

Created by https://transcription.stream with special thanks to MahmoudAshraf97 and his work on whisper-diarization, and to jmorganca for Ollama and its amazing simplicity in use.
Transcription Stream is a turnkey self-hosted diarization service that works completely offline. Out of the box it includes:
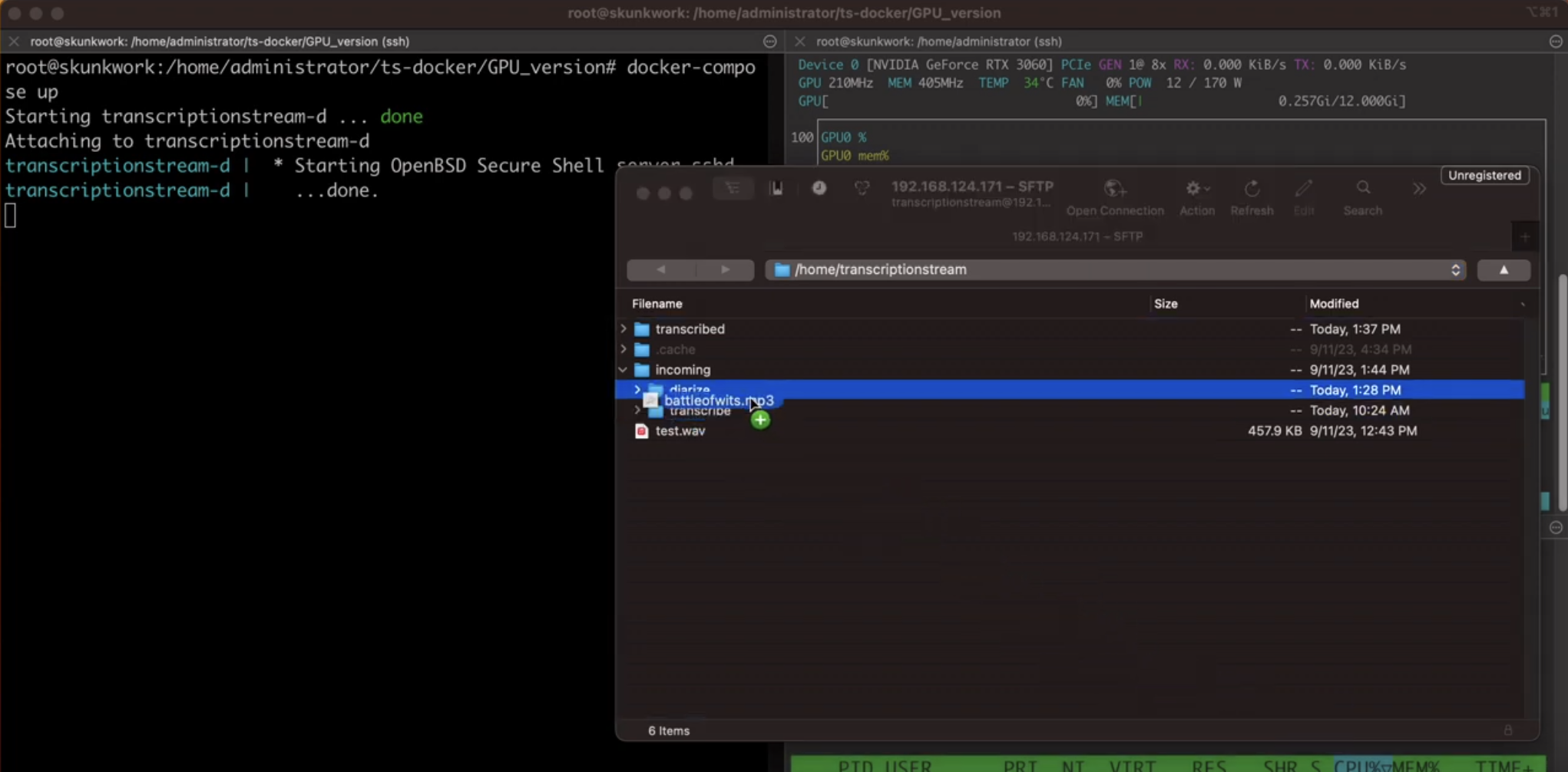
- drag and drop diarization and transcription via SSH
- a web interface for upload, review, and download of files
- summarization with Ollama and Mistral
- Meilisearch for full text search
A web interface and SSH drop zones make this simple to use and implement into your workflows. Ollama allows for a powerful toolset, limited only by your prompt skills, to perform complex operations on your transcriptions. Meiliesearch adds ridiculously fast full text search.
Use the web interface to upload, listen to, review, and download output files, or drop files via SSH into transcribe or diarize. Files are processed with output placed into a named and dated folder. Have a quick look at the install and ts-web walkthrough videos for a better idea.

