This model is a lightweight face mask detection model. Based on ssd,the backbone is Mobilenet and RFB.
- Tensorflow 2.1
- Trainging and Inference
- Precision with mAP
- Eager mode training with
tf.GradientTape - Network function with
tf.keras - Dataset prepocessing with
tf.data.TFRecordDataset
├── assets
│ ├── 1_Handshaking_Handshaking_1_71.jpg
│ ├── out_1_Handshaking_Handshaking_1_71.jpg
│ ├── out_test_00002330.jpg
│ └── test_00002330.jpg
├── checkpoints
│ └── weights_epoch_100.h5
├── components
│ ├── config.py
│ ├── __init__.py
│ ├── kmeans.py
│ ├── prior_box.py
│ └── utils.py
├── dataset
│ ├── check_dataset.py
│ ├── tf_dataset_preprocess.py
│ ├── train_mask.tfrecord
│ ├── trainval_mask.tfrecord
│ ├── val_mask.tfrecord
│ ├── voc_to_tfrecord.py
├── inference.py
├── logs
│ └── train
├── mAP
│ ├── compute_mAP.py
│ ├── detection-results
│ ├── detect.py
│ ├── ground-truth
│ ├── __init__.py
│ ├── map-results
│ └── README.md
├── Maskdata
│ ├── Annotations
│ ├── ImageSets
│ └── Main
│ │ ├── train.txt
│ │ ├── trainval.txt
│ │ └── val.txt
│ └── JPEGImages
├── network
│ ├── __init__.py
│ ├── losses.py
│ ├── model.py
│ ├── net.py
│ ├── network.py
├── README.md
└── train.py
└── requirements.txtCreate a new python virtual environment by Anaconda ,pip install -r requirements.txt
-
Face Mask Data
Source data from AIZOOTech , which is a great job.
I checked and corrected some error to apply my own training network according to the voc dataset format. You can download it here:
- Baidu code:44pl
- GoogleDrive
-
Data Processing
-
Download the mask data images
-
Convert the training images and annotations to tfrecord file with the the script bellow.
python dataset/voc_to_tfrecord.py --dataset_path Maskdata/ --output_file dataset/train_mask.tfrecord --split train
you can change the --split parameters to 'val' to get the validation tfrecord, Please modify the inside setting
voc_to_tfrecord.pyfor different situations.
-
-
Check tfrecord dataloader by run
python dataset/check_dataset.py.
-
Modify your configuration in
components/config.py.You can get the anchors by run
python components/kmeans.py -
Train the model by run
python train.py.
-
Run on video
python inference.py --model_path checkpoints/ --camera True or python inference.py --model_path checkpoints/*.h5 --camera True -
Detect on Image
python inference.py --model_path checkpoints/ --img_path assert/1_Handshaking_Handshaking_1_71.jpg

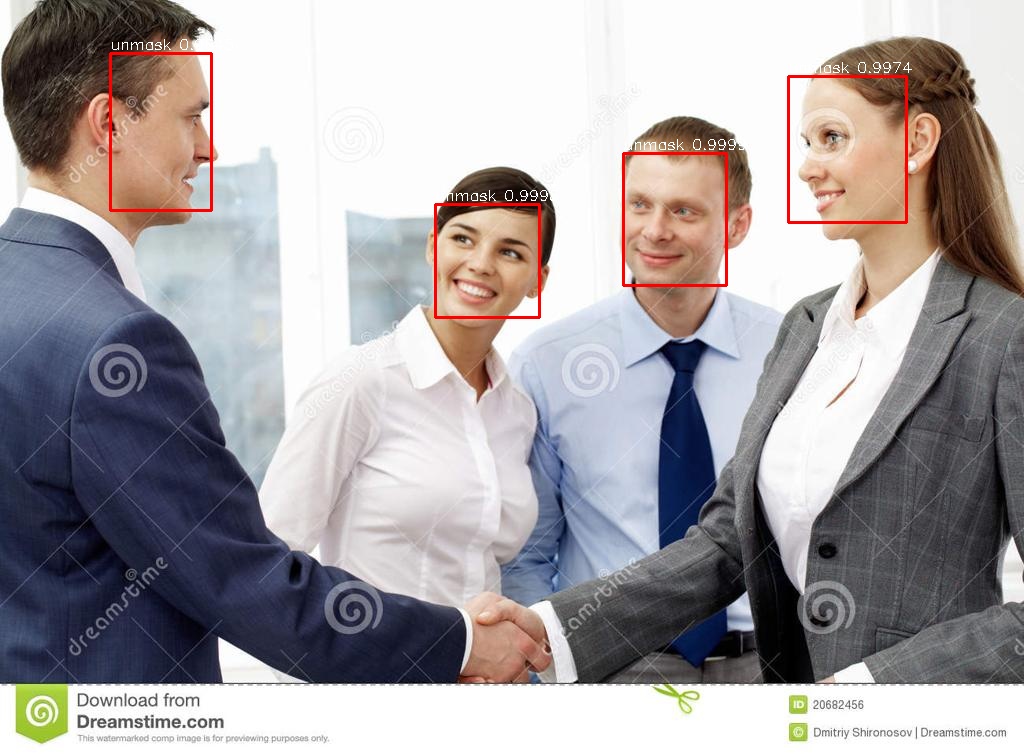
-
Convert xml to txt file on
mAP/ground truth, predicting the bbox and class onmAP/detection-results.python mAP/detect.py --model_path checkpoints/ --dataset_path Maskdata/ --split val python mAP/compute_mAP.py
something refer to k210-camera-project.