{kind=link}
This project is a text classification system for categorizing disaster relief types. For a message that mentions disaster relief, the system tries to identify the proper types of responses that are required. The classification model is a GradientBoostingClassifier trained on tfidf and message statistic features.
git clone https://github.com/qiaochen/TextClsApp
cd TextClsApp
pip install -r requirements.txt
cd data
python process_data.py disaster_messages.csv disaster_categories.csv DisasterResponse.db
This will produce the database DisasterResponse.db (You may rename the database name as you like, but remember to change the app/run.py file accordingly).
cd models
python train_classifier.py ../data/DisasterResponse.db classifier.pkl
It may take a long time, and end with the trained model classifier.pkl (You may rename the model name as you like, but remember to change the app/run.py file accordingly).
cd app
python run.py
This will start the web server.
In a new web browser window, type in the following url and press enter:
http://0.0.0.0:3001/
You will see the frontpage of the webapp. Type in a sentence in the input bar, and click the Classify Message button, the server will redirect you to the calssification result page.
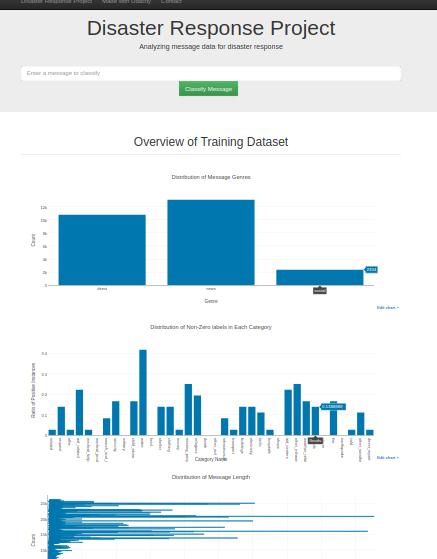
This project consists of three components:
Implemented in process_data.py.
- Loads the messages and categories datasets
- Merges the two datasets for model training and testing
- Cleans the data
- Stores the cleaned data in a SQLite database
Implemented in train_classifier.py.
- Loads data from the SQLite database
- Splits the dataset into training and test sets
- Builds a text processing pipline
- Builds a machine learning pipeline incorporates feature extraction and transformation
- Trains and tunes a model using GridSearchCV
- Outputs results on the test set
- Exports the final model as a pickle file
- The web app that visualizes the statistics of the dataset
- Responds to user input and classify the message
- Display the classification result
- app
| - template
| |- master.html # main page of web app
| |- go.html # classification result page of web app
|- run.py # Flask file that runs app
- data
|- disaster_categories.csv # data to process
|- disaster_messages.csv # data to process
|- process_data.py # program that processes data
|- DisasterResponse.db # database to save clean data to
- models
|- train_classifier.py # program that trains the classification model
|- feature_extractor.py # class and functions for nlp and extracting features
|- classifier.pkl # saved model
- README.md