[data] feat: TransferQueue - An asynchronous streaming data management system#3649
Merged
wuxibin89 merged 52 commits intoverl-project:mainfrom Oct 21, 2025
Merged
Conversation
* Support controller in TransferQueue * Fix import * Fix comments --------- Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com>
Added copyright and licensing information to the controller.py file.
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
* update client docstring Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix n_sample related problems Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
* Add metadata.py and test_simple_storage_unit.py * Add copyright and license information to test_simple_storage_unit.py * Apply suggestion from @Copilot Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> --------- Co-authored-by: Han Zhenyu 韩振宇 <o0shower0o@outlook.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com>
Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
* Origin recipe * Integrate TransferQueue with Ray Trainer * Fix codecheck * Fix codecheck * Fix codecheck * Fix codecheck * Fix * Fix codecheck --------- Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
* fix chinese comments & add TODO * provide general DataProto<->BatchMeta decorator Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * optimize code Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> * fix Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com>
a50460e to
14ad39e
Compare
wuxibin89
reviewed
Oct 17, 2025
wuxibin89
reviewed
Oct 17, 2025
| global _TRANSFER_QUEUE_CLIENT | ||
| global _VAL_TRANSFER_QUEUE_CLIENT | ||
| if "val" in client_id: | ||
| _VAL_TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_infos, storage_infos) |
Collaborator
There was a problem hiding this comment.
Why we have a separate client for val? One client should be used for both train and val.
wuxibin89
reviewed
Oct 17, 2025
wuxibin89
reviewed
Oct 17, 2025
Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com>
aacf49d to
df0c720
Compare
5ef317d to
8fcf939
Compare
8fcf939 to
20d0f98
Compare
wuxibin89
approved these changes
Oct 21, 2025
wangboxiong320
pushed a commit
to wangboxiong320/verl
that referenced
this pull request
Nov 1, 2025
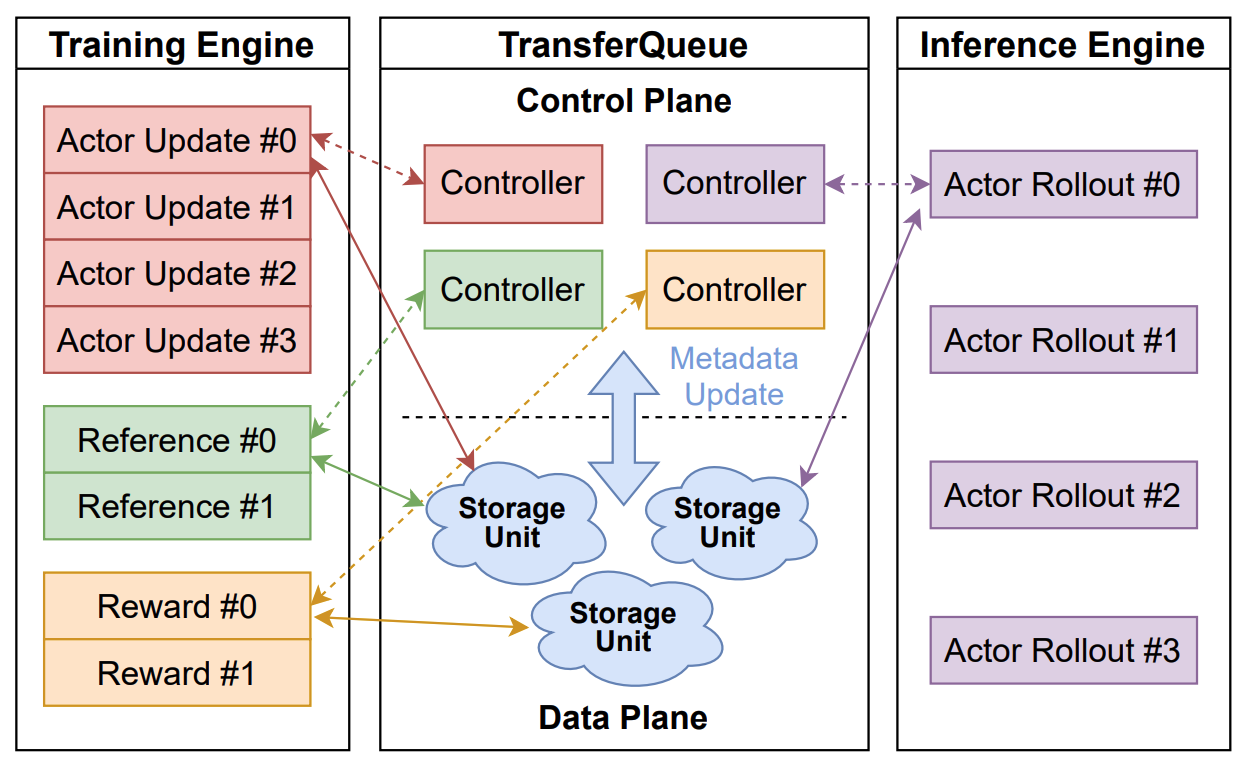
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system. 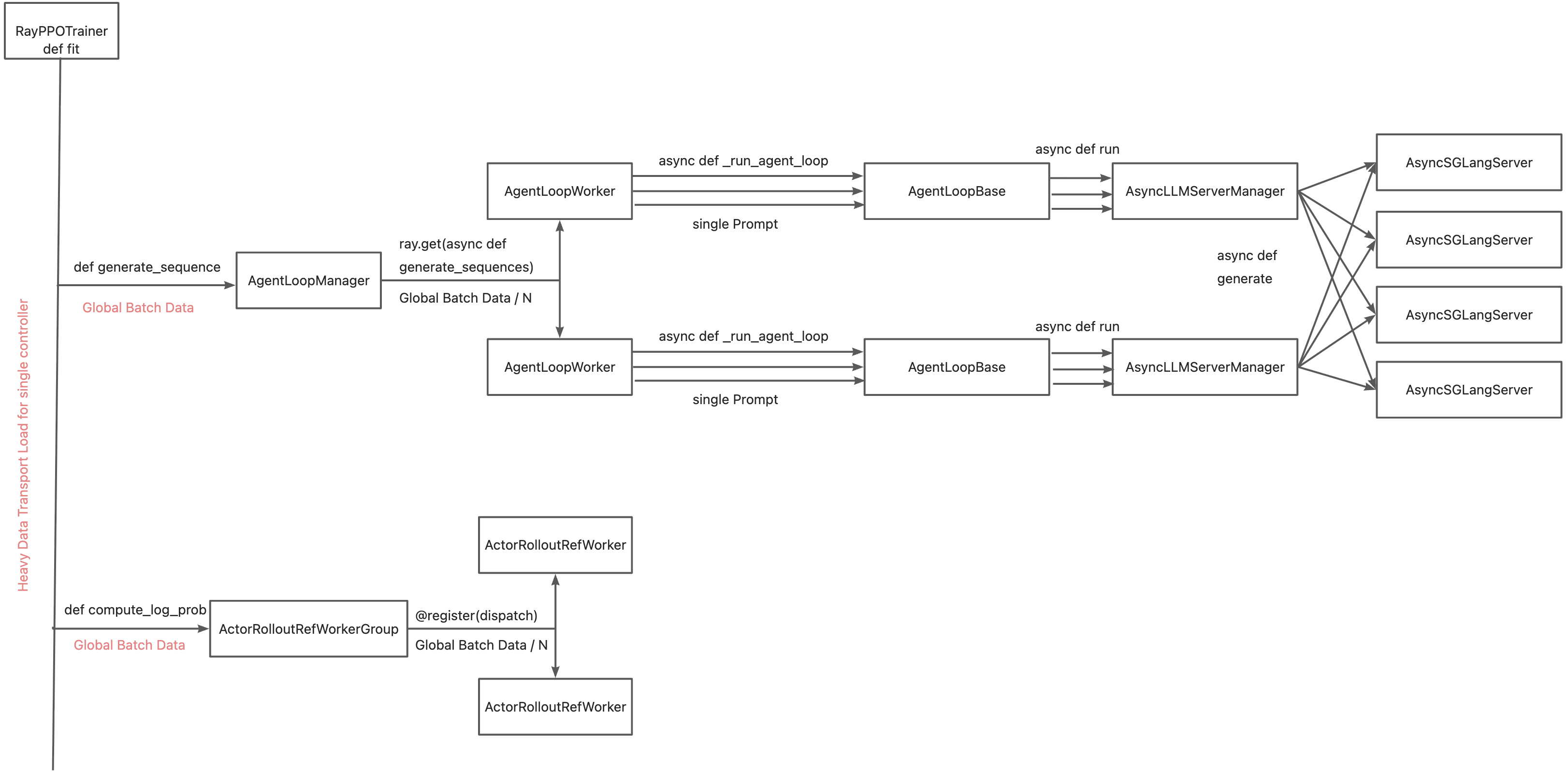 Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units 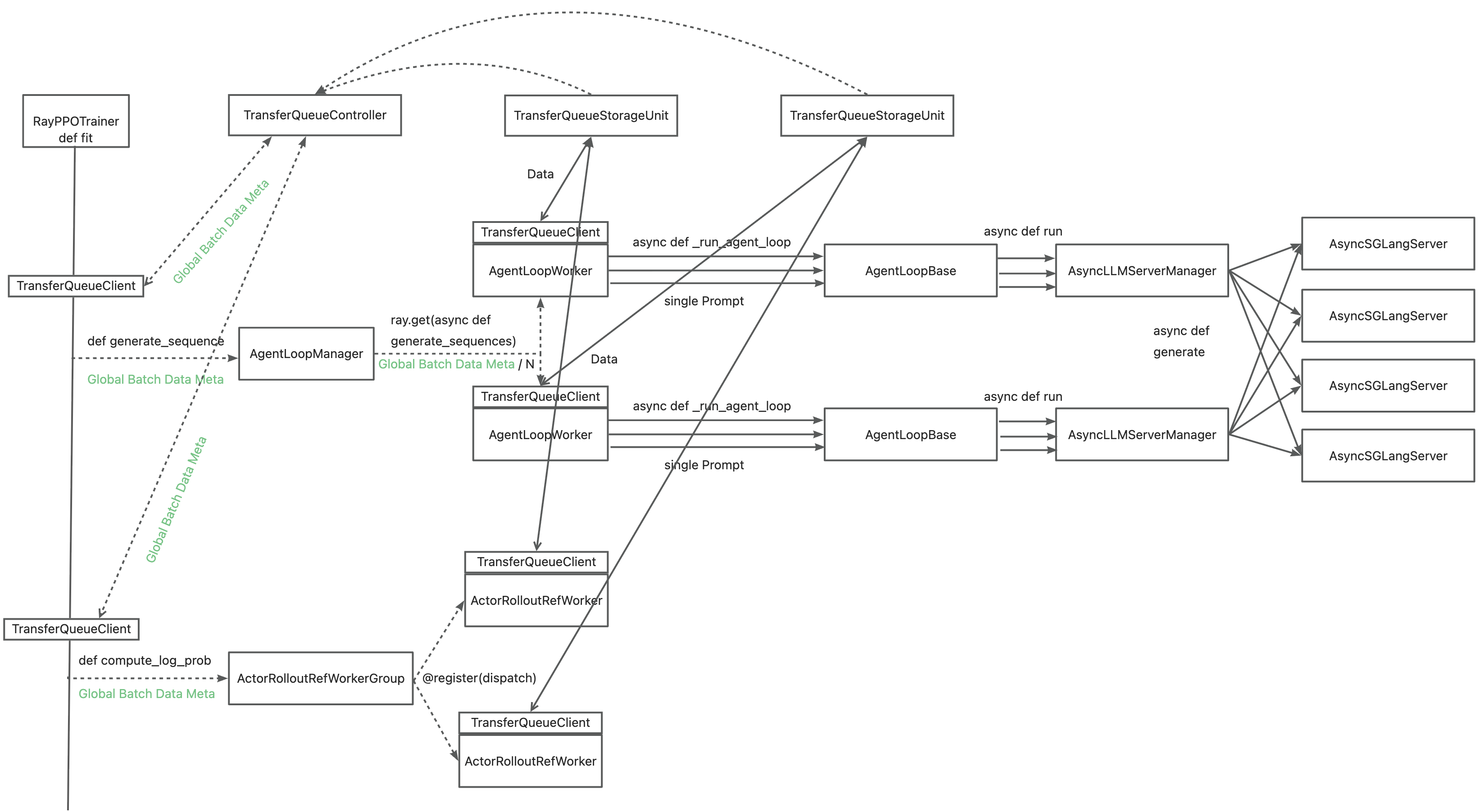 For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
{kind=link}
{kind=link}
{kind=link}
NenoL2001
pushed a commit
to NenoL2001/verl
that referenced
this pull request
Nov 3, 2025
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
chenjiaoAngel
added a commit
