第 56 期 channel & select 源码分析 #450
Comments
|
非常棒的分享,期待 |
|
期待 |
1 similar comment
|
期待 |
|
好好预习,享受分享,禁止无意义灌水 |
|
期待 |
|
nb |
|
期待 |
|
感谢分享,很有深度 👍 |
|
整理了本次分享的 Q&A ,其中包括几个未在分享过程中进行回答的问题: Q: buffer 队列的顺序是先进后出吗? A: 不对,channel 中的 ring buffer 是一种先进先出 FIFO 的结构。 Q: channel 也是基于共享内存实现的吗? A: 没错,从实现上来看,具体而言,channel 是基于对 buffer 这一共享内存的实体来实现的消息通信,每次对所共享内存区域的操作都需要使用互斥锁(个别 fast path 除外)。 Q: 创建 channel 所申请的内存,在其被 close 后何时才会释放内存? A: 需要等待垃圾回收器的配合(GC)。举例来说,对于某个 channel 而言,所通信双方的 goroutine 均已进入 dead 状态,则垃圾回收器会将 channel 创建时申请的内存回收到待回收的内存池,在当下一次用户态代码申请内存时候,会按需对内存进行清理(内存分配器的工作原理);由此可见:如果我们能够确信某个 channel 不会使其通信的 goroutine 发生阻塞,则不必将其关闭,因为垃圾回收器会帮我们进行处理。 Q: 请问是否可以分享一下带中文注释的代码? A: 带中文注释的代码可以在这个仓库的 Q: 能详细说明一下使用 channel 发送指针产生数据竞争的情况吗? A: 这个其实很好理解,若指针作为 channel 发送对象的数据,指针本身会被 channel 拷贝,但指针指向的数据本身并没有被拷贝,这时若两个 goroutine 对该数据进行读写,仍然会发生数据竞争;请参考此例 (使用 -race 选项来检测竞争情况)。因此,除非在明确理解代码不会发生竞争的情况下,一般不推荐向 channel 发送指针数据。 Q: 分享的 PPT 的地址在哪儿? A: 链接在这里,此 PPT 允许评论,若发现任何错误,非常感谢能够指出其错误,以免误导其他读者。 Q: 请问分享的视频链接是什么? A: 有两个渠道,YouTube, bilibili,bilibili 中视频声画不同步,可使用 B 站的播放器进行调整,或推荐使用 YouTube 观看。 Q: Go 语言中所有类型都是不安全的吗? A: 这个问题不太完整,提问者应该是想说 Go 中的所有类型都不是并发安全的。这个观点不对,sync.Map 就是一个并发安全的类型(当然如果你不考虑标准库的话,那么内建类型中,channel 这个类型也是并发安全的类型)。 Q: 如果 channel 发送的结构体太大,会不会有内存消耗过大的问题? A: 取决于你结构体本身的大小以及你所申请的 buffer 的大小。通常在创建一个 buffered channel 时,该 channel 消耗的内存就已经确定了,如果内存消耗太大,则会触发运行时错误。我们更应该关注的其实是使用 channel 发送大小较大的结构体产生的性能问题,因为消息发送过程中产生的内存拷贝其实是一件非常耗性能的操作。 Q: select{} 的某个 case 发生阻塞则其他 case 也不会得到执行吗? A: 对的。包含多个 case 的 select 是随机触发的,且一次只有一个 case 得到执行。极端情况下,如果其中一个 case 发生永久阻塞,则另一个 case 永远不会得到执行。 Q: select 中使用的 heap sort 如何保证每个 case 得到均等的执行概率呢?是否可能会存在一个 case 永远不会被执行到? A: 理论上确实是这样。但是代码里生成随机数的方法保证了是均匀分布,也就是说一个区间内的随机数,某个数一直不出现的概率是零,而且还可以考虑伪随机数的周期性,所以所有的 case 一定会被选择到,关于随机数生成的具体方法,参见 runtime.fastrand 函数。 Q: lockorder 的作用是什么?具体锁是指锁什么? A: lockorder 是根据 pollorder 和 channel 内存地址的顺序进行堆排序得到的。 pollorder 是根据 random shuffle 算法得到的,而 channel 的内存地址其实是内存分配器决定的,考虑到用户态代码的随机性,因此堆排序得到的 lockorder 的结果也可以认为是随机的。lockorder 会按照其排序得到的锁的顺序,依次对不同的 channel 上锁,保护其 channel 不被操作。 Q: buffer 较大的情况下为什么没有使用链表结构? A: 这个应该是考虑了缓存的局部性原理,数组具有天然的连续内存,如果 channel 在频繁的进行通信,使用数组自然能使用 CPU 缓存局部性的优势提高性能。 Q: chansend 中的 fast path 是直接访问 qcount 的,为什么 chanrecv 中却使用了 atomic load 来读取 qcount 和 closed 字段呢? A: 这个这两个 fast path 其实炫技的成分太高了,我们需要先理解这两个 fast path 才能理解为什么这里一个需要 atomic 操作而另一个不需要。 首先,他们是针对 select 语句中非阻塞 channel 操作的的一种优化,也就是说要求不在 channel 上发生阻塞(能失败则立刻失败)。这时候我们要考虑关于 channel 的这样两个事实,如果 channel 没有被 close:
理解是否需要 atomic 操作的关键在于:atomic 操作保证了代码的内存顺序,是否发生指令重排。 由于 channel 只能由未关闭状态转换为关闭状态,因此在 !block 的异步操作中, 第一种情况下,channel 未关闭和 channel 不能进行发送之间的指令重排是能够保证代码的正确性的,因为:在不发生重排时,「不能进行发送」同样适用于 channel 已经 close。如果 closed 的操作被重排到不能进行发送之后,依然隐含着在判断「不能进行发送」这个条件时候 channel 仍然是未 closed 的。 但第二种情况中,如果「不能进行接收」和 channel 未关闭发生重排,我们无法保证在观察 channel 未关闭之后,得到的 「不能进行接收」是 channel 尚未关闭得到的结果,这时原本应该得到「已关闭且 buf 空」的结论(chanrecv 应该返回 true, false),却得到了「未关闭且 buf 空」(返回值 false, false),从而报告错误的状态。因此必须使此处的 qcount 和 closed 的读取操作的顺序通过原子操作得到顺序保障。 Q: 听说 cgo 性能不太好,是真的吗? A: 是的,至少我的经验的结论是 cgo 性能非常差。因为每次进入一个 cgo 调用相当于进入 system call,这时 goroutine 会被抢占,从而导致的结果就是可能会很久之后才被重新调度,如果此时我们需要一个密集的 cgo 调用循环,则性能会非常差。 Q: 看到你即写 C++ 也研究 Go 源码,还做深度学习,能不能分享一下学习的经验? A: 老实说我已经很久没(正儿八经)写 C++ (的项目)了,写 C++ 那还是我本科时候的事情,那个时候对 C++ 的理解还是很流畅的,但现在已经感觉 C++ 对于我编程的心智负担太高了,在编写逻辑之外还需要考虑很多与之不相关的语言逻辑,大部分时间其实浪费在这上面了,时间稍长就容易忘记一些特性。加上我后来学了 Go ,就更不想用 C++ 了。另外,我读硕士的时候主要在研究机器学习,主要就是在写 python 脚本。所以我暂时也没什么比较系统的经验,如果非要回答的话,我的一个经验就是当(读源码)遇到问题之后硬着头皮走下去,当积累到一定程度之后在回过头去审视这些问题,就会发现一切都理所当然。 Q: 你是怎么读 Go 源码的? A: 最开始的时,我选择了一个特定的版本,将想看的源码做了一个拷贝(主要是运行时的代码,刨去了 test、cgo、架构特定等代码),而后每当 Go 更新一个版本时,都用 GitHub Pull request 的 diff 功能,去看那些我关心的代码都发生了哪些改变。当需要我自身拷贝的代码时,其实会发现工作量并不是很大。刚接触 Go 源码的时候其实也是一脸懵,当时也并没有太多 Go 的编码经验,甚至连官方注释都看不太明白,后来硬着头皮看了一段时间,就慢慢的适应了。 Q: 有没有什么比较好的英文的(Go 相关的)资料推荐? A: 其实我订阅的 Go 的信息并不多,主要原因还是信息量太多,平时太忙应付不过来,所以只订阅了几个比较知名的博客,比如 www.ardanlabs.com/blog, dave.cheney.net 和一些 medium 上比较大众的跟 Go 有关的 channel;我倒是经常在地铁或睡觉前听一个叫做 Go Time 的 Podcast,这个 Podcast 是有 Go 团队的成员参与的,很值得一听。另外再推荐一些与 Go 不是强相关的技术类书籍,参见 书籍推荐。 欢迎跟进更多问题与讨论。 |
|
感谢 |
|
mark |
如果不发送指针不是会产生拷贝吗 ? 而且是有可能会在处理的时候修改数据 copy-on-write 也不会避免拷贝。向 channel 发送指针数据应该是比较常用的方式吧。 |
@Astone-Chou 如果不发送指针不是会产生拷贝吗 -- channel应该是用来发送小数据的。跟数据的正确性相比,这点内存拷贝带来的性能损失还是可以接受的。 向 channel 发送指针数据应该是比较常用的方式吧 -- 并不是 |
TL;DR: 这个结论的前提是,在明确理解代码不会发生竞争的情况下。 |
使用 chan 的目的不就是这个吗。确保使用这个临界资源的时候没有竞态条件。 |
发生竞争的条件是「并发读写」或者「并发写」。你前面给出的所有例子均为在一端构造数据,发送指向数据的指针,再在另一端 goroutine 进行操纵。这种情况要求程序员明确理解数据的流向,明确理解这种情况下构造的数据不在两个 goroutine 之间竞争。这种情况下的临界资源是指针而非数据本身。即 chan 在这里的作用是安全的传递一个只会在一个 goroutine 中操作的数据的指针,不属于结论的情况。 |
你这种说法其实和如何使用这个数据相关。比如你在 mutex 包裹的临界区使用一个结构体的指针去访问数据。但是你又在另一个非临界区使用另一个指针(但是指向相同的结构体)操作这个数据。当然会有问题。 我只是说 chan 传递指针数据这种情况很正常。像 chan []byte , chan net.Conn 这种实际上都属于类似传递指针的情况. |
这里只针对 QA 中结论中不太引人注目的前提进行答疑和警醒,如果你希望进一步总结在 channel 中使用指针的最佳实践清单展开讨论请开一个新的 issue 来吸引更多人参与。 |
|
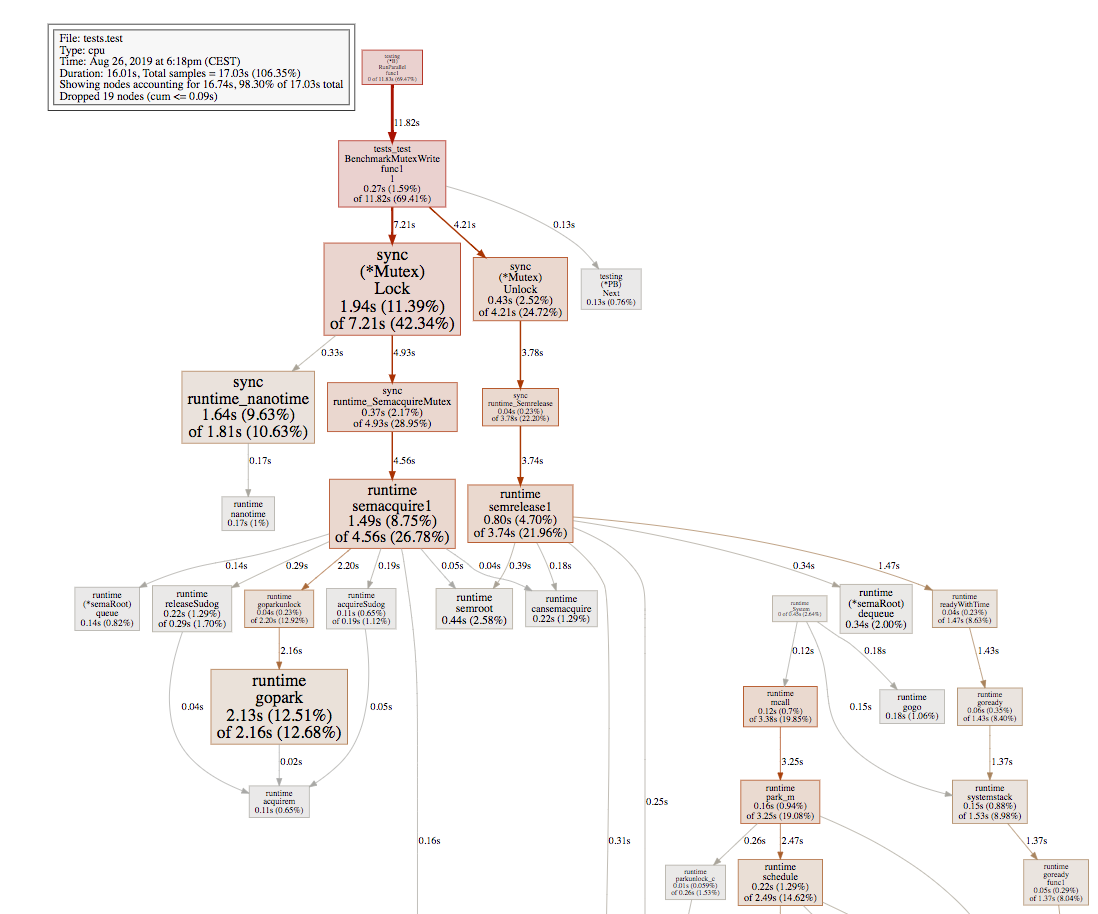
可以具体说一下为什么channel和mutex的性能差异吗 |
mutex 的实现基于 runtime semaphore,性能测试中出现的性能骤降跟 semacquire1 的实现有关。 2400:
4800:
可以明显看到 4800 中 gopark 的调用频率明显增加,考虑 semacquire1 的代码: func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
// fast path
if cansemacquire(addr) {
return
}
s := acquireSudog()
root := semroot(addr)
...
for {
// middle path
lock(&root.lock)
atomic.Xadd(&root.nwait, 1)
if cansemacquire(addr) {
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
// slow path
root.queue(addr, s, lifo)
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
...
}根据这段代码可以匹配两个图的实际执行情况:
据此解释了 sync.Mutex 出现的性能骤降的原因。 channel 的性能比较稳定的原因在于其实现完全基于操作系统,例如 linux 下为 futex 实现,不包含调度器上下文切换,从而性能随竞争数量的增加而线性的下降。 |

|
请问一下, 为什么close channel的时候可以全部让阻塞着的gs ready, 如果没有人读, send的再次被调度的时候还是没法继续呀(假设buffer已经满了) |
|
@Petelin 你好,我不知道是否正确理解了你的问题:close 发生后,send 不再会被调度,close 后 ready 的目的是为了让需要 recv 的 g 能将 buffer 中的数据接收完毕。这个过程不需要假设 buffer 是否已满。 |
我没有表述清楚. 假设我们现在有一个channel, buffer是满的, 然后还有几个sudoG在sendq里面. 然后我写了这么一段代码. 在执行close的时候channel的数据是这样的 |
这个感觉也有点问题. 我理解的是close的时候两个等待队列只能有一个有数据. 那么
不知道这样理解对不对. ps: 你的youtube视频特别好, 非常感谢上传, 我正在挨个看. |
|
@Petelin 你好,你说的这种情况确实存在,但我们应该将其理解为错误的代码行为。从直观形式上,在 close 过程中将 sendq 中的 g 唤醒不符合直觉,因为 g 此时需要发送数据,但一旦被唤醒后,由于 channel 已经被 close,则程序必然会 panic。但换个角度思考,此做法从规避了错误的代码行为,保证了不会出现向一个已经关闭的 channel 继续发送数据。正确的代码行为应该是在关闭 channel 前,确保所有的 sender 都已将数据发送或已写入 buf。 如果我们进一步讨论是否应该让 Go 语言支持判断向一个已关闭的 channel 发送数据是否成功,就目前的形势来看,似乎不太可能,参见被拒提案 https://github.com/golang/go/issues/21985。 |
|
channel 传slice使用不当也会竞争 |
|
更正一个严重的错误:https://youtu.be/d7fFCGGn0Wc?t=635; 正确的版本: |
|
mark |
|
注意到close chan时的lock 和 send/rec是同一把锁,那么他们之前的锁竞争是否遵循mutex锁的竞争规则? 如果遵循的话,也就意味着close可能会在很多send 和 receive 操作之后才会执行。 |
|
chansend fastpath 读取qcount 的时候,变量可见性是怎么确保的呢? 如下场景 而且,比较疑惑的是,代码里写的是依靠 chanrecv 和 closechan 的副作用来达到 更新 closed和 full()的 |
你好,sync.Mutex底层基于runtime semaphore, 锁竞争激烈时由go调度器通过gopark将g阻塞,并且挂入semtable;然而channel底层的lock是基于runtime.mutex, 在linux下基于futex来对m进行阻塞。那这样在高并发锁激烈的情况下,不应该是channel(runtime.mutex)的性能开销大一些吗? 毕竟sync.Mutex是用户级别的调度,runtime.Mutex是系统级别的调度。我比较疑惑,请问能否详细解释下 |
内容简介
Go 语言除了提供传统的互斥量、同步组等同步原语之外,还受 CSP 理论的影响,提供了 channel 这一强有力的同步原语。本次分享将讨论 channel 及其相关的 select 语句的源码,并简要讨论 Go 语言同步原语中的性能差异与反思。
内容大纲
分享地址
2019.08.22, 20:30 ~ 21:30, UTC+8
https://zoom.us/j/6923842137
进一步阅读的材料
The text was updated successfully, but these errors were encountered: