{kind=link}
This is not the traditional CRUD API you're used to. What this repo does is scrape items from sites like Ruby Conferences and turns the data into JSON. Built with free time, it doesn't make sense hosting this on Heroku for $14/month. I'm currently looking for a free host.
There are only two background jobs that do all the work, one to scrape content and the other to for past events and remove them:
The ScrapeEventsJob scrapes for data. The RetireEventJob checks and removes past events from the /events endpoint.
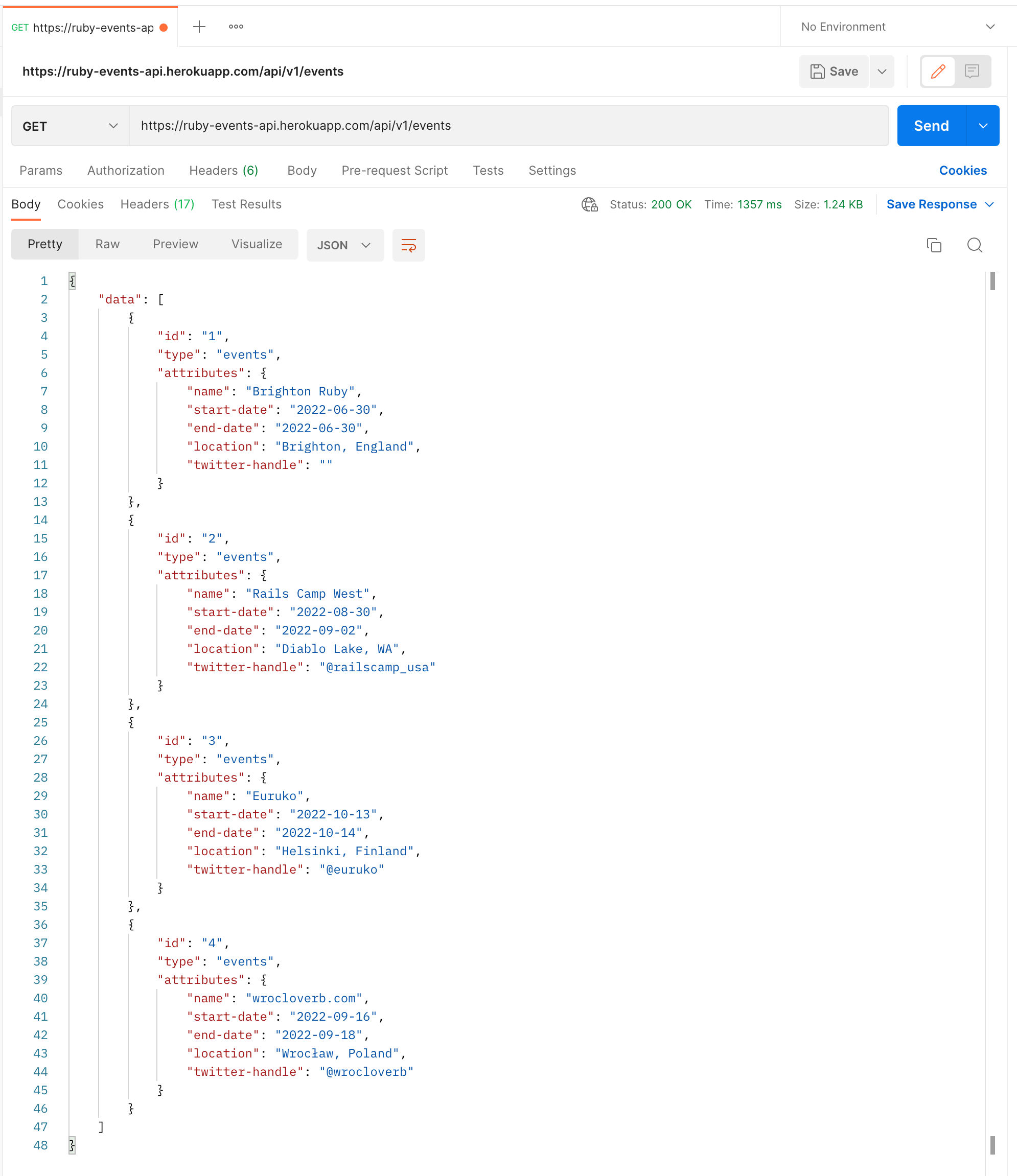
After cloning the project, you should run bundle then do rails db: create db:migrate followed by rails s. The background job to fetch data should be run in a separate process with bundle exec good_job start. You can modify the cron schedule at initializers/good_job.rb to a more frequent scraping schedule to see some data at the end localhost:3000/api/v1/events endpoint.