Add SIMD-0003: Dynamic Base fees#4
Conversation
|
Does it make the most sense to tie these increases to the base fee per compute units? I.e. we start with a fee of 0.0000005 sol per 1000 compute units. Blocks going over half the dedicated non-vote compute per block would lead to the next n number of blocks having their fee per compute unit adjusted up some predictable amount. Validators could adjust the Solana-wide base fee through governance means at regular intervals (i.e. every 10 epochs or so) to semi-adjust to changes in sol/fiat price (fiat being what hardware and bandwidth are priced according to). Sui has a system where fees are adjusted by the validator set regularly. Also, this whole system might be made easier if non vote and vote compute are separated out a bit more? cc @AshwinSekar @taozhu-chicago @apfitzge |
|
A few (clarifying) questions/comments:
|
Because all nodes with different hardware will have slightly different timing. Redlining the network will cause slower nodes fall behind and not be ready with their block when they are supposed to.
They can, but a faulty majority can redline the cost.
Votes pay fees like all other txs. so if the load increases past 50% continuously, leaders will drop txs to reduce the price. |
Don't think this is the case. Network performance should be close to the average performance of majority of nodes - excluding the slowest and fastest nodes. |
Mmm, it does sound more fair to tie the fee to CU, so 1M cu tx would pay more compare to 1K cu tx when load is high, perhaps we can utilize
The proposal wants the same base fee being applied to vote and non-vote in same way, but still good to continue separate votes from non-votes. |
|
does this impact storage costs in anyway? or just compute? |
|
Got it. It looks like a mechanism to penalize some malicious behaviour / incentivize good behaviour, where good behaviour is not going above 50% capacity for longer than 8 blocks. Doesn't this also discourage higher performance? It seems like the goal to have uniform performance and nothing incentivises block producers to produce fuller blocks, even if they can. Shouldn't this be the goal also / optimized for? How and when will this target be raised to increase network capacity? How will we get past 4k tps? |
tps != compute limit, since transactions like transfers can be very cheap. overall the validators need to agree to raise the system level compute limit above 48m CUs. |
Thats what the proposal does. Base fee per CU is increased. I think validators should signal a vote on total CUs per block and lowest base fee allowed that can be updated once per epoch. |
It would be nice if there was a way to limit the exposure outside of using an older blockhash with a lower fee. However, I can't think of a way that doesn't lend itself to abuse. |
What would be better I think, is to charge based on the fee at any referenced live blockhash, which can be balanced by having a "stale fee" for transactions. Essentially, you can send a transaction with a blockhash as old as possible to get a cheaper transaction in, but you also increase the risk of having your transaction not included while the blockhash is still good. If the transaction doesn't make it in before expiry, it can be charged as a "stale" transaction instead. Essentially, you have a second window after the normal blockhash life where the bulk of transactions are ignored and just the fee payer is charged -- low compute and highly parallelizable. If transactions are more at risk of actually getting charged instead of just dropped when expired, you'll have fewer people willing to spam loads of transactions. Having a slow escalating fee schedule doesn't help much with the initial flood of spam due to the slow ramp in fees but this reduces the incentive greatly. Validators can also extract more value for spam and the bandwidth used to deal with it. More description here: solana-labs/solana#25211 |
@zfedoran yea, maybe if this approach isn't sufficient the transaction can add a maximum fee later. But id rather not add transaction fields when we don't need to. |
|
I'm officially piling onto the wagon of "don't burn 100% of base fees". I would prefer to burn 50% of all tx fees (base, CU, priority) like Laine proposed.
