{kind=link}
{kind=link}
{kind=link}

- Imagen RGB
- Posición x_inicial, x_final, y_inicial, y_final (de la Bounding Box).
- Posición x,y de cada una de las 18 partes del cuerpo.
- Determinar posición respecto a la cámara
- Control de sesiones
-
Las que devuelven la pose con un esqueleto de 18 puntos
- OpenPose - https://github.com/CMU-Perceptual-Computing-Lab/openpose
- OpenVino - https://software.intel.com/en-us/openvino-toolkit
- Keras: con pesos de openPose - https://github.com/michalfaber/keras_Realtime_Multi-Person_Pose_Estimation
- Posenet - https://github.com/tensorflow/tfjs-models/tree/master/posenet
-
Las que devuelven sólo las BoundingBox de la persona
- Yolo - https://github.com/ndaidong/yolo-person-detect
- Faster R-CNN Pedestrian detection - https://github.com/ChaoPei/faster-rcnn-pedestrian-detection
- MobileNet SSD Object Detection - https://github.com/djmv/MobilNet_SSD_opencv
- Objetivo: Comparar Yolo vs Faster RCNN vs MobileNet SSD.
- Obtener un dataset de vídeo etiquetado de personas. (O generarlo manualmente).
- Evaluar rendimiento obtenido para cada aproximación. (Acierto nº de personas)
- Maximizar rendimiento calibrando los modelos o buscando nuevos que mejoren los anteriores.
- Por ejemplo, a partir de modelos que devuelven la pose de la persona detectada (esqueleto).
- Numero de aciertos en el número de personas por frame
- Formato (por frame) en csv:
[id_frame (o id_imagen si no se trabaja en vídeo), time_stamp, bbox_min_x, bbox_min_y, bbox_width, bbox_height, score (certeza) ]
- Imagen RGB
- Preferible, el crop de la BoundingBox extraída en el paso de Detección de Personas
- Posición x_inicial, x_final, y_inicial, y_final (de la Bounding Box).
- Posición x,y de cada una de las 68 facial landmarks de la cara (También hay modelos de 5 puntos en vez de 68)
- Determinar microexpresiones por los facial landmarks
- Mediante OpenCV (Haar) - https://github.com/shantnu/FaceDetect/
- Mediante OpenCV (DNN) - https://github.com/opencv/opencv/tree/master/samples/dnn
- Mediante dlib (HoG) - http://dlib.net/face_detector.py.html
- Mediante dlib (MMOD) - http://dlib.net/cnn_face_detector.py.html
- (Comparación entre los anteriores - https://www.learnopencv.com/face-detection-opencv-dlib-and-deep-learning-c-python/)
- Otros...
- Objetivo: A partir de la Bounding Box de la persona (imagen rgb), extraer la posición de la cara más probable (bounding box) - OpenCV vs dlib vs deep learning
- Obtener un dataset de caras etiquetado. (O generarlo manualmente).
- Evaluar rendimiento obtenido para cada aproximación. (Acierto posición de la cara)
- Maximizar rendimiento calibrando los modelos o buscando nuevos que mejoren los anteriores.
- Acierto en overlap de la bounding box de la cara (Mean IOU - Intersección sobre la unión)
- Formato (por frame) en csv:
[id_frame (o id_imagen si no se trabaja en vídeo), time_stamp, bbox_min_x, bbox_min_y, bbox_width, bbox_height, score (certeza) ]
- Crop de la BB de la cara extraída en Detección de caras
- Edad numérico (¿Rangos?)
- Género numérico (0, 1, probabilidad)
- Objetivo: A partir de la Bounding Box de la cara (imagen rgb), extraer las características de género y edad (y otras como etnia si fuera posible)
- Obtener un dataset de caras etiquetado con edad y género. (O generarlo manualmente).
- Evaluar rendimiento obtenido para cada aproximación. (Acierto de edad y género)
- Maximizar rendimiento calibrando los modelos o buscando nuevos que mejoren los anteriores.
- Calcular el error medio cuadrático y error medio absoluto de las predicciones obtenidas para cada característica.
- Formato (por frame) en csv:
[id_frame (o id_imagen si no se trabaja en vídeo), time_stamp, predicted_age, predicted_genre ]
- Crop de la BB de la cara extraída en Detección de caras
- Emoción dominante
- Disgust
- Surprise
- Sad
- Angry
- Fear
- Happy
- Contempt
- Neutral
- https://github.com/thoughtworksarts/EmoPy
- https://github.com/serengil/tensorflow-101/blob/master/python/facial-expression-recognition-from-stream.py (http://sefiks.com/2018/01/10/real-time-facial-expression-recognition-on-streaming-data/)
- https://github.com/amineHorseman/facial-expression-recognition-using-cnn
- https://github.com/ShawDa/facial-expression-recognition
- Objetivo: A partir de la Bounding Box de la cara (imagen rgb), extraer el estado emocional de la persona
- Obtener un dataset de caras etiquetado. (O generarlo manualmente).
- Evaluar rendimiento obtenido para cada aproximación.
- Maximizar rendimiento calibrando los modelos o buscando nuevos que mejoren los anteriores.
- Matriz de confusión para cada emoción como se cita en FER2013
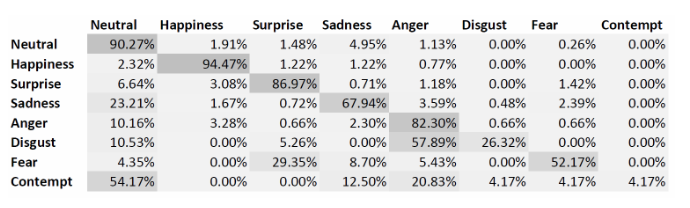
- Formato (por frame) en csv:
[id_frame (o id_imagen si no se trabaja en vídeo), time_stamp, score_neutral, score_happiness, score_surprise, score_sadness, score_anger, score_disgust, score_fear, score_contempt ]
{
"bbox_body":{ "coords" : [[x, y], [x, y`]], "image": '' },
"bbox_face":{ "coords" : [[x, y], [x', y']], "image": '' },
"skeleton": [ ],
"facial_landmarks": "",
"emotions": "",
"age": "",
"genre": ""
}Añadir links:
-
https://github.com/liuwei16/CSP (Estado del arte con código "High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection, CVPR, 2019")
-
http://www.robots.ox.ac.uk/~lav/Research/Projects/2009bbenfold_headpose/project.html (Dataset Oxford)
-
https://blog.nanonets.com/human-pose-estimation-2d-guide/ (Guía 2019 para pose estimation)
-
https://www.pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/ Mantener el tracking del objeto
-
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6907688 (https://www.youtube.com/watch?v=m-_t_aIlQwg) Real-Time RGB-D based People Detection and Tracking for Mobile Robots and Head-Worn Cameras