SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO V1又有明显的mAP优势。本开源是基于PaddlePaddle实现的SSD,参考了PaddlePaddle下的models的ssd ,包括MobileNetSSD,MobileNetV2SSD,VGGSSD,ResNetSSD。使用的是VOC格式数据集,同时提供了预训练模型和VOC数据的预测模型。
- 将图像数据集存放在
dataset/images目录下,将标注数据存放在dataset/annotations目录下。 - 执行
create_data_list.py程序生成数据列表。 - 在下面的表格中下载预训练模型,解压到
pretrained目录下。 - 修改
config.py参数,其中最重要的是class_num、use_model、pretrained_model。class_num是分类数量加上背景一类。use_model是指使用的模型,分别有resnet_ssd、mobilenet_v2_ssd、mobilenet_v1_ssd、vgg_ssd四种选择。pretrained_model是预训练模型的路径。 - 执行
train.py程序开始训练,每训练一轮都会更新保存的模型,训练过程中可以随时停止训练。 - 执行
infer.py预测图像,预测模型的路径在config.py配置文件中查找。

SSD全称Single Shot MultiBox Detector,是2016年提出的一种one-stage目标检测算法,相比two-stage目标检测算法的Faster R-CNN来说,其特点是一步到位,速度相对较快。 SSD有以下几个特点:
- 将bounding box的输出空间离散化为一系列不同纵横比的default box, 并能够调整box更好地匹配物体的形状。
- 将多个不同分辨率的feature map上的预测结果结合,解决了物体不同大小的问题。
- 模型结构简单,SSD模型把全部的计算都放在一个网络模型上,大体上可以分为两部分,图像特征提取网络和分类检测网络。
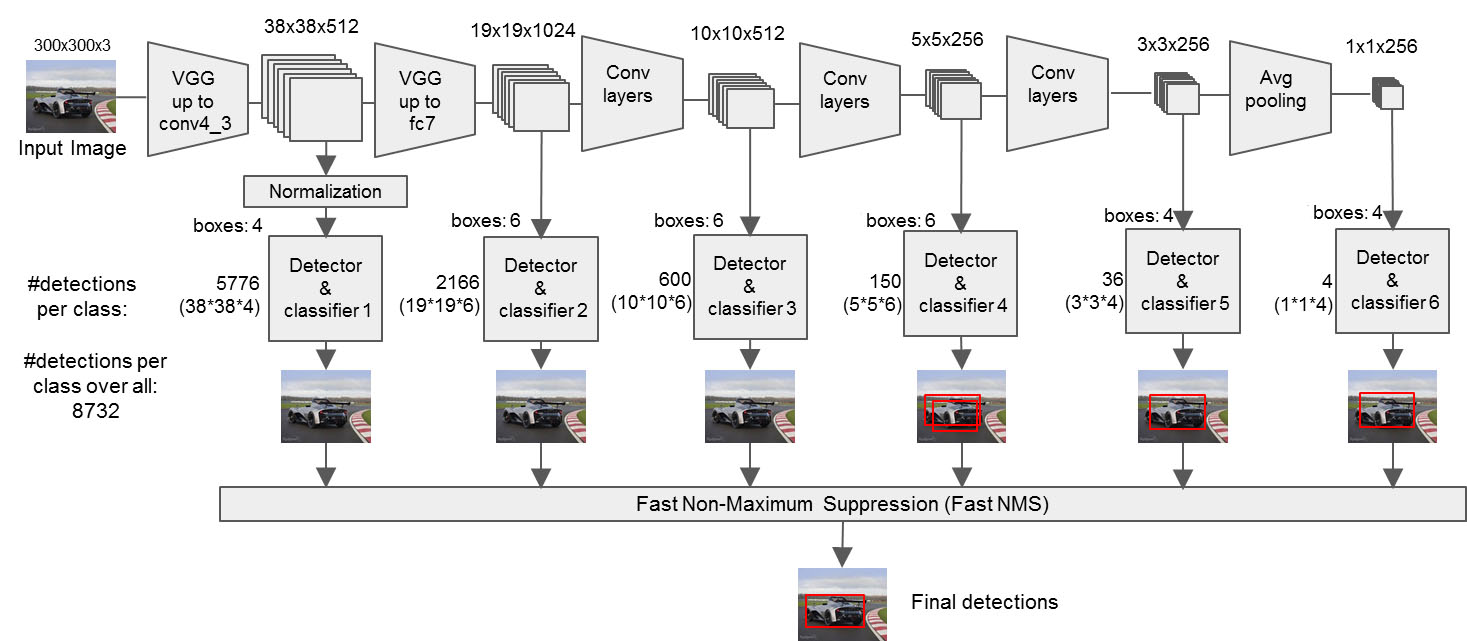
以下是SSD的结构图,在原论文中主干网络为VGG16,后面接着6个卷积层,用于提取出6个不同尺度的feature map,这样可以提取出不同大小的bbox,以检测到不同大小的目标对象。其中主干网络可以替换成其他的卷积网络,所以SSD也产生了几种衍生版,例如MobileNetV2 SSD、ResNet50 SSD等等。生成的6个feature map都输入到分类检测网络中,分类检测网络分别对这6个feature map依次预测的,这个分类检测网络可以使用PaddlePaddle的fluid.layers.multi_box_head()接口实现。

针对6个feature map的更详细图如下。
{kind=link}
以下是按照原论文的模型参数搭建的网络模型,在各个衍生版参数设置也有所变动。如下的主干网络是使用VGG16,使用PaddlePaddle实现的代码片段如下。
conv1 = self.conv_block(self.img, 64, 2)
conv2 = self.conv_block(conv1, 128, 2)
