Over the past year there have been several questions have been raised by the community about the details of the model such as :
- Why we chose to augment a Fully Convolutional Network with an LSTM?
- What is dimension shuffle actually doing?
- After dimension shuffle, does the LSTM simply lose all recurrent behaviour?
- Why not replace the LSTM by another RNN such as GRU?
- Whether there is any actual improvement to be obtained from this augmentation?
We therefore perform a detailed ablation study, composing nearly 3,627 experiments that attempt to analyse and answer these questionsand to provide a better understanding of the LSTM-FCN/ALSTM-FCN time series classification model and each of its sub-module.
A detailed explanation of our experiments can be found in our paper, Insights into LSTM Fully Convolutional Networks for Time Series Classification.
The original LSTM-FCN models and ALSTM-models are from the paper LSTM Fully Convolutional Networks for Time Series Classification, augment the fast classification performance of Temporal Convolutional layers with the precise classification of Long Short Term Memory Recurrent Neural Networks.
Below is the model architecture:
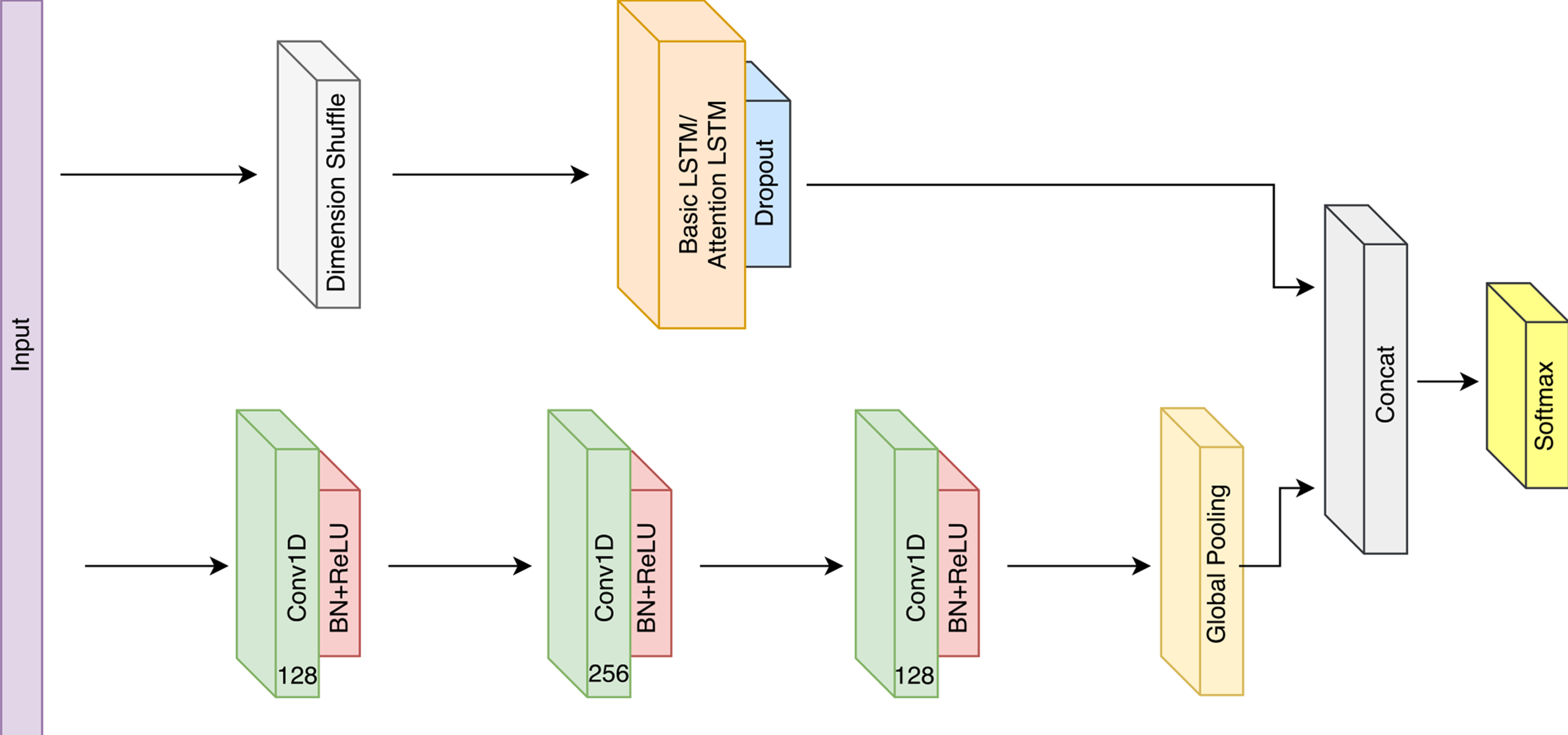
Download the repository and apply pip install -r requirements.txt to install the required libraries.
