feat(subscriber): support multiple task callsites #68
Conversation
Signed-off-by: Eliza Weisman <[email protected]>
Signed-off-by: Eliza Weisman <[email protected]>
| const HEADER: &'static [&'static str] = | ||
| &["TID", "KIND", "TOTAL", "BUSY", "IDLE", "POLLS", "FIELDS"]; | ||
| const HEADER: &'static [&'static str] = &[ | ||
| "TID", "KIND", "TOTAL", "BUSY", "IDLE", "POLLS", "TARGET", "FIELDS", |
There was a problem hiding this comment.
Is the target useful when the fields are showing spawn.location?
There was a problem hiding this comment.
Yes, spawn.location indicates which line in the source code the task was spawned from, while the target tells us which library the span was generated in. For example, when using Tokio, the target will be tokio::task, while the spawn location field will be the line in the user code where tokio::task::spawn was called. This lets us easily distinguish between task spans provided by different crates with runtime instrumentation --- in the screenshot I posted, we can use the target to tell which entries in the task list correspond to Tokio tasks and which ones correspond to Rayon tasks, without memorizing which source locations in the application are calls to tokio::spawn and which are calls to rayon::spawn. The target field also allows us to sort (and, eventually, filter) the task list by which runtime the task spans came from, so that (for example) we can see all the Rayon tasks followed by all the Tokio tasks.
Also, we don't currently require any particular fields from the runtime providing the task spans...so just because Tokio currently provides a spawn.location field, other runtimes may not.
Signed-off-by: Eliza Weisman <[email protected]>
…tion into eliza/just-standard-naming
| let idx = self.len.fetch_add(1, Ordering::AcqRel); | ||
| assert!( | ||
| idx < MAX_CALLSITES, | ||
| "you tried to store more than 64 callsites, \ |
There was a problem hiding this comment.
whoops lol
| "you tried to store more than 64 callsites, \ | |
| "you tried to store more than 32 callsites, \ |
|
|
||
| #[derive(Debug, Default)] | ||
| pub(crate) struct Callsites { | ||
| ptrs: [AtomicPtr<Metadata<'static>>; MAX_CALLSITES], |
There was a problem hiding this comment.
I wonder, is the plan to use this structure for tracking other more granular callsites such as resource, resource ops? If that is the case, the number can grow to a value larger than 1 - 5. Is the plan to switch to a map based approach then or would a linear scan still be fast enough
There was a problem hiding this comment.
I was thinking we'd solve that problem when it becomes necessary :)
I think we may just want to use a hashset (or something) for callsites we expect to see a lot of, and arrays for callsites we expect there to be fewer of --- we could come up with some kind of adaptive structure that switches dynamically once it reaches a certain length, but in this case, I think we can make pretty good guesses about which callsites we expect to see a lot of, and which we expect to see fewer of.
There was a problem hiding this comment.
Also, as we start caring about more types of callsites, I think we may want to switch to a model where we store the callsite alongside some data about which type of callsite it is, in one array, instead of storing each type of callsites in separate arrays. That way, we only do one linear scan, and then know everything we need to about that callsite, instead of having to look in multiple arrays.
Currently, the per-task spans generated by Tokio's `tracing` feature have the span name "task" and the target "tokio::task". This is because the console subscriber identified tasks by looking specifically for the "tokio::task" target. In tokio-rs/console#41, it was proposed that the console change to a more generic system for identifying the spans that correspond to tasks, to allow recording tasks belonging to multiple runtime crates (e.g. an application that uses Tokio for async tasks and Rayon for CPU-bound tasks). PR tokio-rs/console#68 changed the console to track any spans "runtime.spawn", regardless of target (so that the target can be used to identify the runtime a task came from), with "tokio::task/task" tracked for backwards-compatibility with the current release version of tokio. This branch changes Tokio's span naming to the new convention. I also rearranged a couple fields so that the task's kind field always comes before the name and spawn location, since it's likely to be the shortest, and renamed the `function` field on blocking tasks to `fn`, for brevity's sake. Signed-off-by: Eliza Weisman <[email protected]>
Currently, the per-task spans generated by Tokio's `tracing` feature have the span name "task" and the target "tokio::task". This is because the console subscriber identified tasks by looking specifically for the "tokio::task" target. In tokio-rs/console#41, it was proposed that the console change to a more generic system for identifying the spans that correspond to tasks, to allow recording tasks belonging to multiple runtime crates (e.g. an application that uses Tokio for async tasks and Rayon for CPU-bound tasks). PR tokio-rs/console#68 changed the console to track any spans "runtime.spawn", regardless of target (so that the target can be used to identify the runtime a task came from), with "tokio::task/task" tracked for backwards-compatibility with the current release version of tokio. This branch changes Tokio's span naming to the new convention. I also rearranged a couple fields so that the task's kind field always comes before the name and spawn location, since it's likely to be the shortest, and renamed the `function` field on blocking tasks to `fn`, for brevity's sake. Signed-off-by: Eliza Weisman <[email protected]>
This branch updates the console subscriber to allow recording multiple
tracingspan callsites as tasks, rather than only tracking the firstcallsite that's found. This will allow collecting data from multiple
runtimes, and also removes the requirement that all task spans originate
from a single callsite, which will make implementing runtime
instrumentation simpler.
This is implemented by adding a new data structure for storing a set of
callsites. It's implemented as an array of
AtomicPtrs to metadata,plus an
AtomicUsizetracking the next index to push to. As callsitesare registered, their addresses are stored at the push index, which is
incremented. When testing if a callsite is in the set, the subscriber
performs a linear scan over the pushed callsites.
A linear scan over an array is not algorithmically optimal, but in
practice, it is probably the best data structure here. Although the
algorithmic complexity of doing a linear scan is O(n), and using a
HashSetor something is O(1), there are never going to be a great dealof items in the array --- in many programs, each callsite list will only
ever have a single entry, and in extreme cases, like when using
tokio,rayon, andasync-stdin the same program, there might be four orfive entries. So, the cost of an O(n) linear scan over a very small
n slice is likely much lower than the constant-factor costs of using
an O(1)
HashSetin this case. Also, the array allows us to avoid usinga lock, or introducing the additional overhead of a concurrent hash set.
The same data structure is used to track waker op callsites, so we can
now avoid doing string comparisons to detect those callsites.
In addition, I've updated the console to display the metadata targets of
tasks. This is useful because tasks may now be recorded from callsites
in different libraries, or in different modules of one library (e.g.
tokio's task, blocking task, and local task spans could now have
separate callsites). The targets can be used to distinguish between
different task span locations.
Here's a screenshot showing a demo app that uses
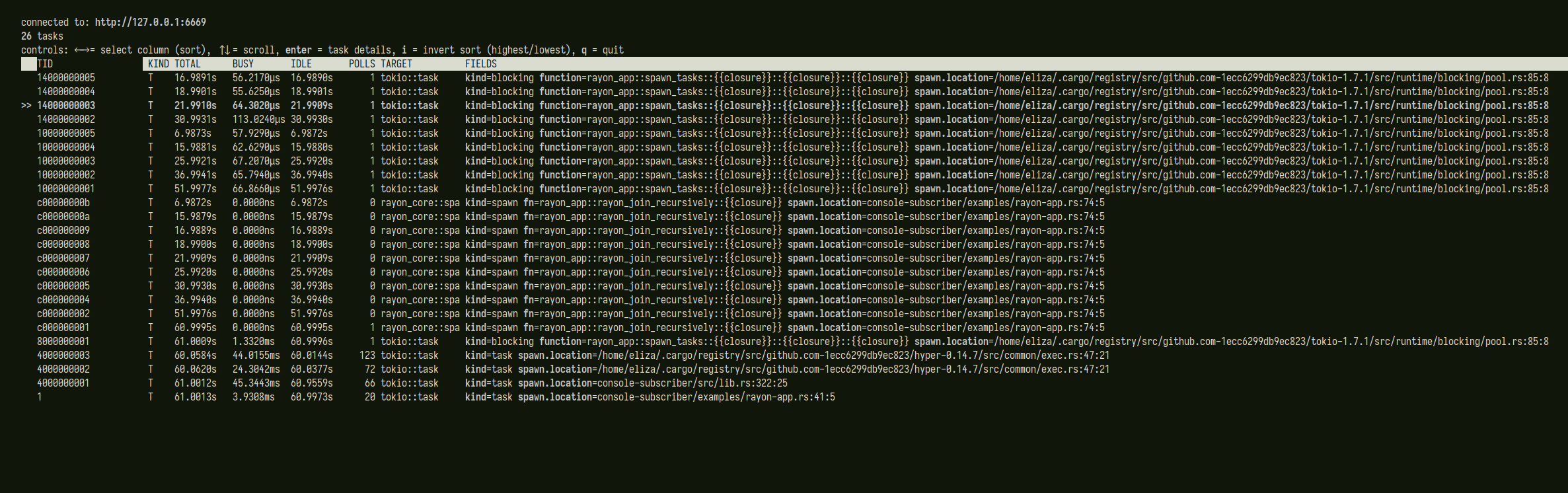
tokio's normal andblocking tasks, alongside a (work in progress) version of
rayonwithconsole instrumentation: