This repository containts a practical implementation of a data engineering project that spans across web-scraping real-estates, processing with Spark and Delta Lake, adding data science with Jupyter Notebooks, ingesting data into Apache Druid, visualizing with Apache Superset, and managing workflows with Dagster—all orchestrated on Kubernetes.
Built your own DE project or forked mine? Let me know in the comments; I'd be curious to know more about.
This Practical Data Engineering project addresses common data engineering challenges while exploring innovative technologies. It should serve as a learning project but incorporate comprehensive real-world use cases. It's a guide to building a data application that collects real-estate data, enriches it with various metrics, and offers insights through machine learning and data visualization. This application helps you find your dream properties in your area and showcases how to handle a full-fledged data engineering pipeline using modern tools and frameworks.
- Real-World Application: Tackling a genuine problem with real estate data to find the best properties.
- Comprehensive Tech Stack: Utilizes a wide range of technologies from web scraping, S3 storage, data processing, machine learning, to data visualization and orchestration.
- Hands-On Learning: Offers a hands-on approach to understanding how different technologies integrate and complement each other in a real-world scenario.
- Scraping real estate listings with Beautiful Soup
- Change Data Capture (CDC) mechanisms for efficient data updates
- Utilizing MinIO as an S3-Gateway for cloud-agnostic storage
- Implementing UPSERTs and ACID transactions with Delta Lake
- Integrating Jupyter Notebooks for data science tasks Visualizing data with Apache Superset
- Orchestrating workflows with Dagster
- Deploying on Kubernetes for scalability and cloud-agnostic architecture
This project leverages a vast array of open-source technologies including MinIO, Spark, Delta Lake, Jupyter Notebooks, Apache Druid, Apache Superset, and Dagster—all running on Kubernetes to ensure scalability and cloud-agnostic deployment.
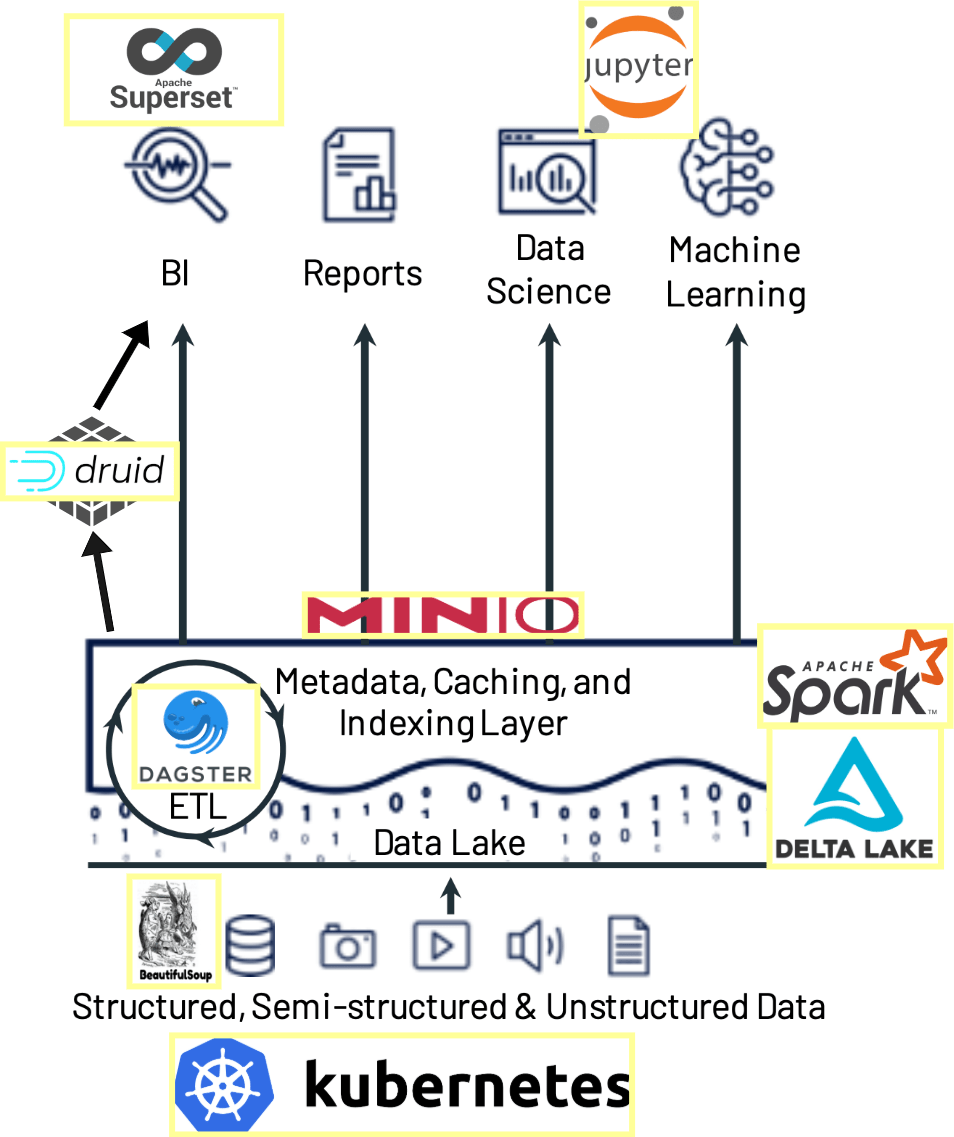
This project started in November 2020 as a project for me to learn and teach about data engineering. I published the entire project in March 2021 (see the initial version on branch v1). Three years later, it's interesting that the tools used in this project are still used today. We always say how fast the Modern Data Stack changes, but if you choose wisely, you see that good tools will stay the time. Today, in March 2024, I updated the project to the latest Dagster and representative tools versions. I kept most technologies, except Apache Spark. It was a nightmare to setup locally and to work with Delta Lake SQL APi. I replaced it with delta-rs direct, which is implemented in Rust and can edit and write Delta Tables directly in Python.
Next, I might add Rill Developer to the mix to have some fun analyzing the data powered by DuckDB. For a more production-ready dashboard, Superset would still be my choice tough.
Please refer to individual component directories for detailed setup and usage instructions. The project is designed to run both locally and on cloud environments, offering flexibility in deployment and testing.
- Python and pip for installing dependencies
- MinIO running for cloud-agnostic S3 storage
- Docker Desktop & Kubernetes for running Jupyter Notebooks (optional, if you want ML capabilities)
- Basic understanding of Python and SQL for effective navigation and customization of the project
⚠️ Disclaimer: For Educational Use Only
This project is designed for educational purposes, demonstrating web scraping and data engineering practices. Ensure you do not violate any website's copyright or terms of service, and approach scraping responsibly and respectfully.
- Clone this repository.
- Install dependencies
- Install and start MinIO
- Explore the data with the provided Jupyter Notebooks and Superset dashboards.
#change to the pipeline directory
cd src/pipelines/real-estate
# installation
pip install -e ".[dev]"
# run minio
minio server /tmp/minio/
# create the bucket `real-estate` MinIO on 127.0.0.1:9000
# Create access key/passwords, defaults are MINIO_ROOT_USER/MINIO_ROOT_PASSWORD with default values that should work without any further configuration.
# startup dagster
dagster dev
- YouTube Video: Watch the video tutorial on building this project.
- Building a Data Engineering Project in 20 Minutes: Access the full blog post detailing the project's development, challenges, and solutions.
- DevOps Repositories: Explore the setup for Druid, MinIO and other components.
- Open-Source Data Engineering Projects: A curated list of open-source data engineering projects to explore.
- Data Engineering Vault: A collection of resources, tutorials, and guides for data engineering projects.
- Data Engineering Design Patterns: My book about the evolution of data engineering and its design patterns.
Your feedback is invaluable to improve this project. If you've built your project based on this repository or have suggestions, please let me know through creating an Issues or a Pull Request directly.
This project is part of my journey in exploring data engineering challenges and solutions. It's an open invitation for everyone interested in data engineering to learn, contribute, and share your experiences.
Below some impressions of the jupyter notebook used in this project.