PyTorch Implementation of MADDPG from Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments (Lowe et. al. 2017)
- OpenAI baselines, commit hash: 98257ef8c9bd23a24a330731ae54ed086d9ce4a7
- My fork of Multi-agent Particle Environments
- PyTorch, version: 0.3.0.post4
- OpenAI Gym, version: 0.9.4
- Tensorboard, version: 0.4.0rc3 and Tensorboard-Pytorch, version: 1.0 (for logging)
The versions are just what I used and not necessarily strict requirements.
All training code is contained within main.py. To view options simply run:
python main.py --help
In this task, the two blue agents are rewarded by minimizing the closest of their distances to the green landmark (only one needs to be close to get optimal reward), while maximizing the distance of the red adversary from the green landmark. The red adversary is rewarded by minimizing it's distance to the green landmark; however, on any given trial, it does not know which landmark is green, so it must follow the blue agents. As such, the blue agents should learn to deceive the red agent by covering both landmarks.
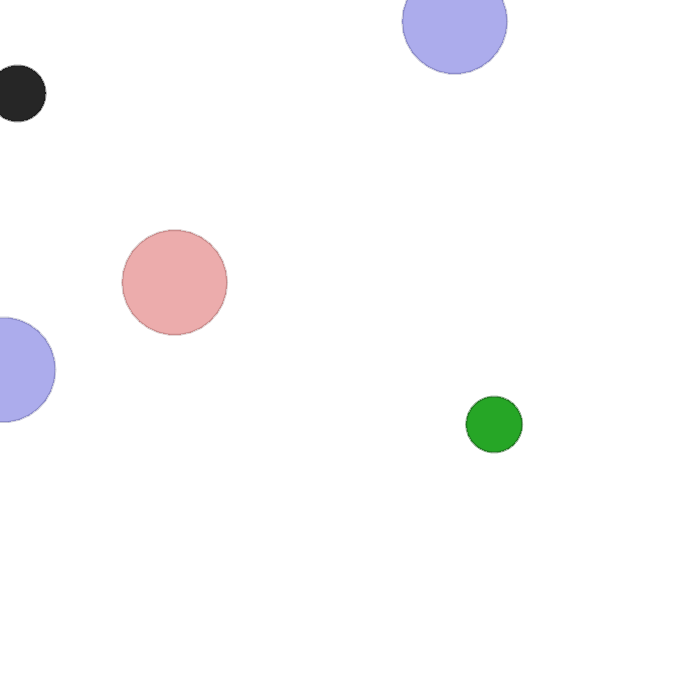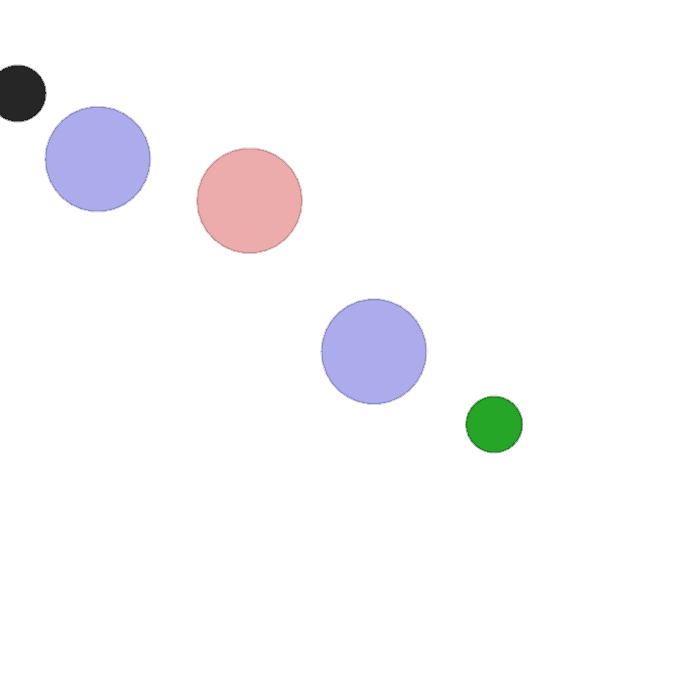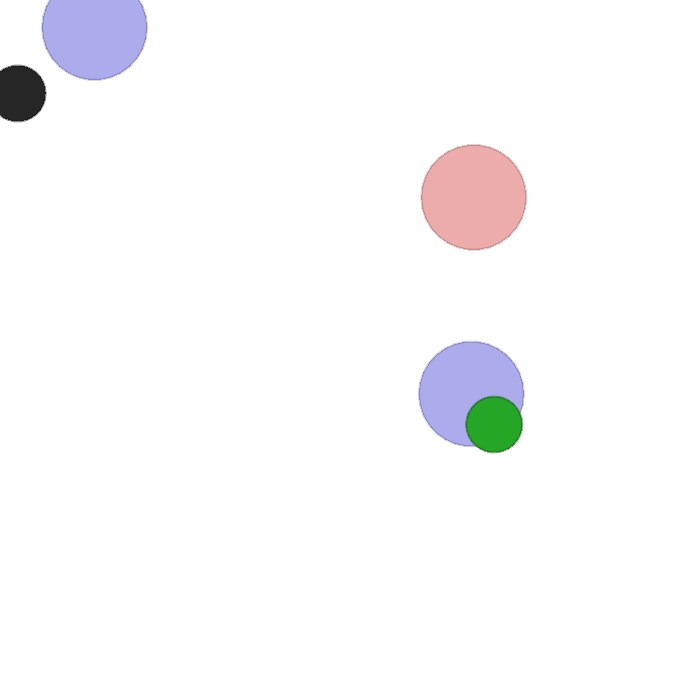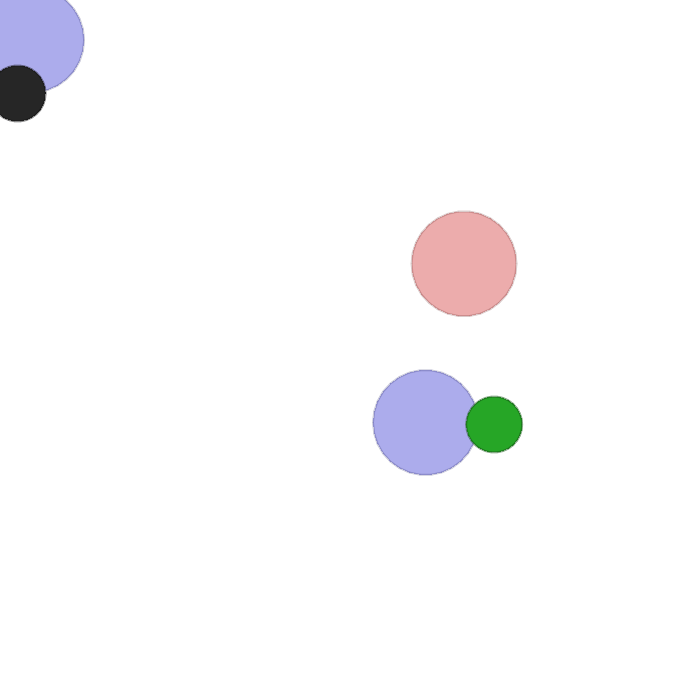


This task involves two agents, one that is stationary and one that can move. The stationary agent sees the color of the other agent as its observation, and outputs a one-hot communication vector as its action. The moving agent receives the communication vector, as well as its relative distance to all landmarks on the screen; however, it does not know its own color. The goal of both agents is for the moving agent to reach the landmark that matches its own color. Thus, the agents must learn to communicate such that the moving agent knows where to go on each randomized trial.



This task involves a single prey agent (in green) and a team of three predators (in red). The prey agent is 30% faster than the predators, so the predators must learn how to team up in order to catch the prey.
In the trials below, the prey agent uses DDPG as its learning algorithm.



There are a few items from the paper that have not been implemented in this repo
- Ensemble Training
- Inferring other agents' policies
- Mixed continuous/discrete action spaces
The OpenAI baselines Tensorflow implementation and Ilya Kostrikov's Pytorch implementation of DDPG were used as references. After the majority of this codebase was complete, OpenAI released their code for MADDPG, and I made some tweaks to this repo to reflect some of the details in their implementation (e.g. gradient norm clipping and policy regularization).