- 王文琦:负责算法
FPSE的实现与仓库维护 - 陈顾骏:负责算法
GauGAN的实现与报告撰写
截止到2022年6月29日(A榜封榜前1天),我们采用的算法在
我们在训练集上实现的效果如下(左侧为原图像,右侧为生成图像):

我们在测试集上实现的效果如下(左侧为语义标签图,右侧为生成图像):

我们主要使用

在

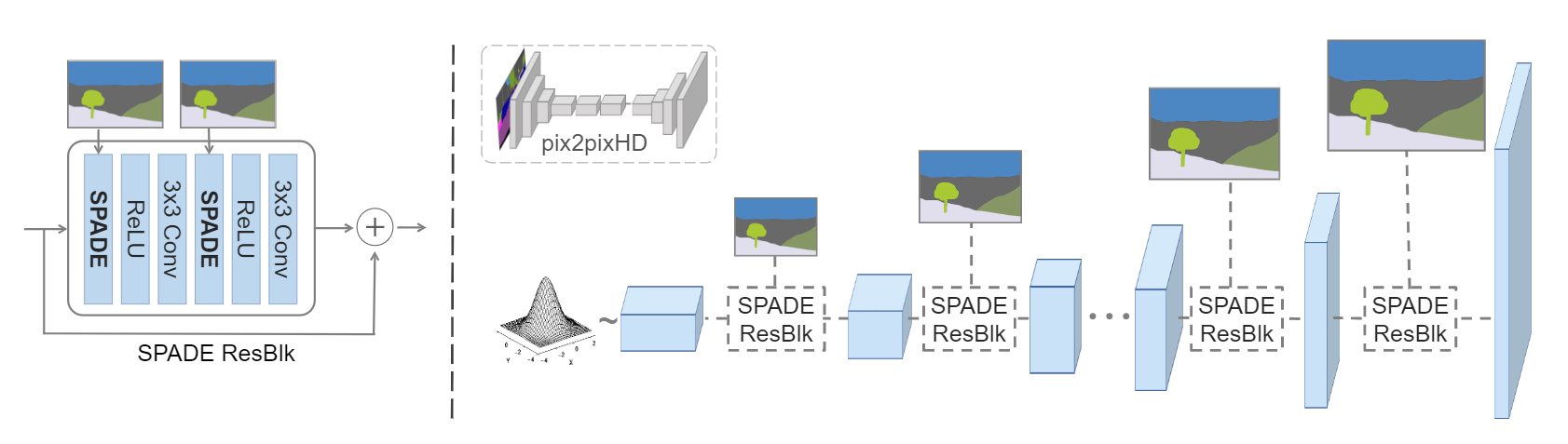
网络结构方面,生成器采用堆叠多个

判别器和

从


上图是采取的训练损失函数。其余的鉴别器网络基本与
本项目主要运行在单张卡的 3090 上,200个 epoch 的训练周期一般为 4~5 天。
- ubuntu 20.04 LTS
- python >= 3.7
- jittor >= 1.3.0
可以进入任意目录执行以下命令安装依赖( jittor 框架请遵循官网给出的安装指导)
pip install -r requirements.txt
数据目录我们没有上传,请遵循赛事公告进行下载。在本次比赛中,我们没有采取更多的数据预处理操作,裁剪、正则化等操作在项目代码中已经有所体现。
预训练模型我们采用的是 Jittor 框架自带的 vgg19 模型,无需额外下载,在代码运行的过程中会载入到内存里。
在单卡上训练,只需执行以下命令(针对
python train.py \
--name "your project name" \
--datasetmode custom \
--label_dir "your train labels directory" \
--image_dir "your train images directory" \
--label_nc 29 \
--batchSize "your batchsize" \
--no_instance \
--use_vae因为受平台算力的限制 (单卡3090),$FPSE$ 算法需要更高的参数量,也就需要更大的GPU内存。在实际操作中,$FPSE$ 只能使用 batchsize = 1 的梯度下降,导致模型训练效果较佳,但是泛化性能很差;相比之下,$SPADE$ 需要的模型参数量更小,可以使用 batchsize = 4 的梯度下降,相应地在测试集上的效果也就更好。我们最终是选择了$SPADE$ 算法的结果上交比赛平台。
在单卡上进行测试,只需执行以下命令(针对
python test.py \
--name "your project name (the same as the train project)" \
--datasetmode custom \
--label_dir "your test labels directory" \
--label_nc 29 \
--no_instance \
--use_vae我们将两篇论文的 pytorch 版本的源代码,迁移到了 Jittor 框架当中。其中借鉴了开源社区 Spectral Normalization 的代码,以及重度参考了两篇论文的官方开源代码:SPADE ,FPSE 。