I am not convinced of the necessity of taking action here. Validators are already financially encouraged to produce blocks that can be replayed and voted on by the majority of the cluster, because producing blocks that can't be replayed by a significant number of validators increases the chances of being forked (because the next leader has to be able to replay your block in time to chain off of it rather than skipping back to a prior leader whose block could be replayed in time). Validators are also financially encouraged to produce the largest block (most block rewards) that can meet the above criteria. So I don't see a need to try to target a particular performance threshold. Nodes are incentivized to find what the highest performance that can be achieved reliably is, and use that as the metric for deciding how many CU to include in a block. Furthermore, nodes are incentivized to stay within the performance threshold required to reliably replay blocks, because falling behind means potentially missing votes and thus vote rewards. And when/if timely vote credits happen, this effect is magnified since any delay in voting results in a real negative impact on vote credit earnings. There are probably some things that validators could do to more intelligently and efficiently choose block sizes, and I will mention them briefly even though they're not relevant to the fee structure of this proposal per se:
I guess this is relevant to part of the proposal though: "There are two ways the validators control the base fee on the I don't see a need for Maximum Compute Unit Limit, at least not as something other than implementation detail used by a validator when deciding how to pack blocks, because of the arguments I just made about validator motivations for producing widely-replayable blocks. Validators are incentivized to keep track of what the cluster appears to be able to handle in terms of max CU and self-limit to that. I do agree with governance being used to set base fee. |
A majority that can increase overall performance by increasing CU and tx counts consistently enough that their blocks are confirmed isn't "faulty" in my opinion -- it's pushing the performance envelope and demanding that slower nodes improve to keep up. I think that's what we should want to happen. Just remember that Solana is a non-sharded block chain. The only way to increase overall throughput is to increase the average performance of nodes. I don't like the idea of creating mechanisms to reduce performance increase pressure on slower nodes. |
|
I'm casting my vote against burning 100% of base fees. My reasons have already been voiced by others, so I won't reiterate the same things that have already been said. |
|
I think that there should be six transaction fee categories:
(1) and (2) probably can be rolled into a single fixed base fee since the byte size of transactions likely only marginally affects the fixed costs of processing them. However I think ideally they'd be separate because aside from complexity of implementation, it would more accurately compensate validators for actual resources used if the two fees were considered separately. All fees except congestion fees should go 50% to the validator, and 50% burned. Congestion fees should be 100% burned (this is to prevent validators from increasing their fee take by artificially increasing congestion). Congestion fees should be based on the ratio of "CU of most recent N blocks" to "CU of most recent K blocks", where N is a number like 8, and N is a number like "number of blocks in an epoch". Base fees, account access fees, and per-CU fees should be periodically adjusted by governance. It should be obvious that CU fees are declared by the user as "maximum CU being paid for", and that since validators have to schedule assuming all CU will be used, the fee has to be charged as if all CU were used (i.e. no refunds for unused CU). And it should also be obvious that the moment that tx processing would exceed paid-for CUs, the tx is aborted (but of course, CU fee still charged). Finally, validators should prioritize tx based on revenue from the tx (i.e. (0.5 * (base_byte_and_account_fees + CU fees + priority fee))) divided by (base_byte_and_account_fees + CU fees), because (base_byte_and_account_fees + CU fees) represents the expected cost of processing the tx. Maximizing for the sum of (revenue / costs) across all tx gives the validator maximum possible revenue. Finally finally: it could also be valuable to charge CU fees on an increasing scale, so that every additional CU costs say 1.0001 times the previous CU. This would encourage efficient txs. The CU required for a transaction always has a lower limit (the lowest number of CU that can be used to accomplish the tx), and an increasing CU cost per CU would encourage finding that lower limit. In effect this charges for "wasting block space". The same technique could be used for "byte fee" to encourage efficiently packed transactions. Same for account access (probably even more aggressively though) to discourage expensive tx that lock lots of accounts. |
|
Congestion fees being fully burned makes sense to me. It'll be in the best interest of validators to keep block cu limits higher then. They can prevent any one market from increasing congestion costs too much by decreasing the account compute limits --- increasing the need to use priority fees for a particular hotspot/market.. |
|
@bji 1-4 are rolled up into CU fees. the transaction base fee = TX CUs * base rate
I don't understand this part. The MAX CU limit is a global constant. congestion is based of what percentage of the MAX is utilized. it doesn't matter what the historical average was.
why not priority fees going to the validator? the current leader is doing the majority of the work of transaction scheduling. At a gut level it feels like they should capture most of the rewards there. I think it's worth separating out the economics of the burn splits from the dynamic fees to deal with congestion from the proposal. |
What is the current reason to burn 50% of all fees btw? The main advantage I see for burning 50% of priority fees is that it prevents the leader validator from using an egregious amount of priority for their own transactions and beating out all possible competitors (they just get back all the priority). Their transactions may be inefficient/wasteful and there's not much cost on their part -- I imagine base fees will be quite low usually. Other than that, more burn may also help with an investment narrative which validators could stand to benefit from as well. I can't really think of another reason to add priority burn really.... I know validators could try and abuse account compute limits (if that is under governance as well which I think would be good) by shrinking them and creating more artificial scarcity to increase priority fee usage. If that can be abused it seems good if non-validators could somehow be compensated. Maybe my reasoning is dumb here. It may make sense that scheduling related fees 100% go to validators but there are a lot of things that validators aren't perfectly compensated for either (excess spam they have to sort through for example) so idk if it makes sense in all cases to reason about it this way. |
|
if 0 was burned then a faulty majority can spam the network for free and increase the cost of verification on all users including the unstaked ones. if 100% was burned, then there is no incentive for block producers to include any txs. Congestion fees have to be burned, otherwise a faulty majority can force them to be high. |
|
Looks like we are hitting block limits occasionally and account limits more often. Thanks to @taozhu-chicago for coming through with the new dashboard. Here's a very short window where the block limit was hit, account limit apparently wasn't, and retries spiked quite high (~40k transactions). There's not enough resolution to see if block limit was full for a full 20 seconds or not. https://metrics.solana.com:3000/d/0n54roOVz/fee-market?orgId=1&from=1671130827600&to=1671130860127 Here's a longer window that occurred in the past day where the 48mil limit was hit quite often within a 20min period. Priority fees spiked quite high https://metrics.solana.com:3000/d/0n54roOVz/fee-market?orgId=1&from=1671101971668&to=1671105260922 |
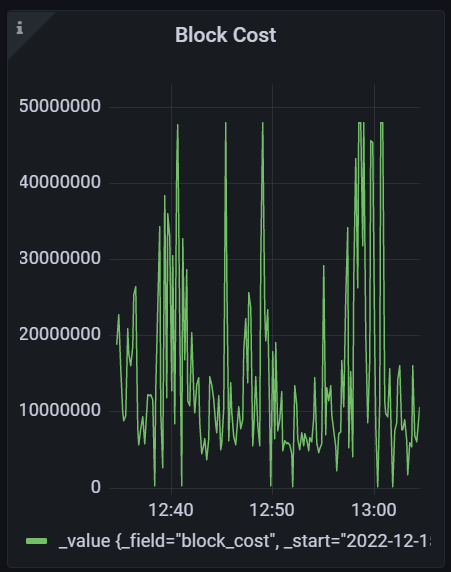
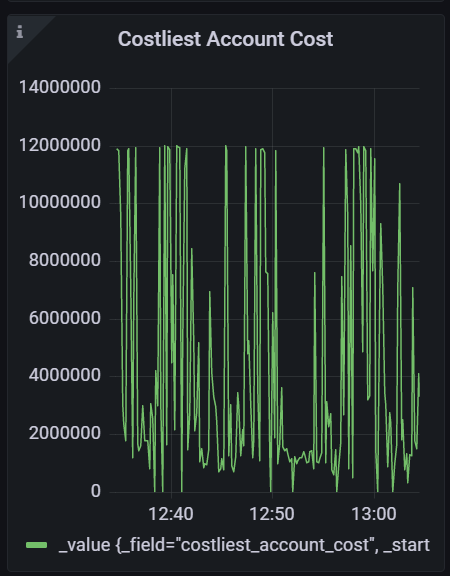
|
priority fees are ~= 50% of the base fees currently. I think burning base fees and letting leaders capture the priority fees wouldn't change the economics too much for validators currently.
the current 50/50 burn is not the worst option, but it is sub optional. Mempools like Jito can offer a prioritization scheme via a side channel that avoids the burn. A user then has the option of paying the priority fee of 0.1 sol or paying jito's validator directly 0.75 sol. The jito validator will earn 0.05 sol from the standard 50/50 priority fee, but 0.75 sol from the jito side channel. The jito path allows the user and validator to split the burn between themselves. |
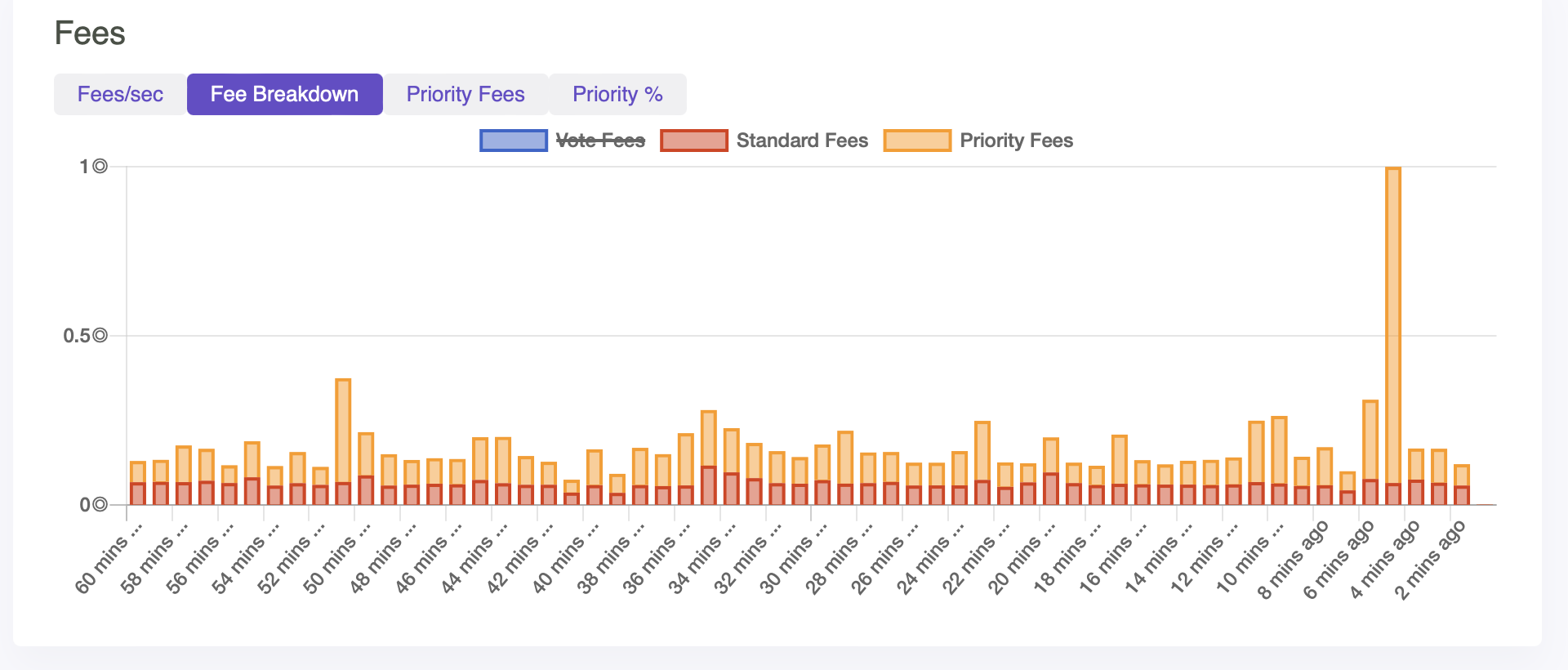
Why not just keep base fees 50% but have the congestion fees 100% like @bji mentioned? Base fees 50% to validators incentivizes adding more compute like Zan mentioned. Validators also dont get 100% of Jito fees --- 8% commission take for validators is the social norm as of now. The native batch auctions with 50% burn in the future would be ideal here... validators get weirdly strong power when they can bid super high priority without any penalty. Would votes be treated differently here? On a side note, vote fees are a bit of a weird ponzi scheme where much of the network's validators are bearing the costs there and it shouldn't just be considered a pure network revenue source. |
Yes and I'm saying that rolling them up is a mistake. The ideal would be if every tx paid exactly what it cost the network to process it. While we can never reach that ideal, we can do better the more fee categories we can identify and make the price of a tx match as accurately as possible the cost of processing it. Of course too many categories gets too confusing, so there is a limit. Combining base + byte fees is a reasonable compromise I think; but combining all 4 fee types into one is I think too imprecise.
Yeah I'm not sure that part of my comment makes any sense at all. I will revisit and revise as necessary.
Sorry priority fees also should go 100% to validator. Maybe I wasn't clear about that.
In a scenario where 100% base fees are burned, all tx will need to include a priority fee otherwise the validator will not process them, assuming validators refuse to work for free. So burning 100% of base fees is really just a play for more deflationary fee burn. The 50% of fees that used to go to the validator and are now burned under 100% base fee burn, are replaced by a new floor on priority fees. I'm not averse to more deflationary fee burn. I guess that I've now landed on being neutral on the 100% base fee burn vs. 50% base fee burn issue. It's just a question of how much deflationary burn is desired, and I really don't have an opinion either way on that. |
I agree with this but requiring priority fees is going to make a whole bunch of existing code obsolete. Any transaction author (wallet, defi app, other app, whatever) that doesn't include priority fees is going to suddenly become unable to submit tx that land. That will be very disruptive. How about this: make base fee burn % something that is either controlled by governance, or increases from 50% to 100% on a schedule (say 1% per epoch for the next 50 epochs). This will be less disruptive as it will allow the shift from base fee to priority fee to happen gradually. |
| @@ -0,0 +1,164 @@ | |||
| --- | |||
| simd: '0003' | |||
There was a problem hiding this comment.
Update the SIMD number to 0004 here as per the SIMD-0001 numbering spec.
Also, please update the filename to 0004-dynamic-compute-unit-base-fee.md
|
Block space is really starting to fill up now (see below). For choosing base fees, how about a system where validators adjust the base fee per cu (to track fiat/sol prices which hardware and bandwidth are denominated in). The way this could work is that the validator set can have a few options each epoch --- to adjust base fee per cu up by 5%, 0%, or decrease by 5% -- something like that. You'd need 80% quorum or so to have it adjusted (?). If it doesn't reach quorum for an epoch then it just stays the same. |
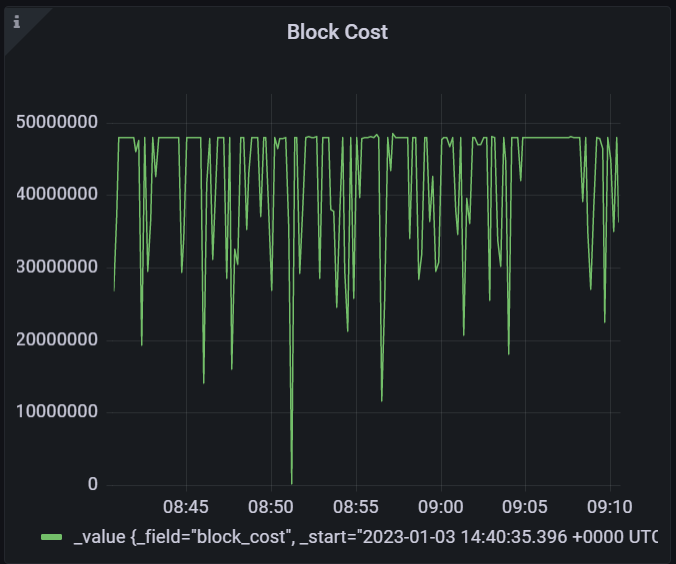
|
Any movement on this? I don't have much to add other than I think it's too important of a change to die on the vine without a resolution of the conversations above even if the proposal is ultimately not approved. |
|
Hey @aeyakovenko. As per SIMD-1, this SIMD is now stagnant and to be closed. There's a lot of good discussion here, but is this even being still considered? cc @taozhu-chicago |
|
There are continued effort in the areas of this topic, Similar to SIMD-0017, it might benefit all if we go back to smaller group discussion. Would you agree @aeyakovenko ? |
|
This SIMD has been inactive for 6 months. The status changed to Stagnant per current SIMD process. Close it for now, but feel free to reopen with new updates if still relevant, or create a new SIMD as needed. |
Problem
Network doesn't have a mechanism to target a healthy load, resulting in two potential performance degradation attack vectors. At 100% heterogenous hardware doesn't have uniform performance resulting in general performance degradation with downstream effects on block producers. Without a dynamic base fee, a faulty majority can stuff blocks with 100% load making verification for non validating nodes unnecessarily expensive.
Solution
Allow the base fee to be dynamically modified based on average load with a target of 50% full blocks.