prompt_text = f"""
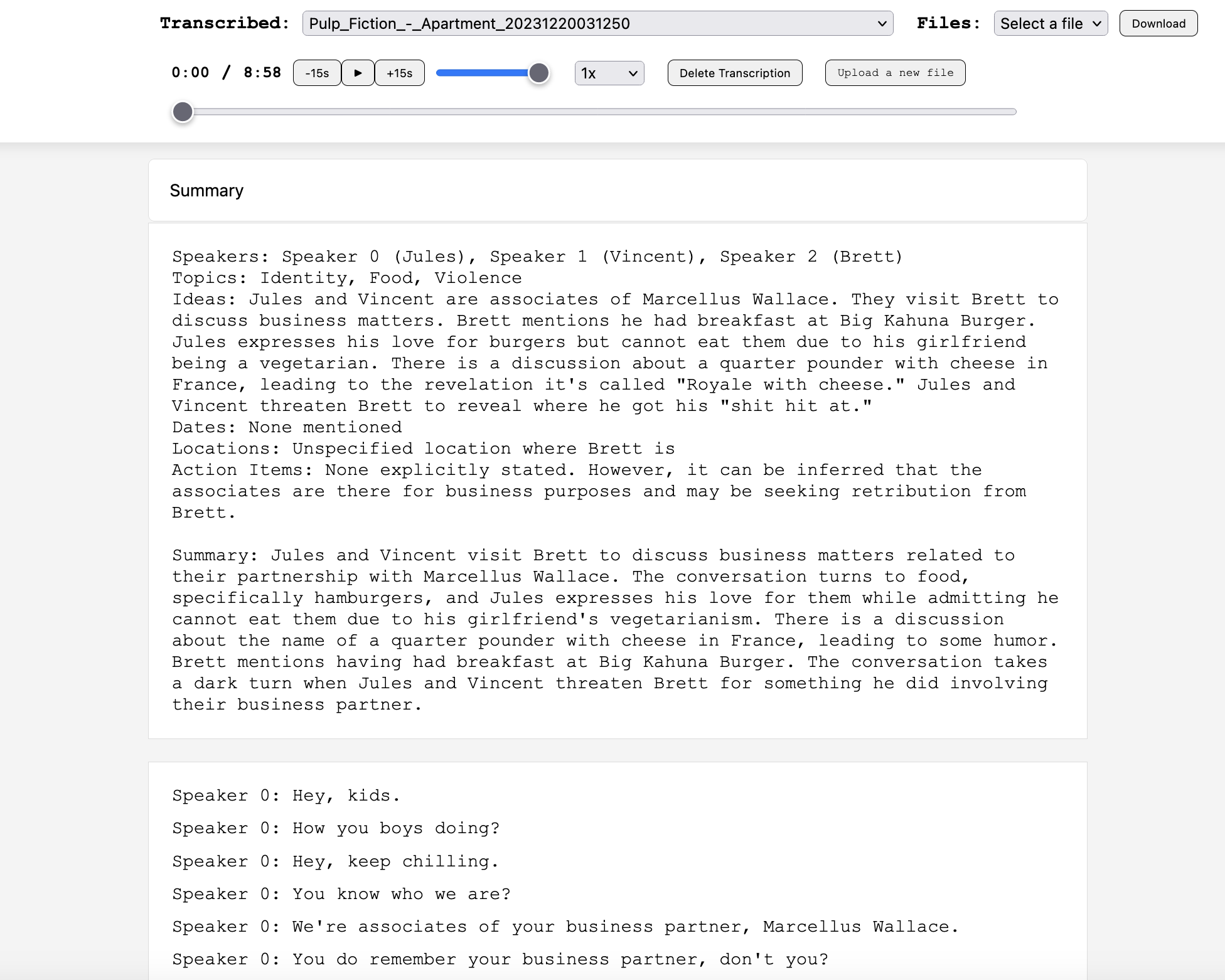
Summarize the transcription below. Be sure to include pertinent information about the speakers, including name and anything else shared.
Provide the summary output in the following style
Speakers: names or identifiers of speaking parties
Topics: topics included in the transcription
Ideas: any ideas that may have been mentioned
Dates: dates mentioned and what they correspond to
Locations: any locations mentioned
Action Items: any action items
Summary: overall summary of the transcription
The transcription is as follows
{transcription_text}
"""
Prerequisite: NVIDIA GPU
Warning: The resulting ts-gpu image is ~26GB and might take a hot second to create
./start-nobuild.shIf you'd like to build the images locally
chmod +x install.sh;
./install.sh;chmod +x run.sh;
./run.sh- SSH: 22222
- HTTP: 5006
- Ollama: 11434
- Meilisearch: 7700
- Port: 22222
- User:
transcriptionstream - Password:
nomoresaastax - Usage: Place audio files in
transcribeordiarize. Completed files are stored intranscribed.
- URL: http://dockerip:5006
- Features:
- Audio file upload/download
- Task completion alerts with interactive links
- HTML5 web player with speed control and transcription highlighting
- Time-synced transcription scrubbing/highlighting/scrolling
- URL: http://dockerip:11434
- change the prompt used, in
/ts-gpu/ts-summarize.py
- URL: http://dockerip:7700
Warning: This is example code for example purposes and should not be used in production environments without additional security measures.
- Update variables in the .env file
- Change the password for
transcriptionstreamin thets-gpuDockerfile. - Update the Ollama api endpoint IP in .env if you want to use a different endpoint
- Update the secret in .env for ts-web
- Use .env to choose which models are included in the initial build.
- Change the prompt text in ts-gpu/ts-summarize.py to fit your needs. Update ts-web/templates/transcription.html if you want to call it something other than summary.
- 12GB of vram may not be enough to run both whisper-diarization and ollama mistral. Whisper-diarization is fairly light on gpu memory out of the box, but Ollama's runner holds enough gpu memory open causing the diarization/transcription to run our of CUDA memory on occasion. Since I can't run both on the same host reliably, I've set the batch size for both whisper-diarization and whisperx to 16, from their default 8, and let a m series mac run the Ollama endpoint.
- Need to fix an issue with ts-web that throws an error to console when loading a transcription when a summary.txt file does not also exist. Lots of other annoyances with ts-web, but it's functional.
- Need to add a search/control interface to ts-web for Meilisearch