to chenjiaoAngel/verl
that referenced
this pull request
Nov 14, 2025
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
7 tasks
chenhaiq
pushed a commit
to The-Hierophant/verl-1
that referenced
this pull request
Nov 18, 2025
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
NenoL2001
pushed a commit
to NenoL2001/verl
that referenced
this pull request
Nov 26, 2025
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
NenoL2001
pushed a commit
to NenoL2001/verl
that referenced
this pull request
Nov 26, 2025
…t system (verl-project#3649) This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
TimurTaepov
pushed a commit
to giorgossideris/verl
that referenced
this pull request
Dec 20, 2025
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
vyomakesh0728
added a commit
to vyomakesh0728/verl
that referenced
this pull request
Jan 22, 2026
…t system (verl-project#3649) ### What does this PR do? This PR introduces the [**TransferQueue**](https://github.com/TransferQueue/TransferQueue) data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (verl-project#2662). **This PR adds TransferQueue as a git submodule into `verl/experimental/transfer_queue`. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.** <p align="center"> <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> </p> **TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).** The system will introduce the following core components: - **TransferQueueClient**: Deployed on each `Worker`, manages the communication with TransferQueue system via simple put/get semantics. - **TransferQueueController**: Centralized dataflow scheduler tracking the production and consumption status of training samples. - **TransferQueueStorage**: Distributed storage units that holds the actual experience data. The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.  Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by - Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) - Accelerating data transfer by TransferQueue's distributed storage units  For `WorkerGroup` class, we hide the above translation process by decorator. For `AgentLoop` related class, we explicitely do the adaption in `AgentLoopBase`. ### Checklist Before Starting - [x] Search for similar PRs. Paste at least one query link here: ... - [x] Format the PR title as `[{modules}] {type}: {description}` (This will be checked by the CI) - `{modules}` include `fsdp`, `megatron`, `sglang`, `vllm`, `rollout`, `trainer`, `ci`, `training_utils`, `recipe`, `hardware`, `deployment`, `ray`, `worker`, `single_controller`, `misc`, `perf`, `model`, `algo`, `env`, `tool`, `ckpt`, `doc`, `data` - If this PR involves multiple modules, separate them with `,` like `[megatron, fsdp, doc]` - `{type}` is in `feat`, `fix`, `refactor`, `chore`, `test` - If this PR breaks any API (CLI arguments, config, function signature, etc.), add `[BREAKING]` to the beginning of the title. - Example: `[BREAKING][fsdp, megatron] feat: dynamic batching` ### Test We've validated TransferQueue functionality through - Unit test of (Async)TransferQueueClient, TransferQueueController, and TransferQueueSimpleUnit - End-to-end demo that mimics the usage in verl ### API and Usage Example The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. Core client interfaces: - (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta - (async_)get_data(metadata:BatchMeta) -> TensorDict - (async_)put(data:TensorDict, metadata:BatchMeta, global_step) - (async_)clear(global_step: int) You may refer to the example here, where we mimics the verl usage in both async & sync scenarios: https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case. --- **Please use `pip install ".[transferqueue]"` to install TransferQueue to verl.** Then you can try our recipe as follows, which is adapted from `run_qwen3-8b.sh` with async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#) ```bash # Tested successfully on the hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0 image. # It outperforms the Qwen2 7B base model by two percentage points on the test set of GSM8K. set -x MODEL_PATH="/home/xxx/models/Qwen3-8B" TRAIN_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" TEST_FILE="/home/xxx/data/DAPO-Math-17k/data/dapo-math-17k.parquet" log_dir="./logs" mkdir -p ${log_dir} timestamp=$(date +"%Y%m%d%H%M%S") log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log" rollout_mode="async" rollout_name="sglang" # sglang or vllm if [ "$rollout_mode" = "async" ]; then export VLLM_USE_V1=1 return_raw_chat="True" fi python3 -m recipe.transfer_queue.main_ppo \ --config-name='transfer_queue_ppo_trainer' \ algorithm.adv_estimator=grpo \ data.train_files=${TRAIN_FILE} \ data.val_files=${TEST_FILE} \ data.return_raw_chat=$return_raw_chat \ data.train_batch_size=128 \ data.max_prompt_length=2048 \ data.max_response_length=8192 \ data.filter_overlong_prompts_workers=128 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=${MODEL_PATH} \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=32 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=True \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \ actor_rollout_ref.rollout.name=$rollout_name \ actor_rollout_ref.rollout.mode=$rollout_mode \ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger=console \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen3_8b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=1000 \ trainer.total_epochs=15 \ trainer.total_training_steps=50 \ trainer.val_before_train=False \ +trainer.num_global_batch=1 \ +trainer.num_data_storage_units=8 \ +trainer.num_data_controllers=8 \ 2>&1 | tee "$log_file" echo "Finished, log is saved in: $log_file" ``` Accuracy comparison: <img width="934" height="540" alt="image" src="https://github.com/user-attachments/assets/1edb7f35-9141-41cf-9202-ecf1df6a6c76" /> <img width="956" height="540" alt="image" src="https://github.com/user-attachments/assets/220102f0-b4ec-4f4d-b100-217fa02107f7" /> ### Design & Code Changes Refer to our [Paper](https://arxiv.org/abs/2507.01663), [RFC](verl-project#2662), and [Zhihu post](https://zhuanlan.zhihu.com/p/1930244241625449814) :) ### Checklist Before Submitting > [!IMPORTANT] > Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review. - [x] Read the [Contribute Guide](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md). - [x] Apply [pre-commit checks](https://github.com/volcengine/verl/blob/main/CONTRIBUTING.md#code-linting-and-formatting): `pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=always` - [x] Add / Update [the documentation](https://github.com/volcengine/verl/tree/main/docs). - [x] Add unit or end-to-end test(s) to [the CI workflow](https://github.com/volcengine/verl/tree/main/.github/workflows) to cover all the code. If not feasible, explain why: ... - [x] Once your PR is ready for CI, send a message in [the `ci-request` channel](https://verl-project.slack.com/archives/C091TCESWB1) in [the `verl` Slack workspace](https://join.slack.com/t/verl-project/shared_invite/zt-3855yhg8g-CTkqXu~hKojPCmo7k_yXTQ). (If not accessible, please try [the Feishu group (飞书群)](https://applink.larkoffice.com/client/chat/chatter/add_by_link?link_token=772jd4f1-cd91-441e-a820-498c6614126a).) --------- Signed-off-by: 0oshowero0 <o0shower0o@outlook.com> Signed-off-by: jianjunzhong <jianjunzhong@foxmail.com> Co-authored-by: FightingZhen <295632982@qq.com> Co-authored-by: LLLLxmmm <130739718+LLLLxmmm@users.noreply.github.com> Co-authored-by: liuximeng <13073314+liuximeng18772102439@user.noreply.gitee.com> Co-authored-by: Huazhong <hzji210@gmail.com> Co-authored-by: zhabuye <74179177+zhabuye@users.noreply.github.com> Co-authored-by: Jianjun Zhong <87791082+jianjunzhong@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: baymax591 <cbai@mail.nwpu.edu.cn>
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
8 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
What does this PR do?
This PR introduces the TransferQueue data management module to verl, aiming to accelerate experience data transfer and address performance bottlenecks in post-training systems. Detailed design rationale is available in our RFC (#2662).
