Use unenforced constraint when building Iceberg stats#16244
Use unenforced constraint when building Iceberg stats#16244findepi merged 3 commits intotrinodb:masterfrom
Conversation
03af0e6 to
bf56373
Compare
plugin/trino-iceberg/src/main/java/io/trino/plugin/iceberg/TableStatisticsReader.java
Outdated
Show resolved
Hide resolved
a06ba3f to
6c6d3c6
Compare
There was a problem hiding this comment.
@findepi @raunaqmorarka is there a good way to tell if these changes are good or not?
There was a problem hiding this comment.
Sure, just run the benchmarks :)
6c6d3c6 to
3fd7d62
Compare
There was a problem hiding this comment.
Regarding this TODO (not related to current PR), the engine does provide the columns required for the query (various connectors save this in their ConnectorTableHandle after applyProjection). Do we try to parse all columns here or only the columns accessed by the query ?
There was a problem hiding this comment.
I'm not a 100% sure, but I think this might lead to underestimation by the CBO.
Even though unenforcedConstraint was used to prune statistics here, that filter is going to stay on top of the scan for evaluation. FilterStatsCalculator will estimate it like any other predicate and further reduce the already filtered stats. Please check if this is the case.
cc: @findepi @sopel39
There was a problem hiding this comment.
@raunaqmorarka the code here seems correct to me.
Note that the logic here should be -- and is -- aligned with how we select files for reading later on
There was a problem hiding this comment.
I get that the logic here matches with file pruning in splits generation. My concern was about something else.
E.g.: Let's say before this change FilterStatsCalculator would get column stats based on 10 file's stats and uses that to estimate a predicate. After this change FilterStatsCalculator will estimate the same predicate but with column stats based on a subset of file's stats. The domain of the column stats (min/max, ndv) would be narrower this time.
This is still correct though as the row count will also be smaller and we assume uniform distribution of values.
It does change the estimates when actual distribution of values across files is non-uniform, maybe this is why a couple of TPC queries plans also changed.
There was a problem hiding this comment.
I see your concern. Yes, this may result in different stats eventually calculated by FilterStatsCalculator.
Yet, this is IMO the correct thing to do. If the connector is going to return rows from 10 files, it should indicate row count coming from 100s of files.
There was a problem hiding this comment.
| private TableStatisticsReader() | |
| { } | |
| private TableStatisticsReader() {} |
There was a problem hiding this comment.
The class became utility class now
- i have
Utility class 'TableStatisticsReader' is not 'final'warning on the class declaration - move the constructor declaration as the first entry in the class, since this isn't real constructor anymore.
There was a problem hiding this comment.
in first commit we have two variables meaning one same thing ...
There was a problem hiding this comment.
... and in the second commit the enforcedPredicate is ill-named, because it's not actually enforced
- let's call it
effectivePredicate. - let's introduce the variable in the second commit
There was a problem hiding this comment.
@raunaqmorarka the code here seems correct to me.
Note that the logic here should be -- and is -- aligned with how we select files for reading later on
|
"Use unenforced constraint when building Iceberg stats" title doesn't tell the whole story, leading to quesations like #16244 (comment). What would be a better title for the change? "Return more accurate stats from Iceberg when some filters not fully enforced"? |
3fd7d62 to
c6e9516
Compare
There was a problem hiding this comment.
let's capture some info from #16244 (comment) conversation
like that this matches split gen
There was a problem hiding this comment.
I tried to sum it up in the commit message, let me know if theres anything missing.
There was a problem hiding this comment.
I tried to sum it up in the commit message,
code comments are easier to notice (and serve slightly different purpose)
There was a problem hiding this comment.
