this will have some performance impact when reading multiple files. For example, if you were to read a multi-file dataset from curl you would generally want to issue parallel HTTP reads but if we're only allowed to use a single thread for the read then that will not work. Although, we could probably address that particular performance impact if the underlying technology has support for an asynchronous API (as it seems that R's curl package does) so we can have three thread pools! (:dizzy:) What's the timing on this? I'm a little busy at the moment but I should be able to find some time this week to sketch a solution for the read_feather call (which could be adapted for read_csv or I could sketch the solution for read_csv first). |
|
Thanks!
There is no particular rush on
I'm still wrapping my head around the specifics here, but because they might be related I'll list the "calling the R thread" possibilities I've run into recently in case any of them makes one of those options more obvious to pursue.
From the R end, I know there is a way to request the evaluation of something on the main thread from elsewhere; however, there needs to be an event loop on the main thread checking for tasks for that to work. I don't know much about it but I do know it has been used elsewhere for packages like Shiny and plumber that accept HTTP requests and funnel them to R functions.
In my mind, supporting R connections is more about providing a (possibly slow) workaround for things that Arrow C++ or the R bindings can't do yet (e.g., URLs). I do know that the async API for curl from the R end is along the lines of |
342ec9b to
a2a95eb
Compare
a2a95eb to
c8fb8e5
Compare
There was a problem hiding this comment.
This is ready for a re-review! All the writers and readers that I know about work (see reprex in 'details'), although the Parquet reader working is actually a bug (ARROW-14974). The details of wrapping the read calls in RunWithCapturedR() needs to be finalized...I've made it work here but we need a better pattern for this before this can be merged. We could also "mark" connection InputStream/Reader objects as requiring RunWithCapturedR() to avoid any issues this might cause (since the read functions are some of the most heavily used functions).
Details
# remotes::install_github("paleolimbot/arrow/r@r-connections")
library(arrow, warn.conflicts = FALSE)
tbl <- tibble::tibble(x = 1:5)
# all the writers I know about just work
tf_parquet <- tempfile()
write_parquet(tbl, file(tf_parquet))
tf_ipc <- tempfile()
write_ipc_stream(tbl, file(tf_ipc))
tf_feather <- tempfile()
write_feather(tbl, file(tf_feather))
tf_csv <- tempfile()
write_csv_arrow(tbl, file(tf_csv))
# the readers now work too
read_parquet(file(tf_parquet))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
read_ipc_stream(file(tf_ipc))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
read_feather(file(tf_feather))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
read_csv_arrow(file(tf_csv))
#> # A tibble: 5 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
r/src/csv.cpp
Outdated
There was a problem hiding this comment.
In order for the connection thing to work for read_csv_arrow(), we need to wrap table_reader->Read() with RunWithCapturedR(), but we need a cleaner way to do it than what I have here!
There was a problem hiding this comment.
Luckily we have table_reader->ReadAsync() for just this purpose (I think)
There was a problem hiding this comment.
This collapses things down nicely!
There was a problem hiding this comment.
Actually, table_reader->ReadAsync() seems to crash (or at least the test output abruptly ends) on Windows (the method you suggested for the Feather reader works fine though).
- https://github.com/apache/arrow/runs/5996202038?check_suite_focus=true#step:23:4464
- https://github.com/apache/arrow/runs/5996202147?check_suite_focus=true#step:23:3993
- https://github.com/apache/arrow/runs/5996202233?check_suite_focus=true#step:23:3991
r/src/feather.cpp
Outdated
There was a problem hiding this comment.
In order for the connection thing to work for read_csv_arrow(), we need to wrap reader->Read() with RunWithCapturedR(), but we need a cleaner way to do it than what I have here!
There was a problem hiding this comment.
Unfortunately we do not have a reader->ReadAsync here. There is arrow::ipc::RecordBatchFileReader::ReadRecordBatchAsync but it is private at the moment and also, not exposed to arrow::feather at all.
So we could create a JIRA to expose that in C++. In the meantime, the "standard" way to solve "the underlying file reader doesn't have a true asynchronous implementation" is to do:
const auto& io_context = arrow::io::default_io_context();
auto fut = io_context.executor()->Submit(...);
That should work ok here.
There was a problem hiding this comment.
This is much better!
There was a problem hiding this comment.
...I had to skip RunWithCapturedR() here (and hence connection reading will not work) on 32-bit windows with RTools35...I'm slightly worried that I don't know why the feather reading doesn't work on old windows but the csv reading does (which uses RunWithCapturedR() and the IO thread pool but isn't skipped).
 westonpace
left a comment
westonpace
left a comment
There was a problem hiding this comment.
I think we can clean up those threads pretty easily. If the reader supports async we use it's async methods. If it doesn't support async then we spawn each call to the I/O thread pool.
r/src/csv.cpp
Outdated
There was a problem hiding this comment.
Luckily we have table_reader->ReadAsync() for just this purpose (I think)
r/src/feather.cpp
Outdated
There was a problem hiding this comment.
Unfortunately we do not have a reader->ReadAsync here. There is arrow::ipc::RecordBatchFileReader::ReadRecordBatchAsync but it is private at the moment and also, not exposed to arrow::feather at all.
So we could create a JIRA to expose that in C++. In the meantime, the "standard" way to solve "the underlying file reader doesn't have a true asynchronous implementation" is to do:
const auto& io_context = arrow::io::default_io_context();
auto fut = io_context.executor()->Submit(...);
That should work ok here.
r/src/io.cpp
Outdated
There was a problem hiding this comment.
Might be nice if there was a SafeCallIntoR<void>. It can be a bit of a pain because you can't create Result<void> but with some template specialization we could probably make a version that returns Status.
There was a problem hiding this comment.
I couldn't figure out how to get a template specialization to return a different type, but I implemented Status SafeCallIntoRVoid() {} that reads much better.
r/src/io.cpp
Outdated
There was a problem hiding this comment.
In the category of "probably not worth the effort & complexity but pedantic note for the purists", it might be slightly nicer if you overloaded the async versions of the arrow::io::FileInterface methods and changed the sync versions to call the async verisons (instead of vice-versa).
The only real gain is that you can avoid spinning up an I/O thread for no reason. I/O threads are supposed to block on long operations so it isn't really a problem but it is a slight bit of extra overhead that isn't necessary.
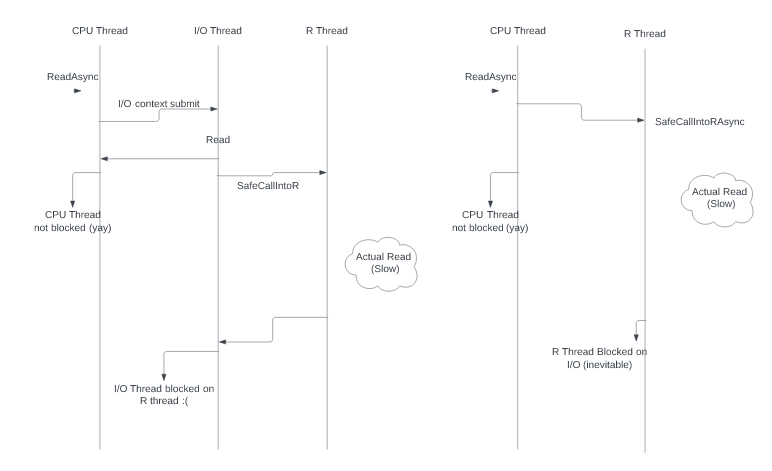
In fact, now that I draw this picture, I wonder if there might be some way to handle this by having an "R filesystem" whose I/O context's executor was the R main thread 🤔 . Not something we need to tackle right now.
There was a problem hiding this comment.
I spent a bit of time trying this but I don't feel that I know how to do it safely...for CloseAsync() it feels like we run the risk of the event loop ending before the file is actually closed; for ReadAsync() feels like it's better suited to something like "open a new connection, read from it, and close it" and I end up with nested futures that feel wrong to me. I'm happy to take another try at this if you think it's important for this usage.
There was a problem hiding this comment.
No need for another try. As I said, this is venturing into somewhat pedantic waters.
westonpace
left a comment
There was a problem hiding this comment.
I think this is probably ok how it is but I noticed you moved to ReadAsync for the CSV reader, then it looks like you had trouble with Windows, so you moved to submitting a call to the I/O executor, then it looks like you still had trouble with Windows and so disabled this on old Windows. Can you move back to ReadAsync? Or is there still trouble with Windows in that situation?
Co-authored-by: Weston Pace <[email protected]>
25ce363 to
4acdbf4
Compare
|
@github-actions crossbow submit test-r-versions |
For the CSV reader,
The next Windows trouble was with the Feather reader, which crashed on 32-bit Windows using R 3.6. We also don't build with dataset on that platform, perhaps for a similar reason. We had an internal There was a crash on R 3.4 (ARROW-16201)...I added a small fix here to make sure that's an error and not a crash (we don't have to support R 3.4 as of tomorrow's release of R 4.2 but it was a fast fix). |
|
Revision: 76ae1ab Submitted crossbow builds: ursacomputing/crossbow @ actions-1899
|
|
Got it, makes sense. Thanks for the info. Let's stick with what you have then. |
|
segfault on R 3.4: |
|
@github-actions crossbow submit test-r-versions |
|
Revision: 13ddd20 Submitted crossbow builds: ursacomputing/crossbow @ actions-1907
|
|
@github-actions crossbow submit test-r-versions |
e8dec37 to
82e6b6d
Compare
|
Revision: 82e6b6d Submitted crossbow builds: ursacomputing/crossbow @ actions-1909
|
|
@jonkeane build failures seem unrelated right? |
|
Benchmark runs are scheduled for baseline = c16bbe1 and contender = 6cf344b. 6cf344b is a master commit associated with this PR. Results will be available as each benchmark for each run completes. |
This is a PR to support arbitrary R "connection" objects as Input and Output streams. In particular, this adds support for sockets (ARROW-4512), URLs, and some other IO operations that are implemented as R connections (e.g., in the archive package). The gist of it is that you should be able to do this:
There are two serious issues that prevent this PR from being useful yet. First, it uses functions that R considers "non-API" functions from the C API.
We can get around this by calling back into R (in the same way this PR implements
Tell()andClose()). We could also go all out and implement the other half (exposingInputStream/OutputStreams as R connections) and ask for an exemption (at least one R package, curl, does this). The archive package seems to expose connections without a NOTE on the CRAN check page, so perhaps there is also a workaround.Second, we get a crash when passing the input stream to most functions. I think this is because the
Read()method is getting called from another thread but it also could be an error in my implementation. If the issue is threading, we would have to arrange a way to queue jobs for the R main thread (e.g., how the later package does it) and a way to ping it occasionally to fetch the results. This is complicated but might be useful for other reasons (supporting evaluation of R functions in more places). It also might be more work than it's worth.