This PR adds TransferQueue as a git dependence. Besides, we provide end-to-end scripts that integrate verl with TransferQueue.
TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows (in progress).
The system will introduce the following core components:
TransferQueueClient: Deployed on each
Worker, manages the communication with TransferQueue system via simple put/get semantics.TransferQueueController: Centralized dataflow scheduler tracking the production and consumption status of training samples.
TransferQueueStorage: Distributed storage units that holds the actual experience data.
The primary motivation for integrating TransferQueue to verl now is to alleviate the data transfer bottleneck of the single controller
RayPPOTrainer. Currently, allDataProtoobjects must be routed throughRayPPOTrainer, resulting in a single point bottleneck of the whole post-training system.Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by
DataProtowithBatchMeta(metadata) andTensorDict(actual data) structuresFor
WorkerGroupclass, we hide the above translation process by decorator. ForAgentLooprelated class, we explicitely do the adaption inAgentLoopBase.Checklist Before Starting
[{modules}] {type}: {description}(This will be checked by the CI){modules}includefsdp,megatron,sglang,vllm,rollout,trainer,ci,training_utils,recipe,hardware,deployment,ray,worker,single_controller,misc,perf,model,algo,env,tool,ckpt,doc,data,like[megatron, fsdp, doc]{type}is infeat,fix,refactor,chore,test[BREAKING]to the beginning of the title.[BREAKING][fsdp, megatron] feat: dynamic batchingTest
We've validated TransferQueue functionality through
API and Usage Example
The primary interaction points are
AsyncTransferQueueClientandTransferQueueClient, serving as the communication interface with the TransferQueue system.Core client interfaces:
You may refer to the example here, where we mimics the verl usage in both async & sync scenarios:
https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case.
Please use
pip install ".[transferqueue]"to install TransferQueue to verl.Then you can try our recipe as follows, which is adapted from
run_qwen3-8b.shwith async rollout mode enabled using sglang backend. For more recipes and the accuracy comparison, refer to [this doc].(https://www.yuque.com/haomingzi-lfse7/hlx5g0/bqm536cgc52kv2gk?singleDoc#)Accuracy comparison:


Design & Code Changes
Refer to our Paper, RFC, and Zhihu post :)
Checklist Before Submitting
Important
Please check all the following items before requesting a review, otherwise the reviewer might deprioritize this PR for review.
pre-commit install && pre-commit run --all-files --show-diff-on-failure --color=alwaysci-requestchannel in theverlSlack workspace. (If not accessible, please try the Feishu group (飞书群).)