Keras with the Tensorflow backend has been used for the development of the models, and there is currently no support for Theano or CNTK backends. The weights have not been tested with those backends.
The data can be obtained as a zip file from here - https://www.cs.ucr.edu/~eamonn/time_series_data_2018/
Extract that into some folder and it will give 127 different folders. Copy paste the util script extract_all_datasets.py to this folder and run it to get a single folder _data with all 127 datasets extracted. Cut-paste these files into the Data directory.
Note : The input to the Input layer of all models will be pre-shuffled to be in the shape (Batchsize, 1, Number of timesteps), and the input will be shuffled again before being applied to the CNNs (to obtain the correct shape (Batchsize, Number of timesteps, 1)). This is in contrast to the paper where the input is of the shape (Batchsize, Number of timesteps, 1) and the shuffle operation is applied before the LSTM to obtain the input shape (Batchsize, 1, Number of timesteps). These operations are equivalent.
All 127 UCR datasets can be evaluated with the provided code.
To train the raw input into an SVM and MLP classifier, run train_mlp_svm_data.py and train_mlp_raw_data.py.
To train all Deep Learning Models (LSTM FCN, ALSTM FCN, GRU FCN, Dense FCN, RNN FCN, A/LSTM without Dim Shuffle), run all_datasets_training.py.
To extract the features of each submodule (LSTM Block and ALSTM Block), run extract_all_features.py after the ALSTM FCN and LSTM FCN models are trained.
To train and SVM and MLP classifier on the extracted features of each submodule, run train_all_mlp_features.py and train_all_svm_features.py.
Run the mlp_svm_data.py script to train an svm model on the raw input data.
Run the mlp_mlp_data.py script to train an mlp model on the raw input data.
DATASET_ID is the list of datasets you want to run.
To train all Deep Learning Models (LSTM FCN, ALSTM FCN, GRU FCN, Dense FCN, RNN FCN, A/LSTM without Dim Shuffle) use all_datasets_training.py.
In the main function you can select and uncomment the datasets you want to process.
-
The list CELLS in line 408 contain the LSTM/ALSTM/GRU/Dense/RNN cell size you want to use.
-
Normalize = False means no normalization will be done
-
Normalize = True / 1 means sample wise z-normalization
-
Normalize = 2 means dataset normalization.
These are the functions to call the model:
- To use the LSTM FCN model :
model = generate_lstmfcn() - To use the ALSTM FCN model :
model = generate_alstmfcn() - To use the GRU FCN model:
model = generate_grufcn() - To use the Dense FCN model:
model = generate_densefcn() - To use the RNN FCN model:
model = generate_rnnfcn() - To use the LSTM FCN model without dimension shuffle:
model = generate_ndlstmfcn()
To extract features of each sub-module(LSTM Block, and FCN Block) from the LSTM/ALSTM FCN model, run extract_all_features.py.
-
DATASET_IDis the list of datasets you want to run -
num_cellsis the LSTM/Attention LSTM cell size -
model_fnis the function that builds the model, not the model itself.
These two scrips are used to train the mlp classifiers and svm classifiers on the features exctracted from each sub-module(LSTM Block, and FCN Block)
DATASET_IDis the list of datasets you want to run
To train the a model, uncomment the line below and execute the script. Note that '???????' will already be provided, so there is no need to replace it. It refers to the prefix of the saved weight file. Also, if weights are already provided, this operation will overwrite those weights.
train_model(model, did, dataset_name_, epochs=2000, batch_size=128,normalize_timeseries=normalize_dataset)
To evaluate the performance of the model, simply execute the script with the below line uncommented.
evaluate_model(model, did, dataset_name_, batch_size=128,normalize_timeseries=normalize_dataset)
Our conclusions of our findings can be found in our paper, Insights into LSTM Fully Convolutional Networks for Time Series Classification.
@article{karim_majumdar2019insights,
title={Insights into LSTM Fully Convolutional Networks for Time Series Classification},
author={Karim*, Fazle and Majumdar*, Somshubra and Darabi, Houshang },
journal={Arxiv},
}