conv3 = self.conv_block(conv2, 256, 3)6个feature map的实现代码如下,按照论文中的,feature map1的shape为38*38*512,feature map2的shape为19*19*1024,feature map3的shape为10*10*512,feature map4的shape为5*5*256,feature map5的shape为3*3*256,feature map6的shape为1*1*256,
# 38x38
module11 = self.conv_bn(conv3, 3, 512, 1, 1)
tmp = self.conv_block(module11, 1024, 5)
# 19x19
module13 = fluid.layers.conv2d(tmp, 1024, 1)
# 10x10
module14 = self.extra_block(module13, 256, 512, 1)
# 5x5
module15 = self.extra_block(module14, 128, 256, 1)
# 3x3
module16 = self.extra_block(module15, 128, 256, 1)
# 1x1
module17 = fluid.layers.pool2d(input=module16, pool_type='avg', global_pooling=True)最后这个就是分类检测模型,在PaddlePaddle上只需一个接口即可完成,在参数inputs参数中把6个feature map的输出都作为参数输入。按照论文中设置先验框的长度和base_size的最小比率min_ratio为20%,先验框的长度和base_size的最大比率max_ratio为90%,其中base_size是输入图片的大小。
mbox_locs, mbox_confs, box, box_var = fluid.layers.multi_box_head(
inputs=[module11, module13, module14, module15, module16, module17],
image=self.img,
num_classes=self.num_classes,
min_ratio=20,
max_ratio=90,
min_sizes=[60.0, 105.0, 150.0, 195.0, 240.0, 285.0],
max_sizes=[[], 150.0, 195.0, 240.0, 285.0, 300.0],
aspect_ratios=[[2.], [2., 3.], [2., 3.], [2., 3.], [2., 3.], [2., 3.]],
base_size=self.img_shape[2],
offset=0.5,
flip=True)min_sizes和max_sizes分别是每层提取的先验框的最小长度和最大长度,当输入个数len(inputs) > 2,并且min_size和max_size为None时,通过baze_size, min_ratio和max_ratio来计算出min_size和max_size,计算公式如下:
min_sizes = []
max_sizes = []
step = int(math.floor(((max_ratio - min_ratio)) / (num_layer - 2)))
for ratio in six.moves.range(min_ratio, max_ratio + 1, step):
min_sizes.append(base_size * ratio / 100.)
max_sizes.append(base_size * (ratio + step) / 100.)
min_sizes = [base_size * .10] + min_sizes
max_sizes = [base_size * .20] + max_sizes同样PaddlePaddle也提供了SSD的损失函数,使用的接口时fluid.layers.ssd_loss()。通过给定位置偏移预测,置信度预测,候选框和真实框标签,返回的损失是或回归损失和分类损失的加权和。
loss = fluid.layers.ssd_loss(locs, confs, gt_box, gt_label, box, box_var)
loss = fluid.layers.reduce_sum(loss)本项目中最重要的是config.py配置文件,这里包含了所有的训练配置信息,开发者在使用本项目训练自己的数据集时,一定要留意该配置是否符合当前的数据集和训练环境,以下笔者针对几个重要的参数进行解析。
image_shape输入训练的现状,默认是[3, 300, 300],也可以设置大小为512*512。batch_size训练数据的batch大小,根据自己的硬件环境修改,充分使用硬件资源。epoc_num训练的轮数,每一轮都会保存预测模型和训练的参数。lr初始化学习率。class_num分类的数量,通常还要加上背景一类,例如VOC类别是20类,那该值为21。use_model使用的SSD的模型,分别有resnet_ssd、mobilenet_v2_ssd、mobilenet_v1_ssd、vgg_ssd,更加自己的需求选择不同的模型,如何开发者是希望嵌入到移动设备的,那么可以考虑mobilenet_v2_ssd、mobilenet_v1_ssd。如何开发者希望有更好的识别准确率,可以使用resnet_ssd。label_file分类的标签对应的名称,由create_data_list.py生成,通常不需要修改。train_list训练数据的数据列表,每一行数据对应的是他们的图片和标注文件的路径,,由create_data_list.py生成,通常不需要修改。test_list测试数据的数据列表,每一行数据对应的是他们的图片和标注文件的路径,,由create_data_list.py生成,通常不需要修改。persistables_model_path训练过程中保存的模型参数,可以用于再次训练,恢复之前的训练。infer_model_path训练过程中保存的预测模型,可以用于之后的预测图像,不需要再依赖模型代码。pretrained_model预训练模型路径,预训练模型文件在上面模型下载中下载,需要指定解压的文件夹路径。use_gpu是否使用GPU进行训练。use_multiprocess是否使用多线程读取数据,在Windows系统下不能使用,否则会出错。
create_data_list.py代码是生成数据类别和数据标签的,本项目目前仅支持VOC标注格式的数据。如果开发者把数据集分为images和annotations,并且存放在dataset/images,dataset/annotations目录下,还有他们的文件名是一样的,那么这个代码是不需要修改的。如果开发者的数据格式有差别,请修改代码生成如下的数据列表,每一行第一个为图像的路径,第二个是VOC格式的标注文件,他们中间有制表符\t分开。
dataset/images/00001.jpg dataset/annotations/00001.xml
dataset/images/00002.jpg dataset/annotations/00002.xml
train.py为训练代码,基本上的训练配置都在config.py。
infer.py为预测代码,这代码可以单独运行,不再需要网络模型代码。预测是可以在图像上画框和类别名称并显示。
label_file是标签文件,由create_data_list.py生成,在画框的时候显示类别名称。score_threshold为预测得分阈值,小于该阈值的结果不显示。infer_model_path指定预测模型的路径。
utils/reader.py是将图像和标签数据生成训练和测试数据的生成器,图像预处理和生成SSD模型的预选框也会在这个过程完成。但是生成SSD模型的预选框是调用了utils/image_util.py完成,这个代码包含了生成预选框和数据增强,增强方式请仔细阅读该代码。
四种模型的代码存放在nets文件夹下,包括mobilenet_v1_ssd.py,mobilenet_v2_ssd.py,vgg_ssd.py,resnet_ssd.py模型,模型代码介绍请查看上面的SSD模型介绍。