Fix broken pipe callback #4513
Fix broken pipe callback #4513
Conversation
|
I also found |
|
Can one of the admins verify this patch? |
|
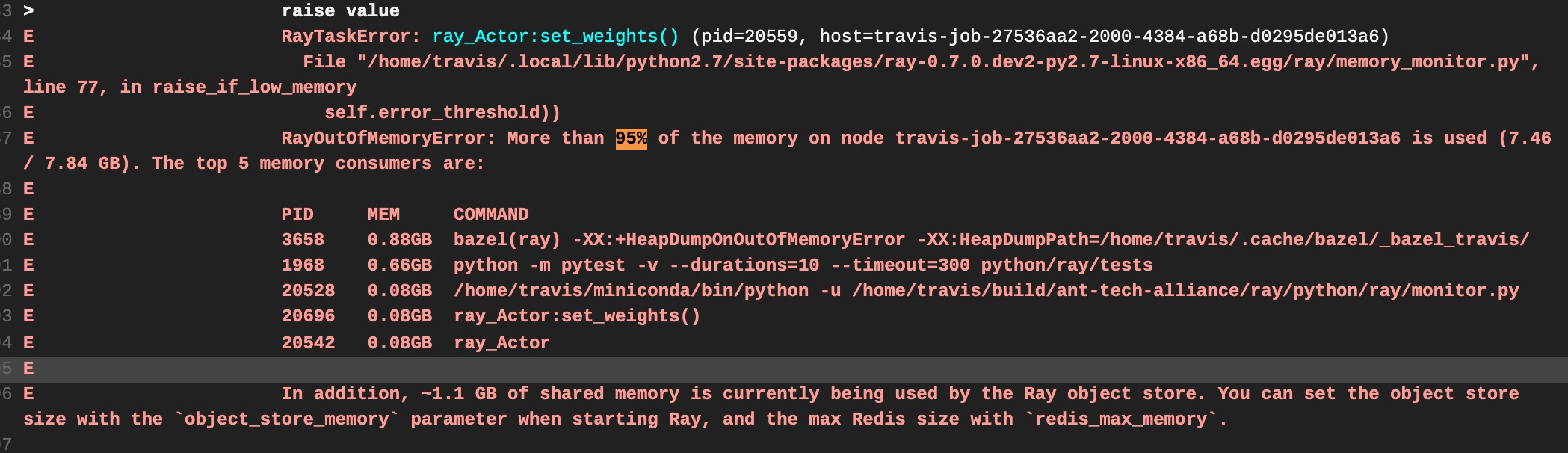
Test FAILed. |
src/ray/common/client_connection.cc
Outdated
| }; | ||
|
|
||
| if (async_write_broken_pipe_) { | ||
| // The connection is not healthy and the heartbeat is not timeout yet. |
There was a problem hiding this comment.
Let's also comment this:
Call the handlers directly. Because writing messages to a connection with broken-pipe status will result in
the callbacks never being called.
| fractional_pair_it->second -= 1; | ||
| if (fractional_pair_it->second < 1e-6) { | ||
| fractional_ids_.erase(fractional_pair_it); | ||
| } |
There was a problem hiding this comment.
Not too sure if this is what we want. @robertnishihara could you also take a look at this part?
There was a problem hiding this comment.
After reading more about this, I think this fix is correct.
I'm surprised that bazel is using the most memory. Shouldn't bazel already finish when we start running tests? |
It seems that we need to explicitly call @guoyuhong could you try adding Line 169 in 0d94f3e |
|
@raulchen |
|
Though |
|
Test FAILed. |
|
Test FAILed. |
|
I also fix some other problematic tests with #4535. Hopefully CI will be more stable. |
| } else { | ||
| RAY_CHECK(fractional_pair_it->second < 1); | ||
| fractional_pair_it->second += fractional_pair_to_return.second; | ||
| RAY_CHECK(fractional_pair_it->second <= 1); |
There was a problem hiding this comment.
This should probably be RAY_CHECK(fractional_pair_it->second < 1 + std::numeric_limits<double>::epsilon());
I believe @romilbhardwaj is making this change in #4555.
However, all of the imprecision is just a temporary solution. There are too many places that we'd have to add epsilon in order to make things correct. @williamma12 is working on a solution that simply makes the fractional resource bookkeeping exact (instead of approximate) by using integers instead of doubles (where the integer can represent 1/1000th of a resource).
There was a problem hiding this comment.
The problem in this case isn't precision. The problem is that the remaining value and returned value can add up to be larger than 1. E.g., returning 0.3 to existing 0.8 will be 1.1 in total.
There was a problem hiding this comment.
Yes, @raulchen is right. From my observation in test_actor.py::test_resource_assignment, there will be 1.1 which is generated by adding 0.2 to 0.9.
There was a problem hiding this comment.
@raulchen @guoyuhong that shouldn't be possible. If that happens, then it is a bug.
Each fractional resource corresponds to a specific resource ID. Suppose there are two GPUs with IDs 0 and 1, and suppose there are two tasks that require 0.2 and 0.9 GPUs.
- The raylet starts with (ID1, 1), (ID2, 1).
- The first task gets scheduled, so the raylet has (ID1, 0.8), (ID2, 1), and the first worker has (ID1, 0.2).
- The second task gets scheduled, so the raylet has (ID1, 0.8), (ID2, 0.1), the first worker has (ID1, 0.2) and the second worker has (ID2, 0.9)
- The first task finishes, so the raylet has (ID1, 1), (ID2, 0.1), and the second worker has (ID2, 0.9)
- The second task finishes, so the raylet has (ID1, 1), (ID2, 1)
We won't add the 0.2 and the 0.9 together because they correspond to different IDs. It isn't possible for one worker to have (ID1, 0.2) and another worker to have (ID1, 0.9) because the total quantity of a given ID is 1.
Does my notation make sense?
There was a problem hiding this comment.
@robertnishihara Thanks for the information. I looked at the code again. The resource_id is int64_t not a string. I may misunderstand the code. I run the test several time and cannot repro the case that adding 0.2 to 0.9, which is strange.
Sorry to this bad change. Shall I revert the change or this will be fixed in #4555 by @romilbhardwaj?
|
Thanks @guoyuhong! I've been able to reproduce the failure |
What do these changes do?
Broken Pipestatus, say don't 'send' message when the status isBroken Pipe. If we continue to send message, the callback won't get called.test_multi_node_2.py:: test_worker_plasma_store_failureby killing reporter when running in Python3.test_component_failures.py::test_plasma_store_failedby reducing the node from 4 to 2. This test passes in my local envs, but it may be two heavy for travis machines.test_actor.py::test_resource_assignmentby refine scheduling_resources.cc. The test fails when there is 0.9 GPU and 0.2 GPU is returned. 1.1 GPU will make the check fail. Furthermore, it not right to compare a double number to int number. The crash in the test is as follows (the actual number offractional_pair_it->secondis 1.1 and the released resource is 0.2):Related issue number