Added a code comment as well
|
Here's q21 of tpch before and after the change. Doesn't seem to have made much of a difference:
|


|
And q09: |
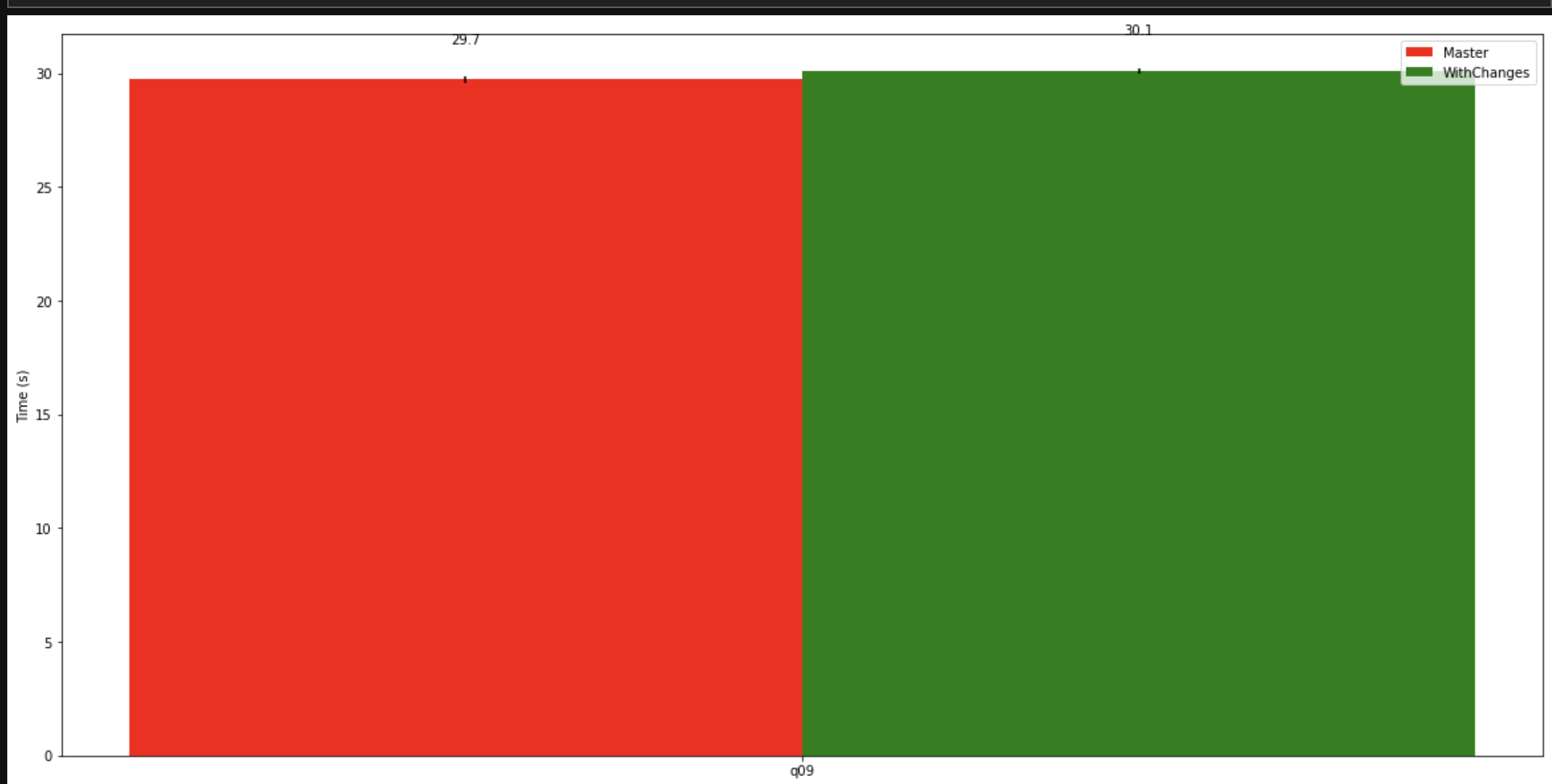

The unenforced component of the table predicate is still used to prune data files when generating Iceberg splits. The same can be done when scanning the manifest to generate table statistics.
c6e9516 to
c4c8bff
Compare
|
Not sure what's wrong with Maven Checks, but it passed the code checks part. |
214e7cc to
614155a
Compare
|
@findepi build is green ✔️ |
@colebow this should be reworded sth like "improve query planning performance" |
Description
Fixes: #16239
Additional context and related issues
Iceberg files can be pruned using both the enforced constraint and the unenforced constraint when building table statistics.
Release notes
( ) This is not user-visible or docs only and no release notes are required.
( ) Release notes are required, please propose a release note for me.
(x) Release notes are required, with the following suggested text: